企业软件在云端的演进:从本地到AWS云数据库的迁移实战
站在企业软件发展的前沿,过去的二十年,尤其是近几年,一个显著的趋势是:将数据库迁移到云端。我曾参与多个将本地数据库迁移到亚马逊云服务(AWS)云数据库的项目。虽然AWS的文档宣称迁移过程简单便捷,但实际操作中,并非总是如此顺利,有时甚至会遭遇失败。本文将分享我在此过程中积累的真实经验,重点分析以下方面:
- 数据来源:理论上,数据来源本身并不重要,大多数主流数据库都适用相似的方法。但多年来,Oracle一直是大型企业的首选数据库系统,因此本文以此为例。
- 目标数据库:目标数据库的选择并不受限制,AWS中任何目标数据库都可以应用本文所述的方法。
- 迁移模式:可选择完全刷新或增量刷新。可以进行批量数据加载(源和目标状态存在延迟)或(接近)实时数据加载。本文将探讨这两种方式。
- 迁移频率:可以选择一次性迁移并完全切换到云端,也可以选择一个过渡期,让本地和云端数据保持同步更新,即在内部部署和AWS之间建立每日同步。前者更为简单直接,但后者更为常见,也面临更多挑战。本文将涵盖这两种场景。
问题描述
通常,迁移需求很简单:
“我们希望在AWS内部开发服务,请将所有数据复制到‘ABC’数据库。我们现在需要在AWS内部使用数据。稍后,我们将根据实际业务活动调整数据库设计。”
在开始迁移之前,需要考虑以下几个方面:
- 不要轻易采取“先复制再处理”的策略。虽然这是最简单、最快捷的方法,但可能导致基础架构问题,后期需要对新的云平台进行大规模重构才能解决。云生态系统与本地生态系统截然不同,随着时间推移,新的云服务会不断推出。人们对数据的利用方式也会随之改变。简单地在云端复制本地数据并不是一个好主意。当然,也可能适用于你的情况,但务必仔细考量。
- 需要对需求进行深入分析,例如:
- 新平台的典型用户是谁?本地环境中可能是交易业务用户,而在云端可能是数据科学家、数据仓库分析师,或者主要用户是其他服务(如Databricks、Glue、机器学习模型等)。
- 过渡到云端后,日常工作是否会保持不变?如果不是,将如何改变?
- 是否计划在云端显著扩大数据规模?这通常是迁移到云端的首要原因。新的数据模型应为此做好准备。
- 预估最终用户对新数据库的查询方式,这将有助于确定当前数据模型需要进行哪些调整,以确保性能。
设置迁移
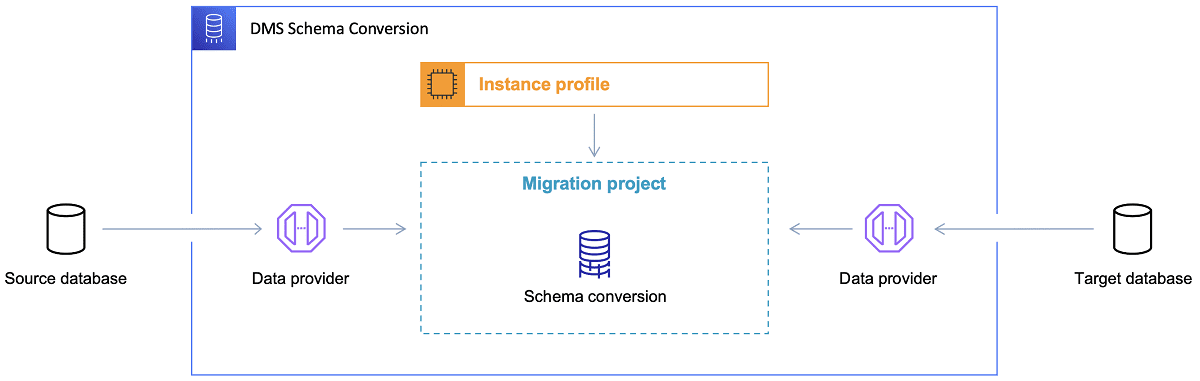
确定目标数据库并充分探讨数据模型后,下一步是熟悉AWS Schema Conversion Tool(SCT)。SCT工具的主要用途包括:
- 分析并提取源数据模型。SCT会读取当前本地数据库的内容,并生成源数据模型作为迁移的基础。
- 根据目标数据库,建议目标数据模型结构。
- 生成目标数据库的部署脚本,用于安装目标数据模型。脚本执行后,云端的数据库就可以从本地数据库加载数据。
图片来源:AWS官方文档
以下是一些关于使用SCT的技巧:
