R语言中数据框的详解与创建方法
在R语言中,数据框(DataFrame)是一种基础的数据结构,它为数据分析和操作提供了必要的框架、灵活性以及工具。数据框的重要性不仅体现在统计学和数据科学领域,还延伸到了各个行业的数据驱动决策过程中。
数据框通过提供结构化和组织化的方式,使得解锁数据中的洞见,并以系统且高效的方式做出以数据为依据的决策成为可能。
R语言中的数据框在结构上类似于表格,由行和列组成。每一行代表一个观测值,而每一列则代表一个变量。这种结构化的组织方式使得数据的处理和管理变得更加容易。数据框能够存储多种数据类型,包括数值、文本和日期等,使其在应用中具有极高的通用性。
本文将详细阐述数据框的重要性,并探讨如何使用data.frame()函数创建数据框。
此外,我们将深入研究操作数据的方法,并介绍如何从CSV和Excel文件创建数据框、将其他数据结构转换为数据框,以及如何有效地利用tibble库。
以下是数据框在R语言中至关重要的几个关键原因:
数据框的重要性

- 结构化数据存储:数据框以一种结构化的表格形式存储数据,类似于电子表格。这种结构化格式简化了数据的管理和组织。
- 混合数据类型:数据框可以在同一结构中容纳不同的数据类型。您可以拥有包含数值、字符串、因子、日期等类型的列。这种多功能性在处理实际数据时至关重要。
- 数据组织:数据框中的每一列代表一个变量,而每一行代表一个观察或案例。这种结构化的布局使得理解数据的组织变得容易,从而提高了数据的清晰度。
- 数据导入和导出:数据框支持从各种文件格式(如CSV、Excel和数据库)轻松导入和导出数据。此功能简化了使用外部数据源的过程。
- 互操作性:数据框得到了R语言包和函数的广泛支持,确保了与其他统计和数据分析工具以及库的兼容性。这种互操作性允许无缝集成到R生态系统中。
- 数据操作:R语言提供了丰富的软件包生态系统,其中“dplyr”就是一个突出的例子。这些包使得过滤、转换和汇总数据变得容易。此功能对于数据清理和准备至关重要。
- 统计分析:数据框是R语言中许多统计和数据分析函数的标准数据格式。您可以使用数据框有效地执行回归分析、假设检验以及许多其他的统计分析。
- 可视化:R语言的数据可视化包(如ggplot2)可以与数据框无缝协作。这使得创建信息丰富的图表和图形用于数据探索和交流变得简单。
- 数据探索:数据框通过汇总统计、可视化和其他分析方法促进了数据探索。这有助于分析师和数据科学家理解数据的特征,并检测模式或异常值。
如何在R语言中创建数据框
在R语言中,有多种方法可以创建数据框。以下是一些最常见的方法:
#1. 使用 data.frame() 函数
# 检查并加载必要的dplyr库
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# 设置随机数种子以保证结果的可重复性
set.seed(42)
# 创建一个示例销售数据框,其中包含真实的商品名称
sales_data <- data.frame(
OrderID = 1001:1010,
Product = c("笔记本电脑", "智能手机", "平板电脑", "耳机", "相机", "电视", "打印机", "洗衣机", "冰箱", "微波炉"),
Quantity = sample(1:10, 10, replace = TRUE),
Price = round(runif(10, 100, 2000), 2),
Discount = round(runif(10, 0, 0.3), 2),
Date = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# 显示销售数据框
print(sales_data)
这段代码的具体操作如下:
- 首先,它检查R环境中是否已安装并加载“dplyr”库。
- 如果“dplyr”库不存在,则会安装并加载该库。
- 然后,设置一个随机数种子,以确保结果的可重复性。
- 接下来,使用预先填充的数据创建一个示例销售数据框。
- 最后,在控制台中显示销售数据框以便查看。
 销售数据框
销售数据框
这是在R语言中创建数据框的最简单方法之一。接下来,我们将探讨如何提取、添加、删除以及选择特定的列或行,以及如何汇总数据。
提取列
有两种方法可以从数据框中提取所需的列:
- 可以使用索引来检索R语言中数据框的最后三列。
- 当您想按名称访问特定的列时,可以使用
$运算符从数据框中提取列。
为了节省时间,我们将同时演示这两种方法:
# 使用索引从sales_data数据框中提取最后三列(Discount, Price, Date)
last_three_columns <- sales_data[, c("Discount", "Price", "Date")]
# 显示提取的列
print(last_three_columns)
