深入了解 Linux 文件系统中的 inode
Linux 文件系统的核心在于 inode(索引节点),这是文件系统内部运作的关键组件,但常常被用户所误解。本文将详细解释 inode 的概念、作用及其工作原理。
文件系统的基本构成
文件系统的基本职责是存储文件和目录。文件被组织在目录中,而目录又可以包含子目录。为了管理这些文件和目录,文件系统需要记录每个文件的位置、名称、所属用户、权限等信息。这些描述数据的数据被称为元数据。
在 Linux 中,例如 Ext4 文件系统,inode 和 目录结构 协同工作,为每个文件和目录存储所有必要的元数据。这些元数据被内核、用户应用程序以及 ls、stat 和 df 等 Linux 实用程序所使用。
inode 与文件系统大小
文件系统不仅仅需要几个 inode 和目录结构,实际上,每个文件和目录都需要一个 inode,并且每个文件都位于某个目录中,因此也需要一个目录结构。目录结构有时也被称为目录项(dentry)。
每个 inode 都有一个唯一的 inode 编号,这个编号在同一文件系统中是独一无二的。不同的文件系统可以使用相同的 inode 编号。文件系统 ID 和 inode 编号的组合才能在整个 Linux 系统中唯一标识一个文件或目录。
值得注意的是,在 Linux 中,我们不是挂载硬盘驱动器或分区,而是挂载分区上的文件系统。因此,您可能在不知情的情况下使用了多个文件系统。如果您的系统有多个硬盘驱动器或分区,则它们通常对应不同的文件系统,即便它们都是相同的类型(例如 Ext4),它们也是不同的文件系统。
所有的 inode 都存储在一个表中。通过 inode 编号,文件系统可以快速计算出 inode 在 inode 表中的偏移量。这就是为什么 inode 中的 “i” 代表索引的原因。
inode 编号通常被声明为一个 32 位无符号长整型,最大值为 2^32,即 4,294,967,295,这意味着理论上可以存在超过 40 亿个 inode。
但实际上,ext4 文件系统中的 inode 数量是在文件系统创建时确定的,默认情况下,每 16KB 的文件系统容量分配一个 inode。目录结构则是在文件系统使用过程中动态创建的,当文件和目录被添加到文件系统时。
您可以使用 df 命令来查看文件系统中 inode 的使用情况。使用 -i 选项可以让 df 命令显示 inode 的使用信息。例如,要查看第一个硬盘驱动器上第一个分区上的文件系统信息,可以输入以下命令:
df -i /dev/sda1

输出结果会显示:
| 文件系统: | 被报告的文件系统。 |
| Inodes: | 此文件系统中的 inode 总数。 |
| IUsed: | 正在使用的 inode 数量。 |
| IFree: | 剩余可用的 inode 数。 |
| IUse%: | 已使用 inode 的百分比。 |
| Mounted on: | 此文件系统的挂载点。 |
在这个例子中,我们只使用了 10% 的 inode。文件通常以磁盘块的形式存储在硬盘上,每个 inode 指向存储文件内容的磁盘块。如果存在大量小文件,可能会在磁盘空间耗尽之前用完 inode。然而,这种情况很少发生。
过去,一些将电子邮件存储为单独文件的邮件服务器,常常因为大量小文件而遇到 inode 耗尽的问题。但当这些应用程序改为使用数据库后端后,问题得到了解决。对于普通的家庭系统,inode 耗尽的情况并不常见。并且,使用 ext4 文件系统时,在不重新安装文件系统的情况下无法添加更多的 inode。
您可以使用 blockdev 命令来查看 文件系统中磁盘块的大小,命令如下:
sudo blockdev --getbsz /dev/sda

在本例中,磁盘块的大小为 4096 字节。
接下来,我们可以使用 -B 选项指定块大小为 4096 字节,并查看常规磁盘使用情况:
df -B 4096 /dev/sda1