首先,通常不会直接使用SCT的输出。SCT的输出更像一个参考结果,你需要根据对数据的理解,以及数据在云端的用途进行调整。其次,早期的数据表可能是由需要快速获取特定数据域结果的用户创建的。但是,现在数据可能被用于分析。例如,之前在本地数据库中使用的索引现在可能没有意义,并且不会提高新用途下的数据库性能。此外,你可能希望在目标系统上对数据进行不同的分区。
另外,最好考虑在迁移过程中进行一些数据转换,这意味着更改某些表的目标数据模型,使其不再是简单的1:1复制。之后,需要在迁移工具中实施转换规则。
如果源数据库和目标数据库类型相同(例如本地的Oracle和AWS中的Oracle,PostgreSQL和Aurora Postgresql),则最好使用数据库原生支持的迁移工具(如数据泵导出和导入、Oracle Goldengate)。
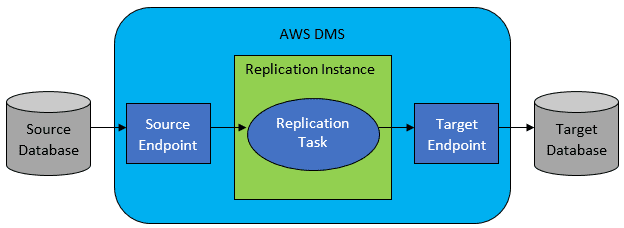
然而,在大多数情况下,源数据库和目标数据库不兼容,这时AWS Database Migration Service(DMS)是显而易见的选择。
图片来源:AWS官方文档
AWS DMS允许在表级别配置任务列表,这将定义:
- 需要连接的源数据库和表。
- 用于获取目标表数据的语句规范。
- 转换规则(如果有),定义如何将源数据映射到目标表数据(如果不是1:1)。
- 加载数据的目标数据库和表。
DMS任务配置以JSON等用户友好的格式完成。
在最简单的情况下,你只需要在目标数据库上运行部署脚本并启动DMS任务。但实际情况远非如此简单。
一次性全量数据迁移

最简单的情况是将整个数据库一次性迁移到目标云数据库。在这种情况下,你需要执行以下操作:
- 为每个源表定义DMS任务。
- 确保DMS任务的配置正确。这包括设置合理的并行度、缓存变量、DMS服务器配置、DMS集群大小等。这通常是最耗时的阶段,因为需要进行大量测试和微调。
- 确保在目标数据库中创建每个目标表,并具有预期的数据结构。
- 安排执行数据迁移的时间窗口。在此之前,通过性能测试确保时间窗口足够完成迁移。在迁移过程中,源数据库的性能可能会受到限制。此外,在迁移运行期间,源数据库的数据不应发生更改。否则,迁移的数据可能与源数据库中的数据不一致。
如果DMS的配置得当,这种情况一般不会出现问题。每个源表都会被复制到AWS目标数据库中。唯一需要关注的是性能,确保每一步的资源配置都正确,避免因存储空间不足而导致失败。
增量每日同步

当需要进行增量每日同步时,情况会变得复杂。理想情况下,一切都会顺利运行。但现实往往不是这样。
DMS可以配置为两种模式运行:
- 全量加载:这是默认模式,正如上面描述的那样。DMS任务在启动时或在计划启动时开始运行,一旦完成,DMS任务就结束了。
- 变更数据捕获(CDC):在此模式下,DMS任务会持续运行。DMS扫描源数据库以查找表级别的更改。如果发生更改,它会立即尝试根据与更改表相关的DMS任务中的配置,将更改复制到目标数据库中。
选择CDC模式时,你需要选择CDC如何从源数据库中提取增量更改。
#1. Oracle 重做日志读取器