############################################# OR #########################################################
# 使用$运算符提取最后三列(Discount, Price, Date)
discount_column <- sales_data$Discount
price_column <- sales_data$Price
date_column <- sales_data$Date
# 使用提取的列创建一个新的数据框
last_three_columns <- data.frame(Discount = discount_column, Price = price_column, Date = date_column)
# 显示提取的列
print(last_three_columns)
您可以使用任何一种代码来提取所需的列。
您可以使用多种方法从R语言的数据框中提取行。这里是一个简单的方法:
# 从last_three_columns数据框中提取特定的行(第3、6和9行)
selected_rows <- last_three_columns[c(3, 6, 9), ]
# 显示选择的行
print(selected_rows)
您还可以使用指定的条件来提取行:
# 提取并排列符合指定条件的行
selected_rows <- sales_data %>%
filter(Discount < 0.3, Price > 100, format(Date, "%Y-%m") == "2023-01") %>%
arrange(OrderID) %>%
select(Discount, Price, Date)
# 显示选择的行
print(selected_rows)
 提取的行
提取的行
添加新行
要向R语言的现有数据框中添加新行,可以使用rbind()函数:
# 创建一个新行作为数据框
new_row <- data.frame(
OrderID = 1011,
Product = "咖啡机",
Quantity = 2,
Price = 75.99,
Discount = 0.1,
Date = as.Date("2023-01-12")
)
# 使用rbind()函数将新行添加到数据框
sales_data <- rbind(sales_data, new_row)
# 显示更新后的数据框
print(sales_data)
 添加新行
添加新行
添加新列
您可以使用简单的代码在数据框中添加列。在这里,我想向我的数据中添加“付款方式”列。
# 创建一个新的列"PaymentMethod",并为每一行添加值
sales_data$PaymentMethod <- c("信用卡", "PayPal", "现金", "信用卡", "现金", "PayPal", "现金", "信用卡", "信用卡", "现金", "信用卡")
# 显示更新后的数据框
print(sales_data)
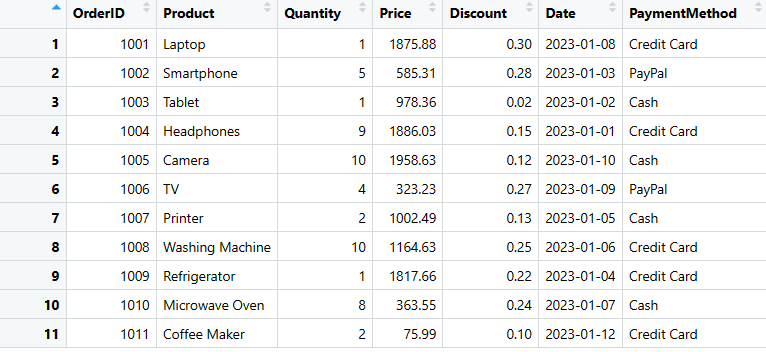 在数据框中添加的列
在数据框中添加的列
删除行
如果您想删除不需要的行,此方法可能会有所帮助:
# 通过OrderID识别要删除的行
row_to_delete <- sales_data$OrderID == 1010
# 使用识别的行来排除它,并创建一个新的数据框
sales_data <- sales_data[!row_to_delete, ]
# 显示删除行后的更新数据框
print(sales_data)
删除列
您可以使用dplyr包从R语言的数据框中删除列。
# 加载 dplyr 包
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# 使用select()函数删除“Discount”列
sales_data <- sales_data %>% select(-Discount)
# 显示没有“Discount”列的更新数据框
print(sales_data)
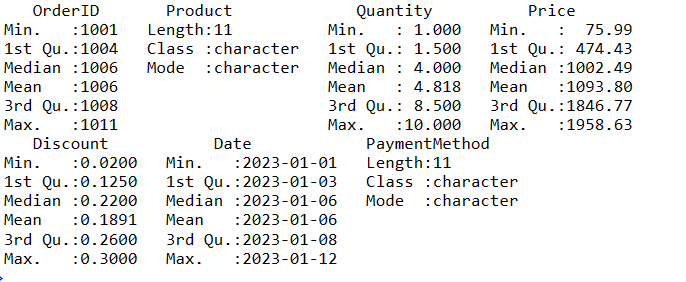
获取摘要
要获取R语言中数据的摘要,可以使用summary()函数。此函数提供了数据中数值变量的集中趋势和分布的快速概览。
# 获取数据的摘要
data_summary <- summary(sales_data)
# 显示摘要
print(data_summary)
您可以按照以上几个步骤来操作数据框中的数据。
让我们继续使用第二种方法来创建数据框。
#2. 从CSV文件创建R数据框
要从CSV文件创建R数据框,可以使用read.csv()函数:
# 将CSV文件读取到数据框中
df <- read.csv("my_data.csv")
# 查看数据框的前几行
head(df)
此函数从CSV文件读取数据并进行转换。然后,您可以根据需要在R语言中使用数据。
