认识 Apache Kafka:本地设置与使用指南
现代计算系统每天产生海量数据,这些数据涵盖了各种活动,如金融交易、订单以及汽车传感器数据等。为了能够实时处理这些数据流,并在不同的企业系统之间可靠地传输事件记录,Apache Kafka 是一个理想的选择。
Apache Kafka 是一个开源的数据流平台,它能够每秒处理超过百万条记录。 除了具备高吞吐量之外,Apache Kafka 还拥有卓越的可扩展性、高可用性、低延迟以及持久化存储能力。
许多知名企业,如 LinkedIn、优步和 Netflix 等,都依赖 Apache Kafka 进行实时数据处理和流式传输。 要快速上手 Apache Kafka,最直接的方式就是在您的本地计算机上搭建并运行它。 这不仅能够让您直观地了解 Apache Kafka 服务器的运行状态,还能让您动手生成和消费消息。
通过实际操作,例如启动服务器、创建主题以及使用 Kafka 客户端编写 Java 代码,您将能够充分掌握 Apache Kafka 的运用,从而满足您所有的数据管道需求。
如何在本地计算机上下载 Apache Kafka
您可以从 官方网站 下载最新版本的 Apache Kafka。 下载的文件将以 .tgz 格式压缩。 下载完成后,您需要将其解压缩。
如果您使用 Linux 系统,请打开终端。 接着,导航至您下载 Apache Kafka 压缩文件的目录。 然后执行以下命令:
tar -xzvf kafka_2.13-3.5.0.tgz
执行完毕后,您将看到一个名为 kafka_2.13-3.5.0 的新目录。 通过以下命令进入该文件夹:
cd kafka_2.13-3.5.0
现在,您可以利用 `ls` 命令列出该目录的内容。
对于 Windows 用户,也可以执行相同的操作。 如果找不到 `tar` 命令,可以使用诸如 WinZip 等第三方工具来解压缩文件。
如何在本地计算机上启动 Apache Kafka
当您下载并解压 Apache Kafka 之后,就可以启动它了。 Apache Kafka 无需安装程序。 您可以通过命令行或终端窗口直接启动。
在启动 Apache Kafka 之前,请确保您的系统已安装 Java 8+。 Apache Kafka 的运行依赖于 Java 环境。
#1. 启动 Apache Zookeeper 服务器
第一步是启动 Apache Zookeeper。 它已经预先包含在下载的存档中。 Zookeeper 负责维护配置并为其他服务提供同步服务。
在您解压存档内容的目录中,执行以下命令:
对于 Linux 用户:
bin/zookeeper-server-start.sh config/zookeeper.properties
对于 Windows 用户:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
