随着企业生成的数据量日益增长,传统的数据仓库架构在维护上变得愈发困难,且维护成本也随之攀升。为了解决这些难题,一种名为 Data Vault 的新型数据仓库方法应运而生。它以其卓越的扩展性、敏捷性和成本效益,为管理海量数据提供了全新的解决方案。
本文将深入探讨 Data Vault 如何引领数据仓库的未来发展,并分析其日益受到企业青睐的原因。此外,我们还将为有志于深入研究这一主题的读者提供丰富的学习资源!
什么是 Data Vault?
Data Vault 是一种专门为敏捷数据仓库设计的建模技术。它在扩展性方面表现出极高的灵活性,能够完整地记录数据在时间维度上的历史变化,并支持数据加载过程的高度并行化。Data Vault 建模由 Dan Linstedt 在 20 世纪 90 年代开发完成。
该技术在 2000 年首次公开亮相,并在 2002 年通过一系列文章获得了广泛的关注。2007 年,Data Vault 获得了数据仓库领域的先驱人物 Bill Inmon 的认可,他将 Data Vault 描述为他提出的 Data Vault 2.0 架构的“最佳选择”。
任何对敏捷数据仓库有所了解的人,都会很快联想到 Data Vault 技术。它的独特之处在于它高度关注企业的实际需求,能够灵活且高效地调整数据仓库,以适应不断变化的业务环境。
Data Vault 2.0 综合考虑了整个开发流程和架构,它由组件方法(实现)、架构和模型三部分组成。这种方法的优点在于,它在开发过程中充分考虑了商业智能与底层数据仓库的各个方面。
Data Vault 模型为解决传统数据建模方法的局限性提供了一种现代化的解决方案。凭借其卓越的可扩展性、灵活性和敏捷性,Data Vault 为构建能够适应现代数据环境复杂性和多样性的数据平台奠定了坚实的基础。
Data Vault 的星型架构以及实体和属性的分离,支持跨多个系统和领域的数据集成与协调,从而促进了增量式的敏捷开发。
Data Vault 在数据平台构建中的一个关键作用是为所有数据建立单一的事实来源。其统一的数据视图,以及通过卫星表捕获和跟踪历史数据变化的功能,为合规性、审计、法规要求以及综合分析和报告提供了强有力的支持。
Data Vault 通过增量加载实现的近乎实时的数据集成能力,有助于在如大数据和物联网应用等快速变化的环境中处理海量数据。
Data Vault 与传统数据仓库模型的对比
第三范式 (3NF) 是最广为人知的传统数据仓库模型之一,它在许多大型项目中通常是首选方案。巧合的是,这与数据仓库概念的“先驱”之一 Bill Inmon 的想法不谋而合。
Inmon 的架构基于关系数据库模型,通过将数据源分解为更小的表来消除数据冗余。这些表存储在数据集市中,并使用主键和外键相互连接。它通过执行参照完整性规则来确保数据的一致性和准确性。
第三范式的目标是为核心数据仓库构建一个全面的、企业范围的数据模型。然而,由于高度耦合的数据集市、近实时模式下的加载困难、复杂的请求以及自上而下的设计和实现方式,它在可扩展性和灵活性方面存在显著问题。