# 如果尚未安装,则安装并加载readr包
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# 将CSV文件读取到数据框中
df <- read_csv("data.csv")
# 查看数据框的前几行
head(df)
您可以使用readr包在R语言中读取CSV文件。readr包中的read_csv()函数通常用于此目的。它比常规方法更快。
#3. 使用 as.data.frame() 函数
您可以使用as.data.frame()函数在R语言中创建数据框。此函数允许您将其他数据结构(如矩阵或列表)转换为数据框。
使用方法如下:
# 创建一个嵌套列表来表示数据
data_list <- list(
OrderID = 1001:1011,
Product = c("笔记本电脑", "智能手机", "平板电脑", "耳机", "相机", "电视", "打印机", "洗衣机", "冰箱", "微波炉", "咖啡机"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("信用卡", "PayPal", "现金", "信用卡", "现金", "PayPal", "现金", "信用卡", "信用卡", "现金", "信用卡")
)
# 将嵌套列表转换为数据框
sales_data <- as.data.frame(data_list)
# 显示数据框
print(sales_data)
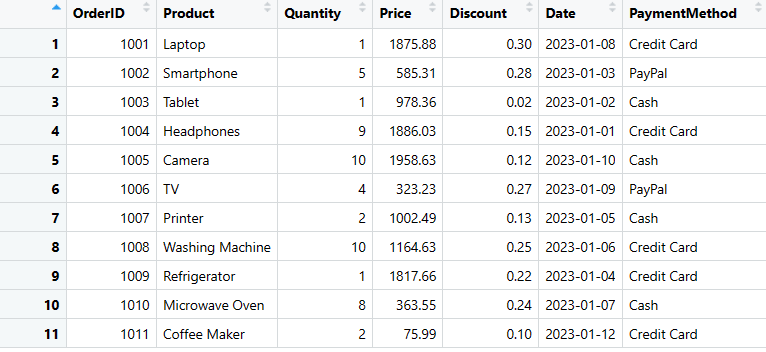 销售数据
销售数据
此方法允许您创建数据框,而无需逐一指定每一列,当您拥有大量数据时,此方法特别有用。
#4. 从现有的数据框
要通过从R语言的现有数据框中选择特定列或行来创建新的数据框,可以使用方括号[]进行索引。它的工作原理如下:
# 选择行和列
sales_subset <- sales_data[c(1, 3, 4), c("Product", "Quantity")]
# 显示选择的子集
print(sales_subset)
在此代码中,我们创建一个名为sales_subset的新数据框,其中包含sales_data中的特定行(1、3和4)和特定列(“Product”和“Quantity”)。
您可以调整行和列的索引以及名称来选择您需要的数据。
 销售_子集
销售_子集
#5. 从向量
向量是R语言中的一维数据结构,由相同数据类型的元素组成,包括逻辑型、整数型、双精度型、字符型、复数型或原始型数据。
另一方面,R语言的数据框是一种二维结构,旨在以包含行和列的表格格式存储数据。有多种方法可以从向量创建R数据框,下面提供了一个这样的示例。
# 为每一列创建向量
OrderID <- 1001:1011
Product <- c("笔记本电脑", "智能手机", "平板电脑", "耳机", "相机", "电视", "打印机", "洗衣机", "冰箱", "微波炉", "咖啡机")
Quantity <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Price <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Discount <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Date <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("信用卡", "PayPal", "现金", "信用卡", "现金", "PayPal", "现金", "信用卡", "信用卡", "现金", "信用卡")
# 使用data.frame()函数创建数据框
sales_data <- data.frame(
OrderID = OrderID,
Product = Product,
Quantity = Quantity,
Price = Price,
Discount = Discount,
Date = Date,
PaymentMethod = PaymentMethod
)
# 显示数据框
print(sales_data)
在此代码中,我们为每一列创建单独的向量,然后使用data.frame()函数将这些向量组合到名为sales_data的数据框中。
这允许您从R语言中的各个向量创建结构化的表格数据框。
#6. 从Excel文件
要在R语言中通过导入Excel文件来创建数据框,可以使用第三方包,如readxl,因为基础R不提供对读取Excel文件的原生支持。read_excel()是读取Excel文件的此类函数之一。
# 加载readxl库
if (!require("readxl")) {
install.packages("readxl")
library(readxl)
}
