核心要点
- 并发与并行是计算机科学中处理任务执行的两种基本模式,它们各自具备独特的特性。
- 并发性侧重于高效利用资源并提升应用程序的响应速度,而并行性则致力于实现最佳性能和扩展能力。
- Python提供了多种处理并发的方案,例如使用 asyncio 库进行线程操作和异步编程,以及利用 multiprocessing 模块实现并行处理。
并发和并行是两种能够让程序同时执行的技术。Python 提供了多种处理并发和并行任务的选项,这可能会让初学者感到困惑。
本文将探讨在 Python 中实现并发和并行处理的工具和库,以及它们之间的区别。
理解并发与并行
并发和并行代表了计算任务执行的两种基本策略,每一种都有其独特的运行方式。

并发与并行性的重要性
在计算领域,并发性和并行性的重要性再怎么强调也不为过。以下是这些技术至关重要的原因:
Python 中的并发
在 Python 中,您可以使用 asyncio 库的线程和异步编程来实现并发。
Python 中的线程
线程是一种 Python 并发机制,允许您在单个进程中创建和管理多个任务。 线程特别适用于那些受 I/O 限制的任务,这些任务可以从并发执行中受益。
Python 的 threading 模块提供了创建和管理线程的高级接口。虽然由于全局解释器锁(GIL)的限制,线程无法实现真正的并行,但它们仍然可以通过有效交错任务来实现并发。
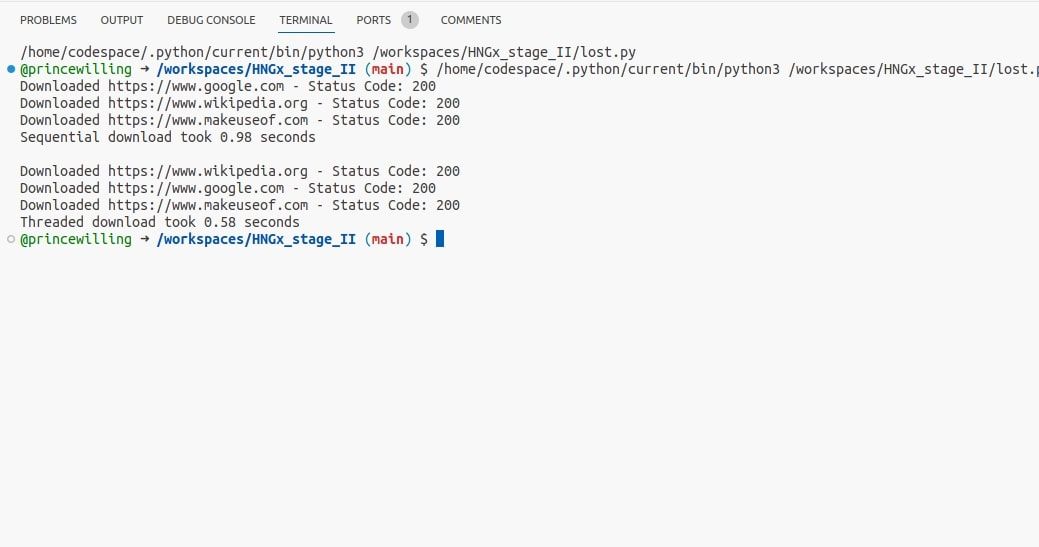
以下代码展示了如何使用线程实现并发的示例。它使用 Python 的 requests 库发送 HTTP 请求,这是一种常见的 I/O 阻塞任务。 它还使用了 time 模块来测量执行时间。
import requests
import time
import threadingurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"已下载 {url} - 状态码: {response.status_code}")
start_time = time.time()for url in urls:
download_url(url)end_time = time.time()
print(f"顺序下载耗时 {end_time - start_time:.2f} 秒\n")
start_time = time.time()
threads = []for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()end_time = time.time()
print(f"线程下载耗时 {end_time - start_time:.2f} 秒")
运行这段程序,您应该能够看到使用线程发起的请求比顺序请求快得多。即使差异只有几分之一秒,但在使用线程执行 I/O 密集型任务时,性能提升也是非常显著的。
使用 asyncio 进行异步编程
asyncio 提供了一个事件循环,用于管理被称为协程的异步任务。协程是一种可以暂停和恢复的函数,因此它们非常适合 I/O 密集型任务。该库对于那些需要等待外部资源(例如网络请求)的场景特别有用。
