深入了解 Apache Kafka:消息流服务详解
Apache Kafka 是一种强大的消息流平台,它使得分布式系统中的各种应用程序能够通过消息传递进行高效的通信和数据共享。它本质上扮演着发布/订阅系统的角色,允许生产者应用程序发布消息,而消费者应用程序则订阅并接收这些消息。
通过采用 Kafka,你可以在系统中实现生产者和消费者之间的松散耦合架构。这种架构不仅简化了系统的设计,也降低了管理的复杂性。Kafka 的核心功能依赖于 Zookeeper 来进行元数据管理,并确保集群中不同组件之间的同步。
Apache Kafka 的关键特性
Apache Kafka 之所以日益普及,得益于它诸多卓越的特性,例如:
- 卓越的可扩展性:通过集群和分区的巧妙设计,轻松应对不断增长的数据量。
- 惊人的速度:每秒可处理高达 200 万次的写入操作,满足高吞吐量需求。
- 消息顺序保证:严格维护消息发送的顺序,确保数据处理的准确性。
- 高度的可靠性:通过副本机制确保数据的安全可靠,降低数据丢失风险。
- 无缝升级:支持零停机升级,最大程度地减少对业务的影响。
接下来,我们将深入探讨 Kafka 的一些典型应用场景。
Apache Kafka 的常见应用
Kafka 在多种场景下都发挥着重要作用。例如,它经常被用于处理海量数据、记录和聚合事件(如用于分析的用户点击行为),以及将来自系统各部分的日志集中存储,便于集中管理。
此外,Kafka 还支持系统中不同应用程序之间的通信,并能够实时处理来自物联网设备的数据流。这种灵活性使得 Kafka 成为构建现代数据密集型应用程序的理想选择。
接下来,我们将详细介绍如何在 Windows 和 Linux 系统上安装 Kafka。
在 Windows 上安装 Kafka
在 Windows 上安装 Apache Kafka 之前,首先需要确保你的计算机已安装 Java。 你可以通过在管理员模式下打开命令提示符并输入以下命令来检查 Java 版本:
java --version
如果 Java 已安装,你将看到当前安装的 JDK 版本号。如果收到 “无法识别此命令” 的错误消息,则说明 Java 未安装,需要先进行安装。你可以访问 Adoptium.net 下载并安装 Java。