zookeeper.properties 文件提供了运行 Apache Zookeeper 服务器所需的配置信息。 您可以配置诸如数据存储的本地目录以及服务器运行的端口等属性。
#2. 启动 Apache Kafka 服务器
现在 Apache Zookeeper 服务器已经启动,接下来就可以启动 Apache Kafka 服务器了。
打开一个新的终端或命令提示符窗口,并切换到解压文件的目录。 然后使用以下命令启动 Apache Kafka 服务器:
对于 Linux 用户:
bin/kafka-server-start.sh config/server.properties
对于 Windows 用户:
bin/windows/kafka-server-start.bat config/server.properties
此时,您的 Apache Kafka 服务器应该已经成功运行。 如果您需要修改默认配置,可以通过编辑 server.properties 文件进行调整。 更多配置信息请参考 官方文档。
如何在本地计算机上使用 Apache Kafka
现在您已经准备好在本地计算机上使用 Apache Kafka 来生成和消费消息。 既然 Apache Zookeeper 和 Apache Kafka 服务器都已启动并运行,让我们看看如何创建第一个主题,生成第一条消息并使用它。
在 Apache Kafka 中创建主题的步骤
在创建第一个主题之前,我们需要了解主题的含义。 在 Apache Kafka 中,主题是用于数据流的逻辑数据存储,它类似于数据从一个组件流向另一个组件的通道。
一个主题可以支持多个生产者和消费者,这意味着多个系统可以同时向一个主题写入数据和读取数据。 与其他消息系统不同的是,来自主题的任何消息都可以被重复使用。 此外,您还可以设置消息的保留期限。
举个例子,假设一个系统(生产者)生成银行交易数据,另一个系统(消费者)接收数据并向用户发送通知。 为了实现这一点,就需要一个主题。
打开一个新的终端或命令提示符窗口,并切换到解压文件的目录。 执行以下命令以创建一个名为 `transactions` 的主题:
对于 Linux 用户:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
对于 Windows 用户:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
现在,您已经创建了第一个主题,可以开始生成和消费消息了。
如何向 Apache Kafka 生成消息
当您的 Apache Kafka 主题准备就绪后,就可以生成第一条消息了。 打开一个新的终端或命令提示符窗口,或者使用之前创建主题的窗口。 确保您位于正确的解压文件目录。 使用以下命令,通过命令行向主题生成消息:
对于 Linux 用户:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