您可以修改前面的请求发送示例以使用 asyncio:
import asyncio
import aiohttp
import timeurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"已下载 {url} - 状态码: {response.status}")
async def main():
tasks = [download_url(url) for url in urls]
await asyncio.gather(*tasks)start_time = time.time()
asyncio.run(main())end_time = time.time()
print(f"Asyncio 下载耗时 {end_time - start_time:.2f} 秒")
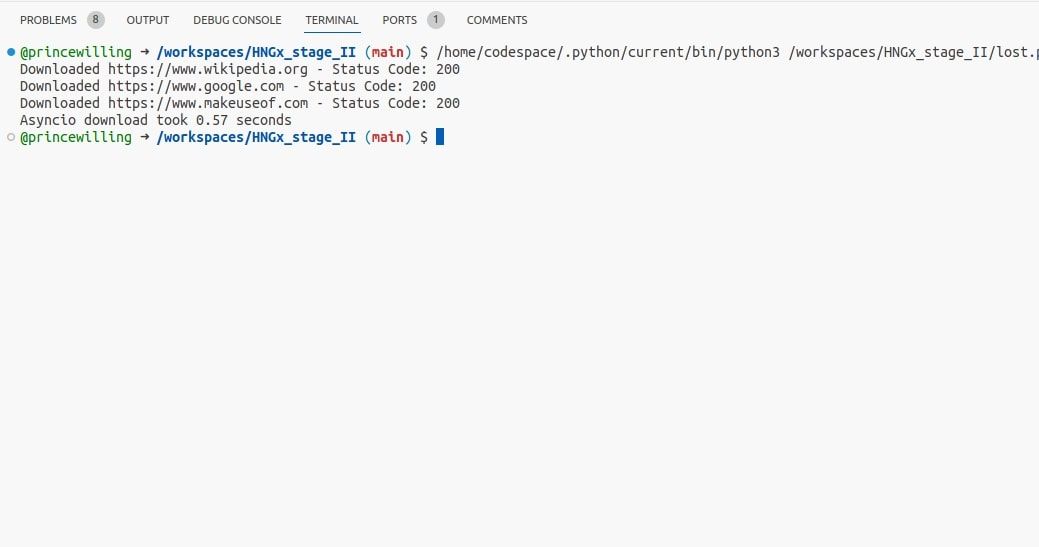
使用这段代码,您可以利用 asyncio 同时下载网页,并利用异步 I/O 操作。对于 I/O 密集型任务来说,这比线程更加高效。
Python 中的并行性
您可以使用 Python 的 multiprocessing 模块来实现并行处理,从而充分利用多核处理器。
Python 中的多处理
Python 的 multiprocessing 模块提供了一种通过创建独立的进程来实现并行性的方法,每个进程都有自己的 Python 解释器和内存空间。 这有效地绕过了全局解释器锁(GIL)的限制,因此非常适合 CPU 密集型任务。
import requests
import multiprocessing
import timeurls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"已下载 {url} - 状态码: {response.status_code}")def main():
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
pool.close()
pool.join()print(f"多进程下载耗时 {end_time-start_time:.2f} 秒")
main()
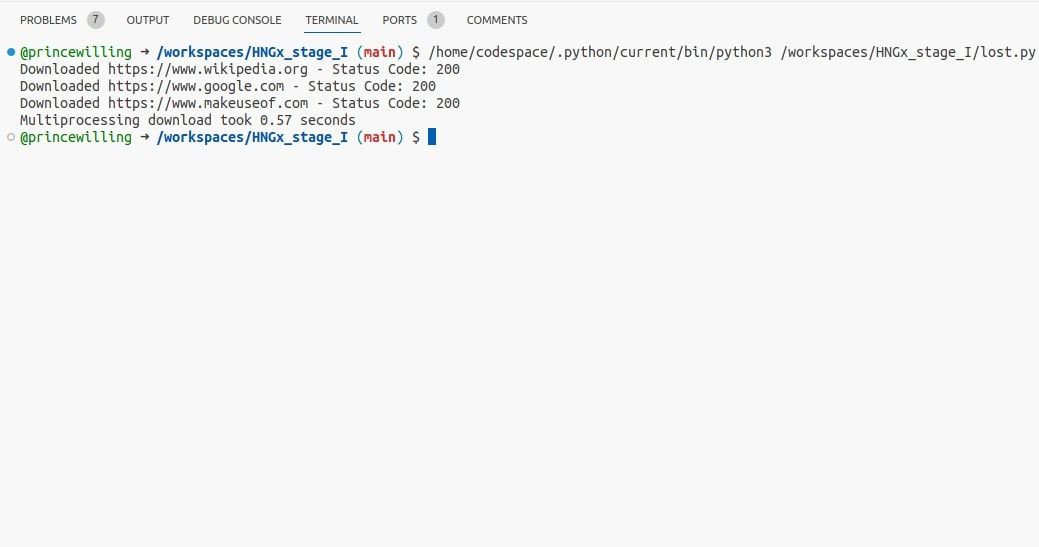
在此示例中,multiprocessing 模块会创建多个进程,允许 download_url 函数并行运行。
何时使用并发或并行
并发和并行之间的选择取决于任务的性质以及可用的硬件资源。
当处理 I/O 密集型任务(例如读取和写入文件或发出网络请求)并且需要考虑内存限制时,并发可能是一个更好的选择。
当您的 CPU 密集型任务可以从真正的并行性中受益,并且任务之间具有高度隔离性(其中一个任务的失败不应影响其他任务)时,请使用多处理。
充分利用并发和并行性
并行性和并发性是提高 Python 代码响应速度和性能的有效方法。 理解这些概念之间的区别并选择最有效的策略至关重要。
无论您处理的是 CPU 密集型进程还是 I/O 密集型进程,Python 都提供了必要的工具和模块,使您的代码通过并发或并行变得更加高效。