另一种著名的用于 OLAP(联机分析处理)和数据集市的数据仓库模型是 Kimball 模型。在该模型中,事实表包含聚合数据,而维度表则以星型模式或雪花模式设计,用于描述存储的数据。在此架构中,数据被组织成非规范化的事实表和维度表,以简化查询和分析。
Kimball 模型基于为查询和报告优化的维度模型,使其成为商业智能应用的理想选择。但是,它也存在一些问题,例如面向主题的信息隔离、数据冗余、查询结构不兼容、可扩展性难题、事实表粒度不一致、同步问题,以及需要自上而下设计和自下而上实现的方式。
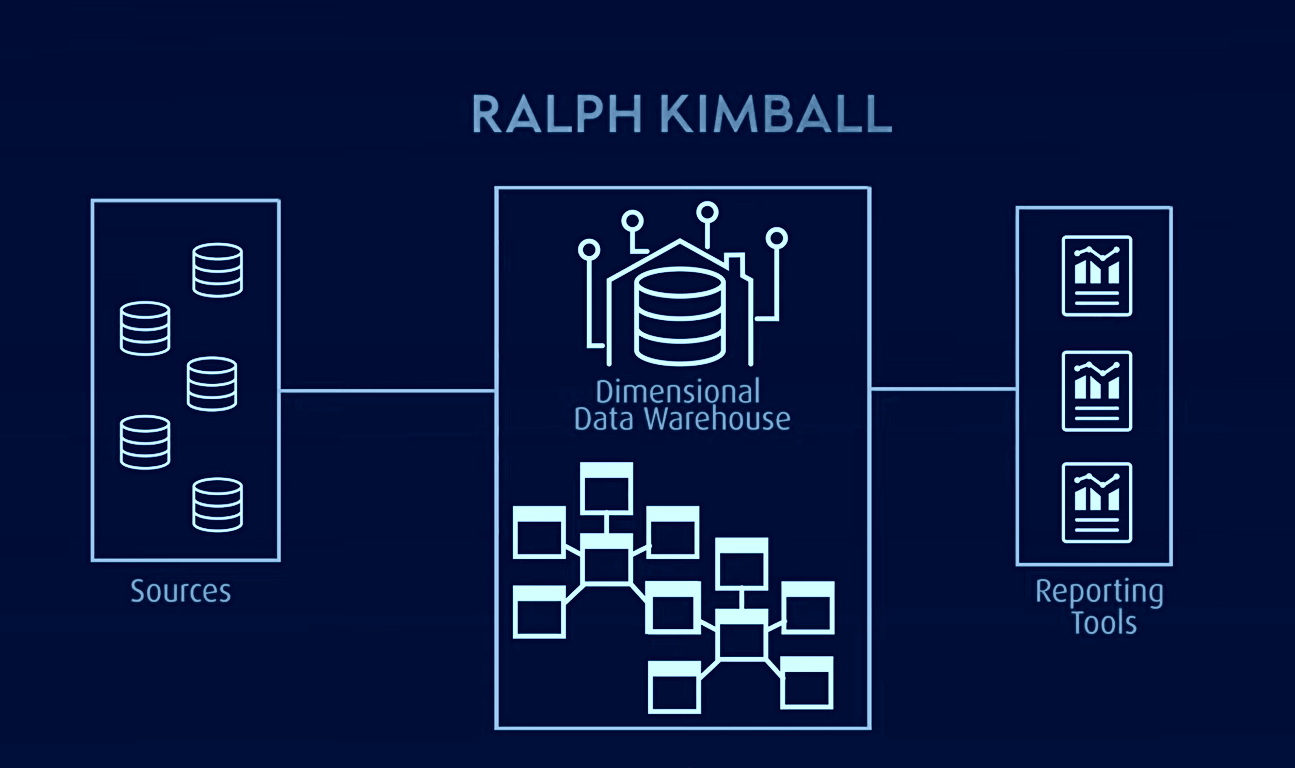
相比之下,Data Vault 架构是一种混合方法,它结合了 3NF 和 Kimball 架构的各个方面。它是一种基于关系原理、数据规范化和冗余数学的模型,它以不同的方式表示实体之间的关系,并以不同的方式构建表字段和时间戳。
在此架构中,所有数据都存储在原始数据保险库或数据湖中,而常用数据则以规范化的格式存储在业务保险库中。业务保险库包含可用于报告的历史数据和特定于上下文的数据。
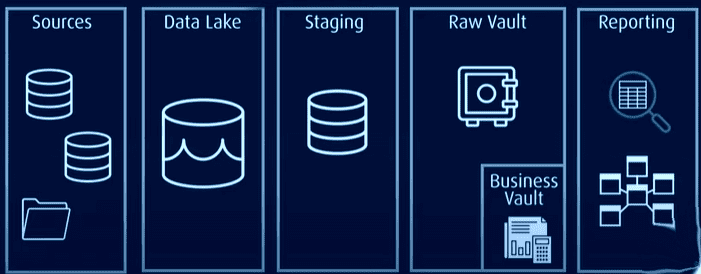
Data Vault 通过提高效率、可扩展性和灵活性来解决传统模型中的问题。它支持近乎实时的加载、更高的数据完整性,并且可以在不影响现有结构的情况下轻松进行扩展。此外,还可以在不迁移现有表的情况下对模型进行扩展。
| 建模方法 | 数据结构设计方法 | 方式 |
| 3NF 建模 | 3NF 中的表 | 自下而上 |
| Kimball 建模 | 星型模式或雪花模式 | 自上而下 |
| Data Vault | 中心辐射型 | 自下而上 |
Data Vault 的架构
Data Vault 采用星型架构,它基本上由三个层次构成:
暂存层: 从源系统(例如 CRM 或 ERP 系统)收集原始数据。
数据仓库层:当建模为 Data Vault 模型时,该层包括:
- 原始数据保险库 (Raw Data Vault):存储原始数据。
- 业务数据仓库 (Business Data Vault):包含基于业务规则协调和转换后的数据(可选)。
- 指标仓库 (Metrics Vault):存储运行时信息(可选)。
- 操作仓库 (Operational Vault):存储直接从操作系统流入数据仓库的数据(可选)。
数据集市层:该层将数据建模为星型模式或其他建模技术。它为分析和报告提供信息。
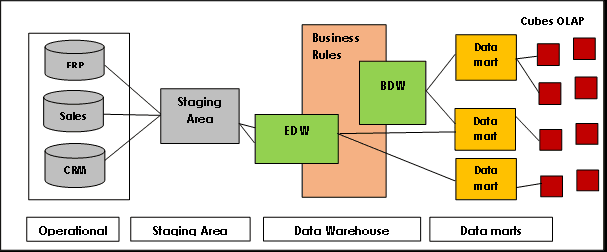 图片来源:Lamia Yessad
图片来源:Lamia Yessad
Data Vault 不需要进行重新架构。可以直接使用 Data Vault 的概念和方法并行构建新功能,而不会丢失现有的组件。框架可以大大简化工作:它们在数据仓库和开发人员之间创建了一个层,从而降低了实施的复杂性。
Data Vault 的组成部分