对于 Windows 用户:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
命令执行后,终端或命令提示符窗口将等待您的输入。 输入您的第一条消息并按回车键。
> This is a transactional record for $100
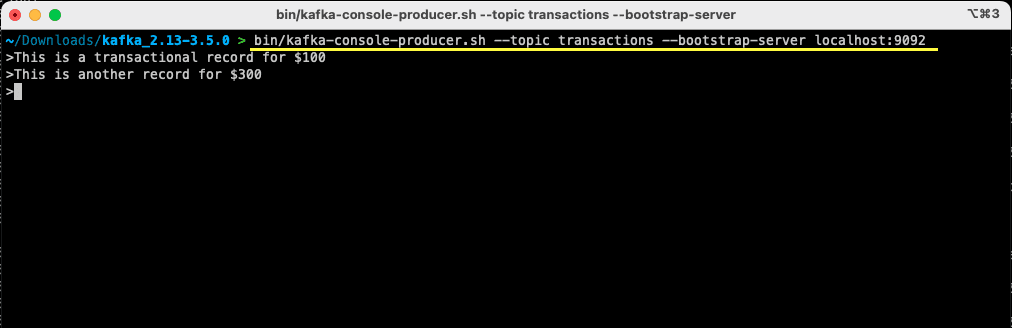
您已经成功在本地计算机上向 Apache Kafka 发送了第一条消息,现在您可以消费它了。
如何消费来自 Apache Kafka 的消息
如果您的主题已创建,并且已经向 Kafka 主题发送了一条消息,那么您现在就可以消费这条消息了。
Apache Kafka 允许您将多个消费者连接到同一个主题。 每个消费者都可以属于一个消费者组,消费者组是一个逻辑标识符。 例如,如果两个不同的服务需要使用相同的数据,它们可以拥有不同的消费者组。
然而,如果同一个服务有两个实例,则需要避免重复消费和处理同一条消息。 在这种情况下,两个实例需要共享同一个消费者组。
在终端或命令提示符窗口中,请确保您位于正确的目录中。 使用以下命令启动消费者:
对于 Linux 用户:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
对于 Windows 用户:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer

您将看到之前生成的消息显示在终端上。 您已经成功使用 Apache Kafka 消费了第一条消息。
`kafka-console-consumer` 命令包含多个参数,它们的含义如下:
- `–topic`:指定要消费消息的主题。
- `–from-beginning`:告诉控制台消费者从主题的起始位置读取消息。
- `–bootstrap-server`:指定 Apache Kafka 服务器的位置。
- `–group`:指定消费者组。 如果不指定,则会自动生成一个。
当控制台消费者运行时,您可以尝试生成新消息,这些消息都会被消费并显示在终端中。
现在您已经创建了主题,并成功生成和消费了消息,接下来让我们看看如何将其与 Java 应用程序集成。
如何使用 Java 创建 Apache Kafka 生产者和消费者
开始之前,请确保您的本地计算机上已安装 Java 8+。 Apache Kafka 提供自己的客户端库,方便您进行无缝连接。 如果您使用 Maven 管理依赖,请将以下依赖项添加到 `pom.xml` 文件中:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
您也可以从 Maven 仓库 下载库,并将其添加到您的 Java 类路径中。
准备好库之后,打开您选择的代码编辑器。 接下来,我们将看看如何使用 Java 启动生产者和消费者。
