探索性数据分析详解
本文将深入探讨探索性数据分析(EDA),这是一个至关重要的过程,用于揭示数据集中隐藏的趋势和模式。通过统计摘要和图形可视化,EDA能够帮助我们更好地理解和总结数据集。
如同任何数据科学项目,探索性数据分析需要投入时间和精心组织,同时严格遵循一系列步骤。EDA是整个流程中不可或缺的重要环节。
接下来,我们将简要介绍什么是探索性数据分析,并展示如何使用R语言进行EDA。
探索性数据分析的定义
探索性数据分析是指在将数据集应用于特定业务、统计或机器学习等任务之前,对其特征进行检查和研究的过程。
通常,这种对数据本质及其主要特性的总结是通过可视化方法完成的,例如使用图表和表格。这种实践的目的是在进行更复杂的数据处理之前,准确评估数据的潜力。
因此,EDA的主要作用包括:
- 构建基于数据的假设;
- 探索数据结构中潜在的细节;
- 识别缺失值、异常值或异常行为;
- 发现整体趋势和相关变量;
- 剔除不相关或与其他变量相关的变量;
- 确定合适的建模方法。
描述性数据分析与探索性数据分析的区别
虽然目标不同,但描述性分析和探索性分析是两种并行的数据分析方法。
描述性分析侧重于描述变量的特征,例如均值、中位数和众数等。
探索性分析旨在识别变量之间的关系,提取初步见解,并将建模引导至常见的机器学习范式,如分类、回归和聚类。
两者都可能使用图形表示,但只有探索性分析旨在带来可操作的见解,即可以促使决策者采取行动的见解。
简而言之,探索性数据分析旨在解决问题并为建模步骤提供指导,而描述性分析仅旨在对相关数据集进行详细的描述。
| 描述性分析 | 探索性数据分析 | |
| 分析目标 | 分析变量的行为 | 分析变量的行为和关系 |
| 提供 | 数据总结 | 产生结论,促使规范和行动 |
| 数据展示 | 以表格和图表组织数据 | 以表格和图表组织数据 |
| 解释力 | 不具有显著的解释力 | 具有显著的解释力 |
EDA的实际应用案例
#1. 数字营销
数字营销已经从创意过程转变为数据驱动的过程。营销组织使用探索性数据分析来衡量营销活动的效果,指导消费者投资和目标决策。
人口统计研究、客户细分等技术允许营销人员利用大量的消费者购买、调查和面板数据,深入了解和制定营销策略。
网络探索性分析使营销人员可以收集有关网站交互的会话级信息。谷歌分析是营销人员常用的免费分析工具之一。
在营销中常用的探索性技术包括营销组合建模、定价和促销分析、销售优化以及客户细分等探索性客户分析。
#2. 探索性投资组合分析
探索性数据分析的一个常见应用是投资组合分析。银行或贷款机构持有不同价值和风险的账户组合。
账户可能因持有者的社会地位(富裕、中等收入、贫困等)、地理位置、净资产以及其他因素而不同。贷款人必须平衡每笔贷款的贷款回报与违约风险。因此,如何评估整个投资组合成为一个关键问题。
风险最低的贷款可能适用于非常富有的人,但富人的数量相对较少。另一方面,许多经济条件较差的人可以借款,但风险也更高。
探索性数据分析解决方案可以将时间序列分析与其他方法结合,以决定何时对不同借款人进行细分或贷款利率。向投资组合中风险较高的成员收取更高的利息,以弥补该部分成员的损失。
#3. 探索性风险分析
银行业正在开发预测模型,以提供有关个人客户风险评分的确定性信息。信用评分旨在预测个人的违约行为,并广泛用于评估每个申请人的信用度。
风险分析也被广泛应用于科学界、保险业和金融机构,如在线支付网关公司,用于分析交易是否真实。
他们使用客户的交易历史记录进行风险评估。 例如,在信用卡交易中,如果客户的交易量突然激增,系统会联系客户进行确认,有助于减少由此造成的损失。
使用R进行探索性数据分析
要使用R进行EDA,首先需要下载R base和R Studio (IDE)。 之后,需要安装并加载以下软件包:
#安装软件包