在建模过程中,Data Vault 将属于对象的所有信息分为三类,这与传统的第三范式建模形成对比。然后,这些信息将被严格地分开存储。功能区域可以映射到 Data Vault 中所谓的中心、链接和卫星中:
#1。 中心
中心是核心业务概念(如客户、销售人员、销售或产品)的核心。当业务键的新实例首次被引入数据仓库时,将围绕业务键(如商店名称或位置)形成中心表。
中心不包含任何描述性信息,也没有外键 (FK)。它仅包含业务键、仓库生成的 ID 或哈希键序列、加载日期/时间戳和记录来源。
#2。 链接
链接建立业务键之间的关系。链接中的每个条目都对任意数量的中心之间的多对多关系进行建模。它允许 Data Vault 灵活地响应源系统业务逻辑的变化,例如关系亲密度的变化。与中心类似,链接不包含任何描述性信息。它由它所引用的中心的序列 ID、仓库生成的序列 ID、加载日期/时间戳和记录来源组成。
#3。 卫星
卫星包含存储在中心中的业务键或存储在链接中的关系的描述性信息(上下文)。卫星以“仅插入”的方式工作,这意味着完整的数据历史记录都存储在卫星中。多个卫星可以描述单个业务键(或关系)。但是,卫星只能描述一个键(中心或链接)。
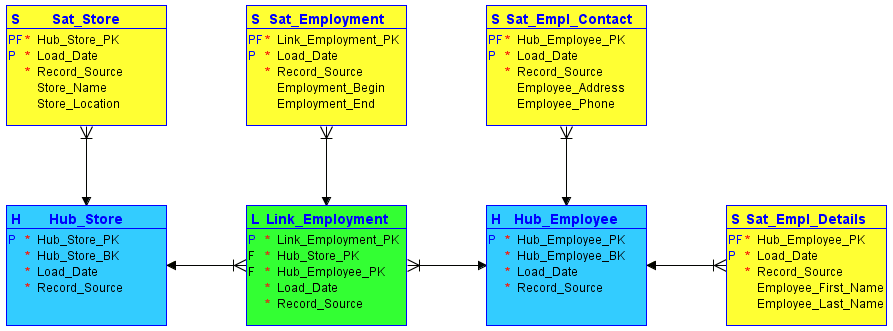 图片来源:Carbidfischer
图片来源:Carbidfischer
如何构建 Data Vault 模型
构建 Data Vault 模型涉及多个步骤,每个步骤对于确保模型具有可扩展性、灵活性并能够满足业务需求至关重要:
#1。 识别实体和属性
识别业务实体及其相应的属性。这需要与业务利益相关者密切合作,以了解他们的需求以及他们需要捕获的数据。一旦确定了这些实体和属性,就将它们分成中心、链接和卫星。
#2。 定义实体关系并创建链接
一旦确定了实体和属性,就可以定义实体之间的关系,并创建表示这些关系的链接。每个链接都分配有一个业务键,用于标识实体之间的关系。然后添加卫星来捕获实体的属性和关系。
#3。 建立规则和标准
创建链接之后,应建立一套规则和数据仓库建模标准,以确保模型具有灵活性,并能够处理随着时间变化而出现的变化。应定期审查和更新这些规则和标准,以确保它们保持相关性并符合业务需求。
#4。 填充模型
创建模型后,应使用增量加载方法为其填充数据。这涉及使用增量加载将数据加载到中心、链接和卫星中。增量加载可确保只加载对数据所做的更改,从而减少数据集成所需的时间和资源。
#5。 测试和验证模型
最后,应该对模型进行测试和验证,以确保它满足业务需求,并且具有足够的可扩展性和灵活性来处理未来的变化。应执行定期维护和更新,以确保模型与业务需求保持一致,并继续提供统一的数据视图。
Data Vault 学习资源
掌握 Data Vault 可以提供宝贵的技能和知识,这些技能和知识在当今数据驱动的行业中备受追捧。以下是一份包含课程和书籍的全面资源列表,可帮助您了解 Data Vault 的复杂性:
#1。 使用 Data Vault 2.0 建模数据仓库