此输出结果显示:
| 文件系统: | 被报告的文件系统。 |
| 4K-blocks: | 此文件系统中 4KB 块的总数。 |
| 已使用: | 正在使用多少个 4KB 块。 |
| 可用: | 可用的剩余 4KB 块的数量。 |
| Use%: | 已使用的 4KB 块的百分比。 |
| Mounted on: | 此文件系统的挂载点。 |
在本例中,文件存储(包括 inode 和目录结构的存储)占用了文件系统上 28% 的空间,而 inode 的使用率为 10%,因此系统处于良好的状态。
inode 元数据
可以使用 ls 命令和 -i 选项来查看文件的 inode 编号,如下所示:
ls -i geek.txt

这个文件的 inode 编号是 1441801,这个 inode 中存储着该文件的元数据,以及指向文件数据所在的磁盘块的指针。如果文件是碎片化的或者非常大,inode 指向的某些块可能会包含更多指向其他磁盘块的指针,这些块也可能包含指向另一组磁盘块的指针。这种方法有效地解决了 inode 固定大小和只能保存有限数量磁盘块指针的问题。
现在,有一种名为 “范围” 的新方案取代了之前的做法。范围记录存储文件的每组连续块的起始块和结束块。如果文件是非碎片化的,只需要存储第一个块和文件长度。如果文件是碎片化的,则需要存储文件每个部分的起始和结束块。这种方法更高效。
您可以通过查看 inode 内部来确定文件系统是否使用了磁盘块指针或范围。可以使用带有 -R 选项的 debugfs 命令,并将要查看的文件的 inode 传递给它。debugfs 将使用其内部的 “stat” 命令来显示 inode 的内容。由于 inode 编号只在文件系统中唯一,所以还需要告诉 debugfs inode 所属的文件系统。
sudo debugfs -R "stat" /dev/sda1

debugfs 命令会从 inode 中提取信息,并在 less 中呈现出来:
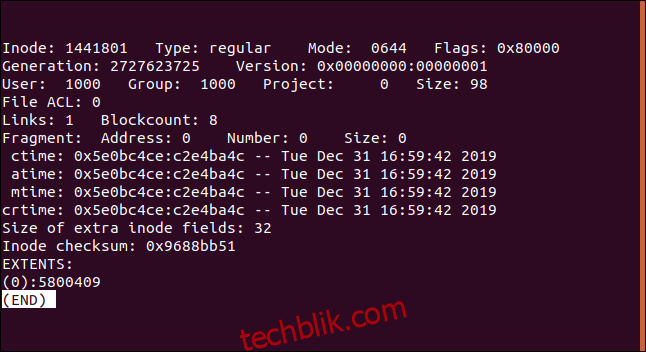
以下是一些重要的信息:
| Inode: | 我们正在查看的 inode 的编号。 |
| 类型: | 表明这是一个普通文件,而不是目录或符号链接。 |
| 模式: | 文件权限的八进制表示形式。 |
| 标志: | 表示不同的特征或功能。0x80000 表示 “范围” 标志。 |
| 世代: | 网络文件系统 (NFS) 在通过网络访问远程文件系统时使用此字段。 inode 和代号充当文件句柄的形式。 |
| 版本: | inode 的版本。 |
| 用户: | 文件的所有者。 |
| 组: | 文件的组所有者。 |
| 项目: | 应始终为零。 |
| 大小: | 文件的大小。 |
| 文件 ACL: | 文件的访问控制列表,用于向不在所有者组中的人授予访问权限。 |
| 链接: | 指向文件的 硬链接 数量。 |
| Blockcount: | 分配给该文件的硬盘空间量,以 512 字节块为单位。 |
| 碎片: | 表示此文件是否碎片化。(这是一个过时的标志。) |
| Ctime: | 文件创建的时间。 |
| Atime: | 上次访问此文件的时间。 |
| Mtime: | 上次修改此文件的时间。 |
| Crtime: | 文件创建的时间。 |
| 额外 inode 字段的大小: | ext4 文件系统引入的额外字节数,用于存储扩展属性或为未来的内核需求做准备。 |
| Inode 校验和: | inode 的校验和,用于检测是否损坏。 |
| 范围: | 如果使用了范围(在 ext4 上,默认情况下使用),则此字段会记录文件数据所在硬盘块的起始和结束块。 |
文件名在哪里?
尽管我们已经了解了文件的许多信息,但并没有找到文件名。文件名存储在目录结构中。在 Linux 中,目录也像文件一样拥有一个 inode。但是,目录的 inode 指向的是包含目录结构的磁盘块,而不是文件的数据块。
与 inode 相比,目录结构包含 关于文件信息的有限集合。目录结构只保存文件的 inode 编号、名称和名称的长度。
inode 和目录结构包含了您需要了解的有关文件或目录的所有信息。目录结构位于目录磁盘块中,这样我们知道文件所在的目录。目录结构提供文件名和 inode 编号。inode 则提供了文件的所有其他信息,例如时间戳、权限以及文件数据在文件系统中的位置。
目录的 inode
您可以像查看文件一样轻松查看目录的 inode 编号。
以下示例使用 ls 命令的 -l (长格式)、-i (inode) 和 -d (目录) 选项来查看工作目录:
ls -lid work/