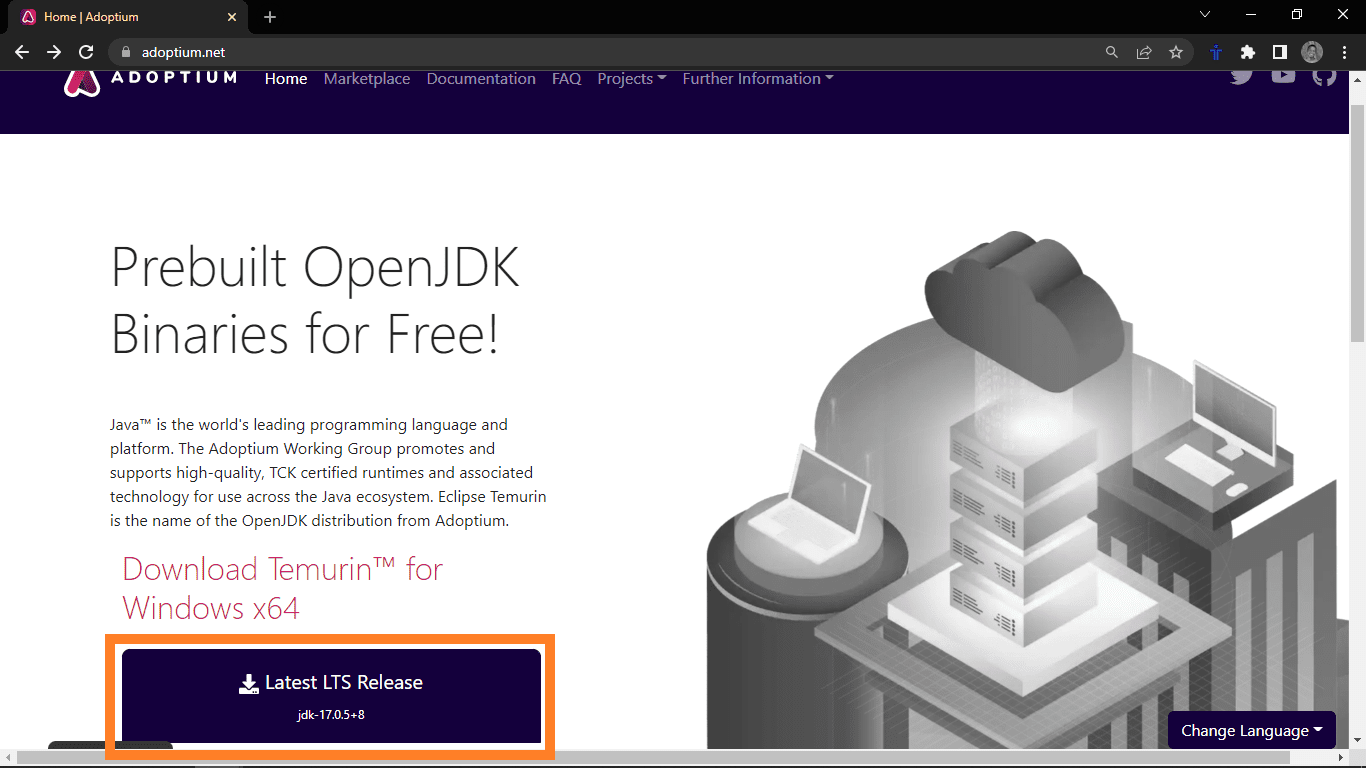
下载 Java 安装程序后,运行该程序,按照安装提示选择默认选项,完成安装过程。安装完成后,再次在管理员模式下打开命令提示符并输入 `java –version` 验证安装结果。
确认 Java 安装成功后,接下来我们可以开始安装 Kafka。首先访问 Kafka 官方网站下载最新版本的二进制文件。

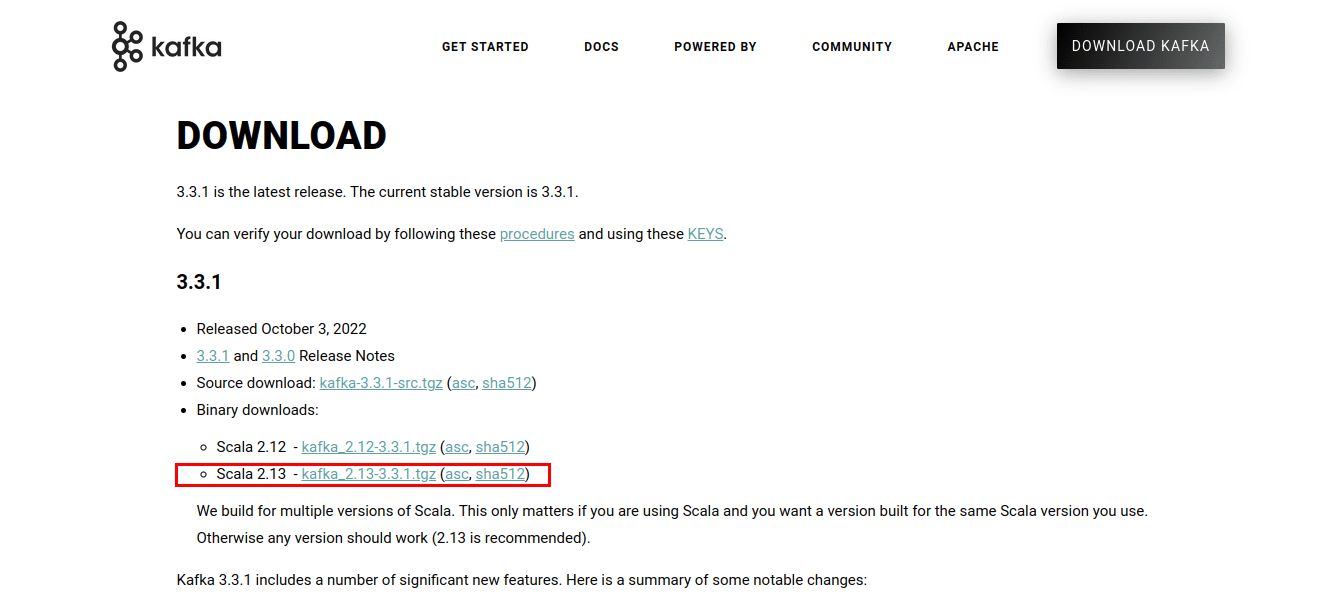
下载的文件通常是 .tgz 格式的压缩包。你需要使用解压缩工具(如 WinZip)将其解压。解压后,将文件移动到 `C:kafka` 目录。
在管理员模式下打开命令提示符,首先导航到 Kafka 目录,然后启动 Zookeeper 服务器。使用 `zookeeper.properties` 作为配置文件运行 `zookeeper-server-start.bat` 文件。
cd C:kafka binwindowszookeeper-server-start.bat configzookeeper.properties
为了让 Kafka 正常运行,需要在系统 PATH 中添加 wmic 可执行文件的路径:
set PATH=C:WindowsSystem32wbem;%PATH%;
最后,在管理员模式下打开另一个命令提示符窗口,导航到 `C:kafka` 目录,启动 Apache Kafka 服务器:
cd C:kafka
使用 `server.properties` 作为配置文件运行 `kafka-server-start.bat` 文件:
binwindowskafka-server-start.bat configserver.properties
至此,Kafka 服务器应该已经成功运行。你可以通过修改 `server.properties` 文件来自定义服务器的各项属性,如日志文件的存储位置等。
在 Linux 上安装 Kafka
在 Linux 系统上安装 Kafka,首先需要更新系统软件包:
sudo apt update && sudo apt upgrade
接着,检查系统是否已安装 Java:
java --version
如果已安装 Java,会显示版本号。 如果未安装,可以使用以下命令安装默认的 JDK:
sudo apt install default-jdk
安装完 Java 后,可以从官网下载 Apache Kafka 的二进制文件。
打开终端,导航到下载文件的目录(例如,`Downloads` 文件夹):
cd Downloads
使用 `tar` 命令解压下载的压缩包:
tar -xvzf kafka_2.13-3.3.1.tgz
然后,进入解压后的文件夹:
cd kafka_2.13-3.3.1
现在,你可以列出当前目录的文件和文件夹:
进入文件夹后,运行位于 `bin` 目录下的 `zookeeper-server-start.sh` 脚本来启动 Zookeeper 服务器。该脚本需要一个配置文件,默认为 `config` 子目录中的 `zookeeper.properties` 文件:
bin/zookeeper-server-start.sh config/zookeeper.properties
在 Zookeeper 运行后,启动 Apache Kafka 服务器。`kafka-server-start.sh` 脚本也在 `bin` 目录中。它也需要一个配置文件,默认为 `config` 目录中的 `server.properties` 文件:
bin/kafka-server-start.sh config/server.properties
至此,Apache Kafka 服务器应该已经启动。`bin` 目录中包含了许多用于执行各种操作的脚本,例如创建主题、管理生产者和消费者等。你还可以在 `server.properties` 文件中自定义服务器的各种属性。
结语
在本指南中,我们详细介绍了如何在 Windows 和 Linux 系统上安装 Java 和 Apache Kafka。除了手动安装和管理 Kafka 集群外,你还可以选择使用 Amazon Web Services 或 Confluent 等托管服务。这将大大简化 Kafka 的部署和维护。
下一步,你可以深入学习如何使用 Kafka 和 Spark 进行数据处理,进一步提升数据处理能力。