# 定义Excel文件的文件路径
excel_file_path <- "your_file.xlsx" # 替换为实际的文件路径
# 读取Excel文件并创建数据框
data_frame_from_excel <- read_excel(excel_file_path)
# 显示数据框
print(data_frame_from_excel)
此代码将读取Excel文件,并将其数据存储在R语言的数据框中,从而允许您在R语言环境中使用该数据。
#7. 从文本文件
您可以使用R语言中的read.table()函数将文本文件导入到数据框中。此函数需要两个基本参数:您要读取的文件名和指定如何分隔文件中字段的分隔符。
# 定义文件名和分隔符
file_name <- "your_text_file.txt" # 替换为实际的文件名
delimiter <- "\t" # 替换为实际的分隔符(例如,"\t"表示制表符分隔,","表示CSV)
# 使用read.table()函数创建数据框
data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter)
# 显示数据框
print(data_frame_from_text)
此代码将读取文本文件并在R语言中创建数据框,使其可在R语言环境中进行数据分析。
#8. 使用tibble
要使用提供的向量创建tibble数据框并利用tidyverse库,您可以按照以下步骤操作:
# 加载tidyverse库
if (!require("tidyverse")) {
install.packages("tidyverse")
library(tidyverse)
}
# 使用提供的向量创建tibble
sales_data <- tibble(
OrderID = 1001:1011,
Product = c("笔记本电脑", "智能手机", "平板电脑", "耳机", "相机", "电视", "打印机", "洗衣机", "冰箱", "微波炉", "咖啡机"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("信用卡", "PayPal", "现金", "信用卡", "现金", "PayPal", "现金", "信用卡", "信用卡", "现金", "信用卡")
)
# 显示创建的销售tibble
print(sales_data)
此代码使用tidyverse库中的tibble()函数创建一个名为sales_data的tibble数据框。正如您所提到的,与默认的R语言数据框相比,tibble格式提供了更多信息打印。
如何在R语言中高效使用数据框
在R语言中有效使用数据框对于数据操作和分析至关重要。数据框是R语言中的基本数据结构,通常使用data.frame函数创建和操作。以下是一些高效工作的技巧:
- 在创建数据框之前,请确保您的数据是干净且结构良好的。删除任何不必要的行或列,处理缺失值,并确保数据类型合适。
- 为您的列设置适当的数据类型(例如数字型、字符型、因子型、日期型)。这可以提高内存使用率和计算速度。
- 使用索引和子集化来处理较小部分的数据。
subset()和[]运算符对此目的很有用。
- 虽然
attach()和detach()很方便,但它们也可能导致歧义和意外行为。
- R语言针对向量化操作进行了高度优化。只要有可能,就使用向量化函数而不是循环来进行数据操作。
- R语言中的嵌套循环可能会很慢。请尝试使用向量化操作或应用函数(如
lapply或sapply),而不是嵌套循环。
- 大型数据框会消耗大量内存。考虑使用
data.table或dtplyr包,它们对于较大的数据集来说内存效率更高。
- R语言有多种用于数据操作的包。利用
dplyr、tidyr和data.table等包进行高效的数据转换。
- 尽量减少全局变量的使用,尤其是在使用多个数据框时。使用函数并传递数据框作为参数。
- 在处理聚合数据时,使用
dplyr中的group_by()和summarize()函数可以高效地执行计算。
- 对于大型数据集,请考虑使用并行处理或
foreach等包来加速操作。
- 将数据读入R语言时,请使用
readr或data.table::fread等函数,而不是read.csv等基本R语言函数,以加快数据导入速度。
- 对于非常大的数据集,请考虑使用数据库系统或专门的存储格式,如Feather、Arrow或Parquet。
通过遵循这些最佳实践,您可以高效地使用R语言中的数据框,使您的数据操作和分析任务更易于管理且更快。
最后的想法
在R语言中创建数据框非常简单,并且您可以使用多种方法。我强调了数据框的重要性,并讨论了如何使用data.frame()函数创建数据框。
此外,我们还探讨了操作数据的方法,并介绍了如何从CSV和Excel文件创建数据框、将其他数据结构转换为数据框,以及如何使用tibble库。
您可能对R语言编程的最佳IDE感兴趣。