由于使用了 -d (目录) 选项,ls 命令显示目录本身,而不是目录的内容。此目录的 inode 编号是 1443016。
要查看主目录的 inode,可以输入以下命令:
ls -lid ~

主目录的 inode 编号是 1447510。工作目录位于主目录中。现在我们看一下工作目录的内容。使用 -a (全部) 选项,而不是 -d (目录) 选项,会显示通常被隐藏的目录项:
ls -lia work/
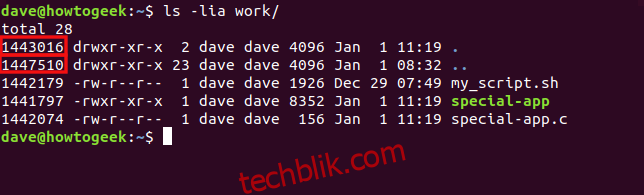
使用 -a (all) 选项后,会显示单点 (.) 和双点 (..) 条目。单点条目代表目录本身,双点条目代表父目录。
单点条目的 inode 编号是 1443016,与工作目录的 inode 编号相同。双点条目的 inode 编号与主目录的 inode 编号相同。
这就是为什么可以使用 cd .. 命令在目录树中向上移动一级的原因。当在应用程序或脚本名称前添加 ./ 时,shell 会知道从哪里启动应用程序或脚本。
inode 和链接
一个格式良好且可访问的文件需要三个组件:文件、目录结构和 inode。文件是存储在硬盘上的数据,目录结构包含文件的名称及其 inode 编号,而 inode 则包含文件的所有元数据。
符号链接是一种特殊的文件系统条目,看起来像文件,但实际上是指向现有文件或目录的快捷方式。让我们看看它们是如何工作的。
假设我们有一个包含两个文件的目录,一个是脚本,另一个是应用程序,如下所示:
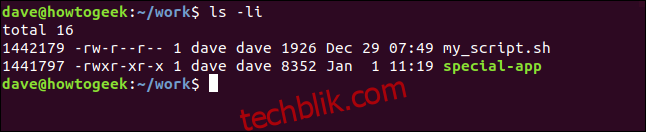
可以使用 ln 命令和 -s(符号)选项来 创建一个指向脚本文件的软链接,命令如下:
ln -s my_script.sh geek.sh

我们创建了一个名为 geek.sh 的链接,它指向 my_script.sh。可以使用 ls 命令查看这两个文件:
ls -li *.sh
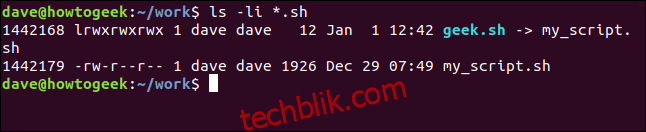
geek.sh 显示为蓝色,表示这是一个链接。权限标志的第一个字符是 ‘l’,箭头 ‘->’ 指向 my_script.sh。这些都表明 geek.sh 是一个符号链接。
不出所料,两个脚本文件具有不同的 inode 编号。更令人惊讶的是,软链接 geek.sh 没有与原始脚本文件相同的用户权限。实际上,geek.sh 的权限更加宽松,所有用户都拥有完全权限。
geek.sh 的目录结构包含链接的名称和它的 inode 编号。当您尝试使用该链接时,它的 inode 会被引用,就像普通文件一样。链接的 inode 指向的磁盘块不包含文件的数据,而是包含原始文件的名称。文件系统会将您重定向到原始文件。
如果删除原始文件,并尝试查看 geek.sh 的内容,会发生什么?
rm my_script.sh
cat geek.sh