本 Udemy 课程全面介绍了 Data Vault 2.0 建模方法、敏捷项目管理和大数据集成。该课程涵盖 Data Vault 2.0 的基础知识,包括其架构和层、业务和信息仓库以及高级建模技术。
它将指导您从头开始设计 Data Vault 模型,将 3NF 和维度模型等传统模型转换为 Data Vault,并理解 Data Vault 中维度建模的原理。该课程要求具备数据库和 SQL 的基本知识。
该课程销量领先,评分高达 4.4(满分 5 分),并有超过 1,700 条评论,适合任何希望在 Data Vault 2.0 和大数据集成方面打下坚实基础的人。
#2。 用用例解释数据仓库建模

本 Udemy 课程旨在指导您使用实际的业务示例来构建 Data Vault 模型。它可以作为 Data Vault 建模的初学者指南,涵盖诸如 Data Vault 模型的适用场景、传统 OLAP 建模的局限性,以及构建 Data Vault 模型的系统方法等关键概念。即使是只有少量数据库知识的个人也可以轻松学习该课程。
#3。 Data Vault Guru:实用指南
Patrick Cuba 先生的《Data Vault Guru》是对 Data Vault 方法的综合指南,它提供了一个独特的机会,可以使用类似于软件交付中使用的自动化原理对企业数据仓库进行建模。
本书概述了现代架构,然后提供了关于如何提供灵活的数据模型以适应企业 Data Vault 变化的详细指导。
此外,本书还通过提供自动时间线校正、审计跟踪、元数据控制以及与敏捷交付工具的集成来扩展 Data Vault 方法。
#4。 使用 Data Vault 2.0 构建可扩展的数据仓库
本书为读者提供了使用 Data Vault 2.0 方法从头开始创建可扩展数据仓库的综合指南。
本书涵盖了构建可扩展数据仓库的所有基本方面,包括旨在防止典型数据仓库故障的 Data Vault 建模技术。
本书提供了大量的示例,以帮助读者清楚地理解这些概念。凭借其具有实践性的见解和真实的示例,这本书对于任何对数据仓库感兴趣的人来说都是必不可少的资源。
#5。 冰箱里的大象:Data Vault 成功的指导步骤
John Giles 的《冰箱里的大象》是一本实用的指南,旨在帮助读者通过从业务开始和以业务结束来取得 Data Vault 的成功。
本书侧重于企业本体和业务概念建模的重要性,并提供了关于如何应用这些概念来创建可靠数据模型的分步指导。
通过实用的建议和示例模式,作者对复杂的主题进行了清晰而简单的解释,使本书成为 Data Vault 新手的绝佳指南。
最后的话
Data Vault 代表了数据仓库的未来发展方向,它在敏捷性、可扩展性和效率方面为企业带来了显著的优势。它特别适合需要快速加载海量数据的企业,以及希望以敏捷方式开发商业智能应用的企业。
此外,拥有现有孤岛架构的企业也可以从使用 Data Vault 实施上游核心数据仓库中获益匪浅。
您可能还对了解数据沿袭感兴趣。