创建 Apache Kafka Java 生产者
一旦 `kafka-clients` 库就绪,您就可以开始创建 Kafka 生产者了。
创建一个名为 `SimpleProducer.java` 的类。 该类负责向之前创建的主题发送消息。 在这个类中,您需要创建 `org.apache.kafka.clients.Producer.KafkaProducer` 的一个实例。 然后使用此生产者发送消息。
为了创建 Kafka 生产者,您需要指定 Apache Kafka 服务器的主机和端口。 因为您在本地计算机上运行,所以主机是 `localhost`,端口在默认情况下是 `9092`(除非您在启动服务器时更改过)。 请参考下面的代码,它能帮助您创建生产者:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
您会注意到代码中设置了三个属性。 简要解释如下:
- `BOOTSTRAP_SERVERS_CONFIG`:指定 Apache Kafka 服务器的地址。
- `KEY_SERIALIZER_CLASS_CONFIG`:指定消息键的序列化格式。
- `VALUE_SERIALIZER_CLASS_CONFIG`:指定消息值的序列化格式。
由于您要发送文本消息,所以这两个属性都设置为使用 `StringSerializer.class`。
为了实际向主题发送消息,您需要使用接受 `ProducerRecord` 的 `Producer.send()` 方法。 以下代码提供了一种向主题发送消息并打印响应以及消息偏移量的方法。
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
完整的代码如下。您可以使用 `main` 方法来测试,如下面的代码所示:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
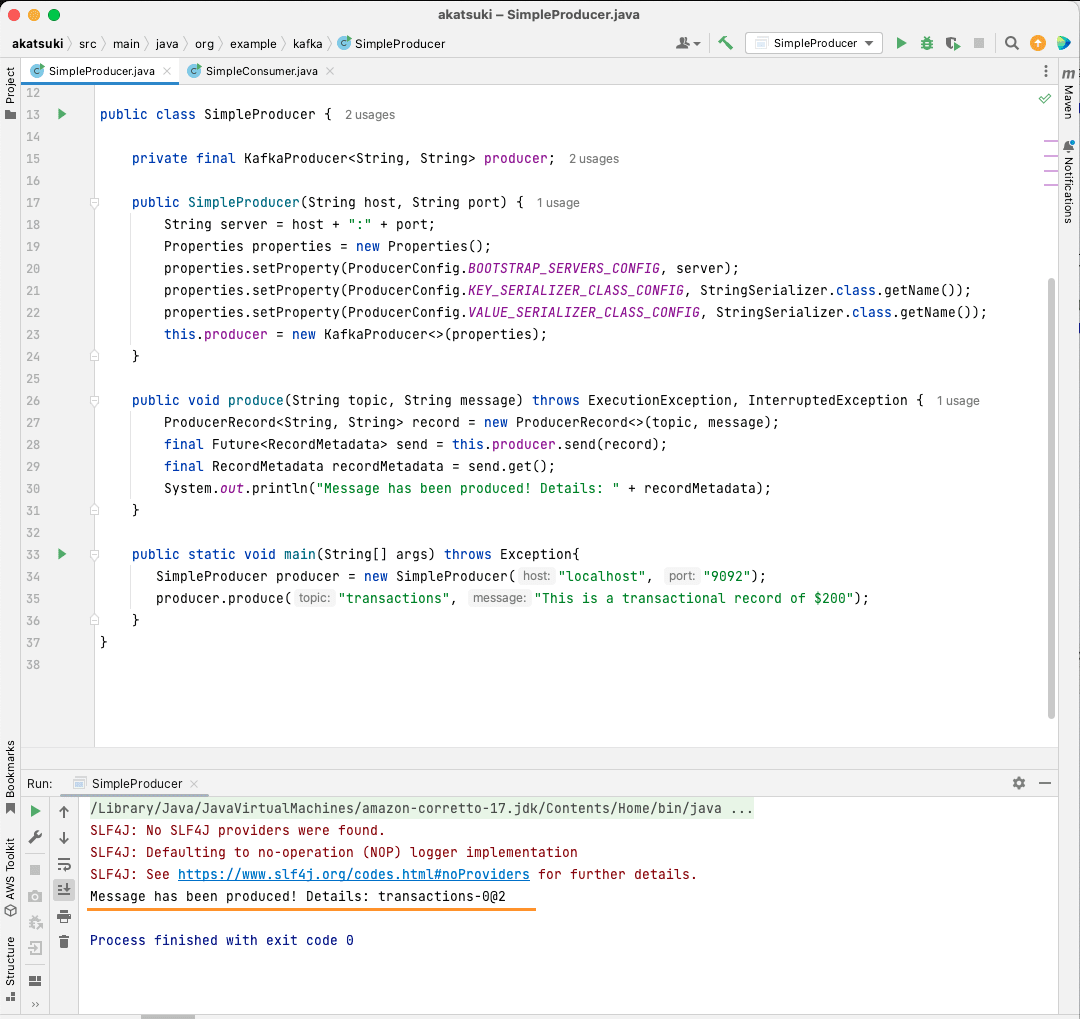
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
在这段代码中,您创建了一个 `SimpleProducer`,它连接到本地计算机上的 Apache Kafka 服务器。 它在内部使用 `KafkaProducer` 向您的主题发送一条文本消息。
创建 Apache Kafka Java 消费者
接下来,使用 Java 客户端创建一个 Apache Kafka 消费者。 创建一个名为 `SimpleConsumer.java` 的类。 在这个类中,您创建一个构造函数来初始化 `org.apache.kafka.clients.consumer.KafkaConsumer`。 为了创建消费者,您需要指定 Apache Kafka 服务器的主机和端口,以及消费者组和要消费的主题。 请参考以下代码片段:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