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#加载软件包
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
在本教程中,我们将使用R内置的经济数据集,该数据集提供了美国经济的年度经济指标数据。为了简化起见,我们将其命名为econ:
econ <- ggplot2::economics
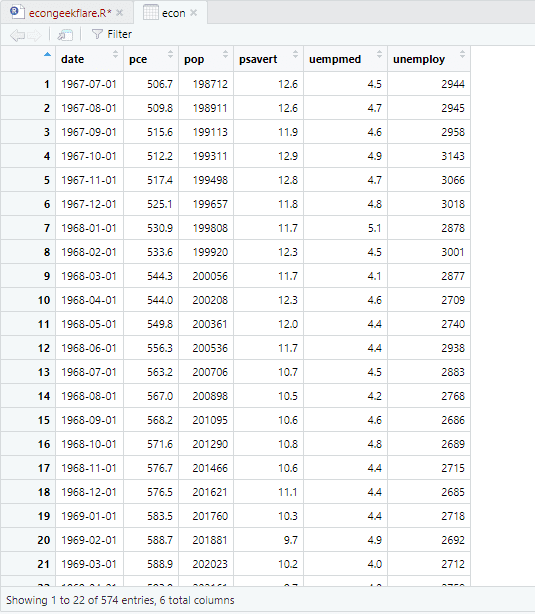
为了进行描述性分析,我们将使用skimr软件包,该软件包可以简单有效地计算统计数据:
#描述性分析 skimr::skim(econ)

你也可以使用summary函数进行描述性分析:
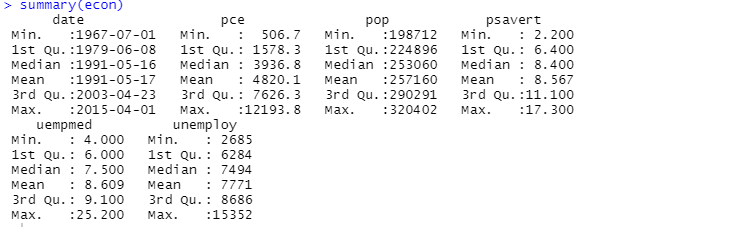
这里的描述性分析显示该数据集有547行和6列。最小值为1967-07-01,最大值为2015-04-01。同时,它还显示了平均值和标准差。
现在你对econ数据集的内容有了基本的了解。让我们绘制变量uempmed的直方图,以便更好地查看数据:
#失业率直方图 econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "失业率", title = "1967年至2015年美国月度失业率")
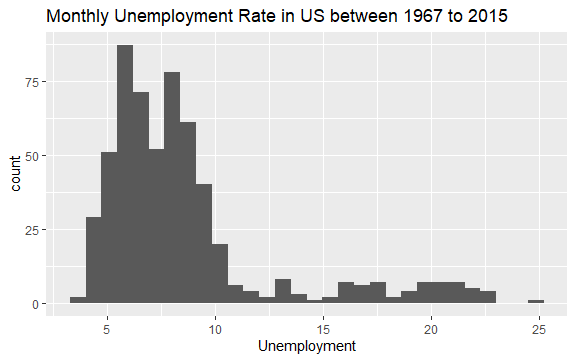
直方图的分布显示它的右侧有一个拉长的尾巴;也就是说,可能有一些对该变量的观察具有更多“极端”值。问题来了:这些数值发生在什么时期,变量的趋势是什么?
识别变量趋势的最直接方法是通过折线图。下面我们生成一个折线图并添加一条平滑线:
#失业率折线图 econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
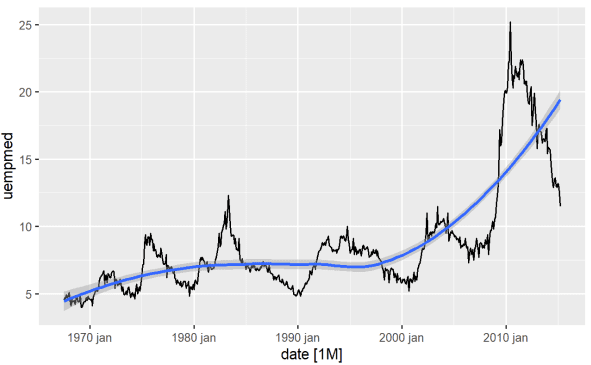
从图中我们可以确定,在最近一段时间,即2010年的最后一次观察中,失业率有上升的趋势,超过了前几十年观察到的历史水平。
另一个重要的点,特别是在计量经济学建模环境中,是序列的平稳性;也就是说,均值和方差是否随时间保持不变?
当这些假设在变量中不成立时,我们说该序列具有单位根(非平稳),因此该变量遭受的冲击会产生永久性影响。
所讨论的变量,即失业持续时间,似乎就是这种情况。我们已经看到,变量的波动发生了很大变化,这对处理周期的经济理论有很强的影响。但是,脱离理论,我们如何实际检查变量是否是平稳的?
预测包具有出色的功能,允许应用测试,例如ADF、KPSS等,这些测试已经返回序列平稳所需的差异数量:
#使用ADF检验检查平稳性
forecast::ndiffs(
x = econ$uempmed,
test = "adf")

这里p值大于0.05表明数据是非平稳的。
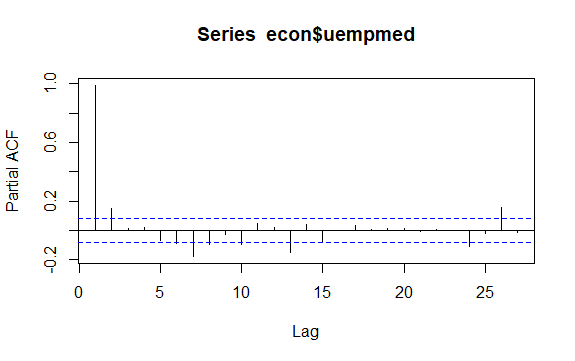
时间序列中的另一个重要问题是识别序列滞后值之间可能的相关性(线性关系)。 ACF和PACF相关图有助于识别它。
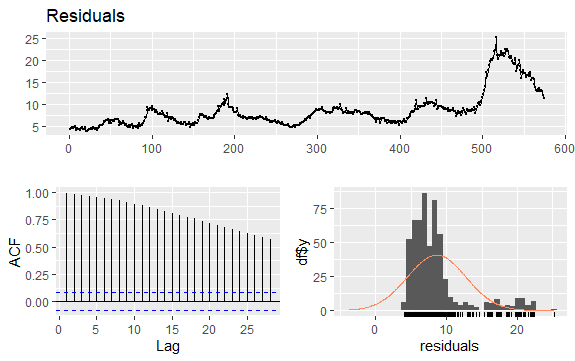
由于该序列没有季节性但具有一定的趋势,因此初始自相关往往较大且为正,因为时间接近的观测值也接近。
因此,趋势时间序列的自相关函数(ACF)往往具有正值,随着滞后的增加而缓慢减小。
#失业率残差
checkresiduals(econ$uempmed)
pacf(econ$uempmed)
结论
当数据经过清洗后,我们常常会立刻投入到模型构建阶段以获得初步结果。然而,我们必须抵制这种冲动,并首先进行探索性数据分析。虽然EDA非常简单,但它可以帮助我们深入了解数据。
你还可以探索一些学习数据科学统计学的最佳资源。