一种选择是从Oracle数据库中选择原生重做日志读取器。CDC可以利用此读取器获取更改的数据,并在目标数据库上复制相同的更改。
如果源数据库是Oracle,这看起来是一个显而易见的选择,但存在一个问题:Oracle重做日志读取器会占用源Oracle集群的资源,直接影响数据库中运行的其他活动(它实际上直接在数据库中运行)。
配置的DMS任务越多(或并行DMS集群越多),你可能需要越多地扩展Oracle集群,这意味着调整主Oracle数据库集群的垂直扩展。这肯定会增加解决方案的总成本,特别是如果每日同步在项目中长期存在。
#2. AWS DMS 日志挖掘器
与上述选项不同,这是AWS针对同一问题的原生解决方案。在这种情况下,DMS不会影响源Oracle数据库。相反,它会将Oracle重做日志复制到DMS集群并在那里进行处理。虽然这节省了Oracle的资源,但这是一个较慢的解决方案,因为它涉及更多操作。而且,Oracle的自定义读取器可能不如Oracle本地读取器。
在理想情况下,根据源数据库的大小和每日更改的数量,你可能最终将本地Oracle数据库中的数据近乎实时地增量同步到AWS云数据库中。在其他情况下,可能无法实现实时同步,但你可以尝试调整源和目标集群的性能配置和并行性,或尝试调整DMS任务的数量及其在CDC实例之间的分布,从而尽可能接近可接受的延迟。
你可能需要了解CDC支持哪些源表更改(例如添加列),因为并非所有可能的更改都受支持。在某些情况下,唯一的方法是手动更改目标表,并从头开始重新启动CDC任务(这会导致丢失目标数据库中的所有现有数据)。
当事情出错时,无论如何

我从惨痛的教训中得知,有一个与DMS相关的特定场景很难实现每日复制的承诺。
DMS只能以某种特定的速度处理重做日志。即使有更多的DMS实例执行你的任务,每个DMS实例仍然只能以单一定义的速度读取重做日志,并且每个实例都必须完整读取它们。使用Oracle重做日志或AWS日志挖掘器都无法改变这一限制。
如果源数据库在一天内包含大量更改,而Oracle重做日志变得非常大(例如500GB以上),CDC将无法正常工作。复制无法在当天结束前完成。未处理的数据会累积到第二天,而新的更改已经等待被复制。未处理的数据量只会一天比一天增加。
在这种情况下,CDC不是一个可行的选择(经过多次性能测试和尝试)。为了确保至少当天产生的所有增量更改都能在同一天被复制,我们不得不采取以下方法:
- 将不常用的非常大的表分离出来,每周只复制一次(例如,在周末)。
- 将不太大但仍然很大的表的复制配置为在多个DMS任务之间拆分。一张表由10个或更多独立的DMS任务并行迁移,确保DMS任务之间的数据拆分不同(这需要自定义编码),并且每天执行。
- 添加更多的DMS实例(最多4个),并在它们之间平均分配DMS任务,这意味着不仅按表的数量分配,还要考虑表的大小。
基本上,我们使用DMS的全量加载模式来复制每日数据,因为这是确保至少当天数据复制完成的唯一方法。
这不是一个完美的解决方案,但它仍然可行,即使多年以后,仍然以同样的方式工作。所以,也许这并不是一个糟糕的方案。😃