与 Kafka Producer 类似,Kafka Consumer 也接收 `Properties` 对象。 以下是不同属性的解释:
- `BOOTSTRAP_SERVERS_CONFIG`:告知消费者 Apache Kafka 服务器的地址。
- `GROUP_ID_CONFIG`:指定消费者组。
- `AUTO_OFFSET_RESET_CONFIG`:指定消费者在开始消费时从主题的哪个位置开始读取消息。
- `KEY_DESERIALIZER_CLASS_CONFIG`:指定消息键的反序列化格式。
- `VALUE_DESERIALIZER_CLASS_CONFIG`:指定消息值的反序列化格式。
由于这里使用的是文本消息,反序列化属性设置为 `StringDeserializer.class`。
现在,您将要消费来自主题的消息。 为简单起见,一旦消息被消费,您会将消息打印到控制台。 以下代码展示了如何实现:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
这段代码会持续轮询主题。 当收到消费者记录时,消息将被打印出来。 您可以使用 `main` 方法来测试消费者的实际情况。 您将启动一个 Java 应用程序,它会持续消费主题并打印消息。 停止 Java 应用程序以终止消费者。
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
当您运行代码时,您会发现它不仅会消费 Java 生产者生成的消息,还会消费您通过控制台生产者生成的消息。 这是因为 `AUTO_OFFSET_RESET_CONFIG` 属性被设置为 `earliest`。
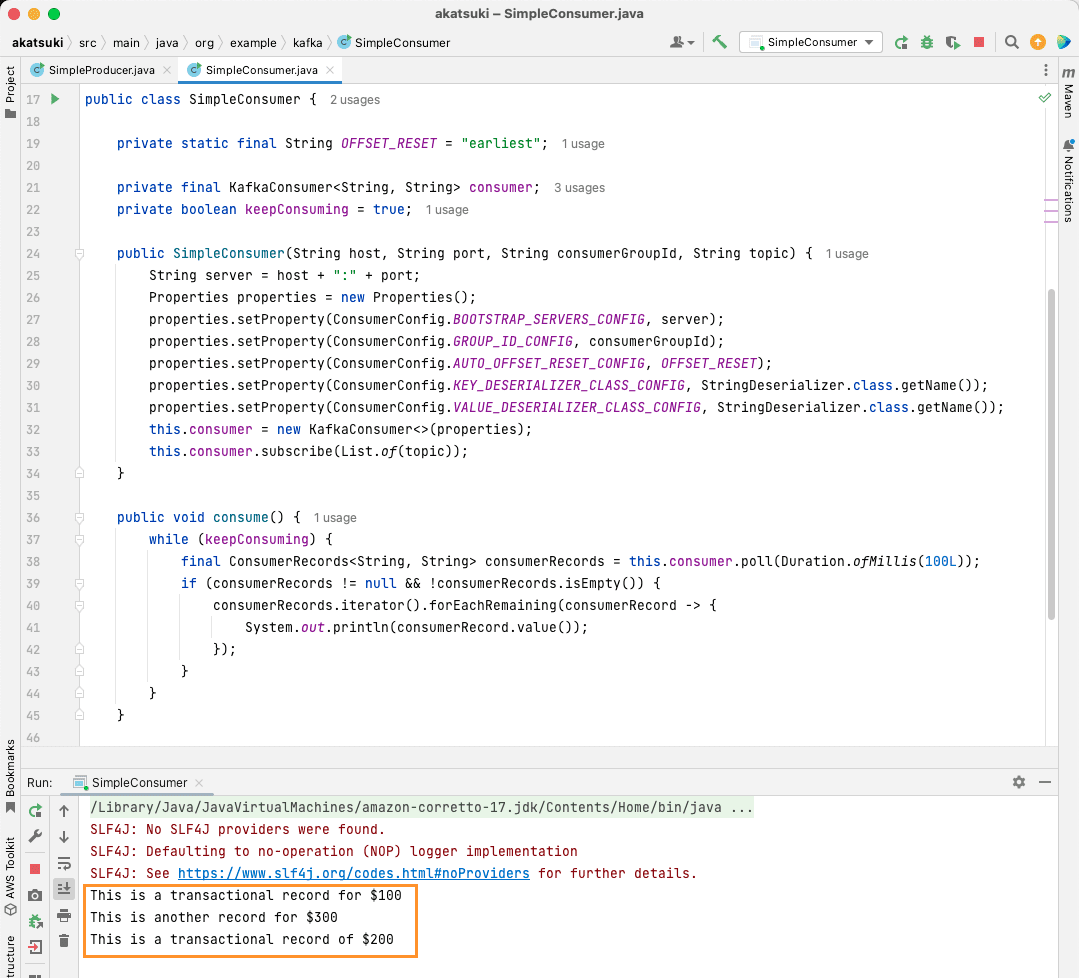
当 `SimpleConsumer` 运行时,您可以使用控制台生产者或 `SimpleProducer` Java 应用程序向主题生成更多消息。 您将看到这些消息被消费并打印在控制台上。
使用 Apache Kafka 满足您的所有数据管道需求
Apache Kafka 使您能够轻松处理所有数据管道的需求。 通过在本地计算机上设置 Apache Kafka,您可以探索其提供的各种功能。 此外,官方的 Java 客户端可让您高效地编写、连接 Apache Kafka 服务器并与其通信。
作为一个多功能、可扩展和高性能的数据流系统,Apache Kafka 可以改变您的工作方式。 您可以将其用于本地开发,也可以将其集成到生产系统中。 正如本地设置很容易一样,为更大的应用程序设置 Apache Kafka 也不是一件困难的事情。
如果您正在寻找数据流平台,您可以研究一些用于实时分析和处理的最佳流数据平台。