符号链接断开,重定向失败。
现在,创建一个指向应用程序文件的硬链接:
ln special-app geek-app

查看这两个文件的 inode:
ls -li
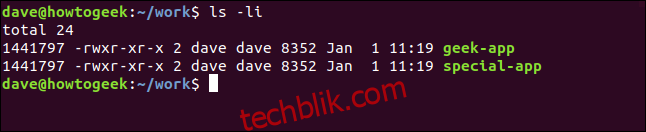
这两个文件看起来都是普通文件。geek-app 没有任何指示表明它是一个链接。此外,geek-app 与原始文件具有相同的用户权限。然而,令人惊讶的是,两个应用程序都具有相同的 inode 编号:1441797。
geek-app 的目录项包含名称 “geek-app” 和一个 inode 编号,而这个编号与原始文件的 inode 编号相同。因此,我们有两个名称不同的文件系统条目,它们都指向同一个 inode。实际上,任意数量的条目都可以指向同一个 inode。
使用 stat 程序 查看目标文件:
stat special-app
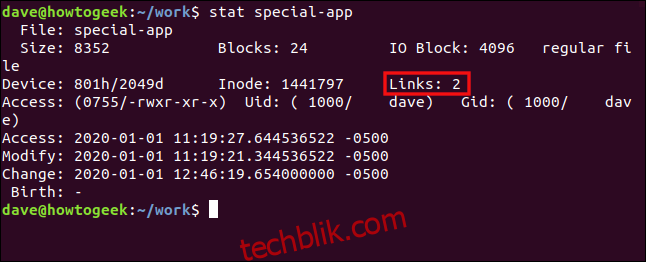
可以看到有两个硬链接指向这个文件。这个信息存储在 inode 中。
现在,删除原始文件并尝试使用带有 安全密码 的链接:
rm special-app
./geek-app correcthorsebatterystaple

令人惊讶的是,该应用程序仍然正常运行。这是因为当您删除文件时,inode 并不会被立即释放重用。目录结构中指向该 inode 的条目会被标记为 inode 编号为零,并且文件数据所在的磁盘块也标记为可以被新的文件数据覆盖。但是,如果指向该 inode 的硬链接数大于 1,则硬链接计数器会减 1,并且被删除文件的目录结构中的 inode 编号设置为零。硬盘上的文件内容仍然可以被现有的硬链接访问。
再次使用 stat 命令查看 geek-app:
stat geek-app
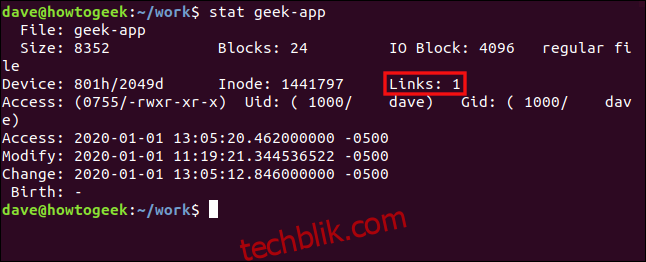
这些详细信息来自与之前的 stat 命令相同的 inode (1441797)。链接计数已减少了一个。
因为现在只有一个指向该 inode 的硬链接,删除 geek-app 将会真正删除该文件。文件系统会释放 inode,并将目录结构标记为 inode 为零。之后,新文件可以覆盖硬盘上的数据存储。
inode 的开销
虽然这个系统非常优雅,但也存在开销。为了读取文件,文件系统必须执行以下步骤:
- 找到正确的目录结构
- 读取 inode 编号
- 找到正确的 inode
- 读取 inode 信息
- 根据 inode 中的链接或范围找到相关的磁盘块
- 读取文件数据
如果数据不连续,则需要进行更多的跳转。
想象一下,ls 命令为了显示一个包含许多文件的长格式列表,必须完成多少工作。需要进行多次文件系统访问才能获取必要的信息。
为了加快文件系统的访问速度,Linux 会尽可能多地进行预读缓存。这很有帮助,但是,如同任何文件系统一样,开销有时是显而易见的。
现在您知道原因了。