Google JAX,又名 Just After Execution,是谷歌开发的一个框架,用于加速机器学习任务的执行。
它可以被看作是一个Python库,旨在提高任务执行速度、进行科学计算、函数转换以及支持深度学习和神经网络等领域。
关于 Google JAX
在Python中,NumPy库是最基础的计算包,它提供了诸如聚合、向量运算、线性代数、n维数组和矩阵操作等多种功能,以及许多其他高级特性。
如果我们可以进一步加快使用NumPy执行的计算速度,特别是在处理大型数据集时,那将会如何?
是否有这样一种工具,它可以在不同类型的处理器(例如GPU或TPU)上以相同的方式工作,而无需更改任何代码?
如果一个系统能够自动且更有效地执行可组合的函数转换,那又会如何?
Google JAX就是一个这样的库(或框架,如维基百科所定义),它可以实现上述目标,甚至更多。它的设计目标是优化性能,并高效地执行机器学习(ML)和深度学习任务。Google JAX提供以下转换功能,使其有别于其他ML库,并有助于深度学习和神经网络的高级科学计算:
- 自动微分
- 自动向量化
- 自动并行化
- 即时 (JIT) 编译
Google JAX的独特之处在于其功能。
所有转换都利用XLA(加速线性代数)来实现更高的性能和内存优化。XLA是一个特定领域的优化编译器引擎,它执行线性代数并加速TensorFlow模型。在Python代码中使用XLA不需要对代码进行重大修改!
让我们详细探讨这些功能中的每一个。
Google JAX 的特点
Google JAX具有关键的可组合转换功能,可以提高性能并更有效地执行深度学习任务。例如,自动微分可以获得函数的梯度并找到任意阶的导数。同样,自动并行化和JIT可以并行执行多个任务。这些转变对于机器人、游戏甚至研究等应用至关重要。
可组合转换函数是将一组数据转换为另一种形式的纯函数。它们被称为可组合的,因为它们是自包含的(即,这些函数与程序的其余部分没有依赖关系),并且是无状态的(即,相同的输入总是会产生相同的输出)。
Y(x) = T(f(x))
在上面的公式中,f(x)是应用转换的原始函数。Y(x)是应用转换后的结果函数。
例如,如果您有一个名为“total_bill_amt”的函数,并且您希望将结果作为函数转换,您可以简单地使用您想要的转换,例如梯度(grad):
grad_total_bill = grad(total_bill_amt)
通过使用像grad()这样的函数来转换数值函数,我们可以很容易地得到它们的高阶导数,这在梯度下降等深度学习优化算法中被广泛使用,从而使算法更快、更高效。同样,通过使用jit(),我们可以实时(惰性)编译Python程序。
#1. 自动微分
Python使用autograd函数来自动区分NumPy和原生Python代码。JAX使用autograd的修改版本(即grad)并结合XLA(加速线性代数)来执行自动微分,并找到GPU(图形处理单元)和TPU(张量处理单元)的任何阶的导数。
关于TPU、GPU和CPU的快速说明:CPU或中央处理器管理计算机上的所有操作。GPU是一个额外的处理器,可以增强计算能力并运行高端操作。TPU是专为复杂和繁重的工作负载(如AI和深度学习算法)而开发的强大单元。
与autograd函数一样,它可以通过循环、递归、分支等进行区分,JAX使用grad()函数进行反向模式梯度(反向传播)。此外,我们可以使用grad将函数区分为任何顺序:
grad(grad(grad(sin θ)))(1.0)
高阶自动微分
正如我们之前提到的,grad在求函数的偏导数方面非常有用。我们可以使用偏导数来计算成本函数相对于深度学习中的神经网络参数的梯度下降,以最小化损失。
计算偏导数
假设一个函数有多个变量x、y和z。通过保持其他变量不变来求一个变量的导数称为偏导数。假设我们有一个函数,
f(x,y,z) = x + 2y + z²
显示偏导数的示例
x的偏导数将是∂f/∂x,它告诉我们当其他变量不变时,函数对于变量的变化。如果我们手动执行此操作,则必须编写程序进行微分,将其应用于每个变量,然后计算梯度下降。对于多个变量,这将成为一件复杂且耗时的事情。
自动微分将函数分解为一组基本运算,如+、-、*、/或sin、cos、tan、exp等,然后应用链式法则计算导数。我们可以在正向和反向模式下执行此操作。
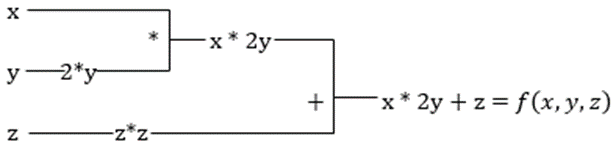
不止于此!所有这些计算都发生得如此之快(想想与上述类似的一百万次计算以及它可能需要的时间!)。XLA负责速度和性能。
#2. 加速线性代数
让我们采用前面的等式。如果没有XLA,计算将需要三个(或更多)内核,其中每个内核将执行一个较小的任务。例如,
内核k1 -> x * 2y(乘法)
k2 -> x * 2y + z(加法)
k3 -> 简化
如果XLA执行相同的任务,则单个内核通过融合它们来处理所有中间操作。基本操作的中间结果被流式传输,而不是将它们存储在内存中,从而节省内存并提高速度。
#3. 即时编译
JAX在内部使用XLA编译器来提高执行速度。XLA可以提升CPU、GPU和TPU的速度。所有这些都可以使用JIT代码执行来实现。要使用它,我们可以通过import使用jit:
from jax import jit
def my_function(x):
……一些代码行
my_function_jit = jit(my_function)
另一种方法是在函数定义上装饰jit:
@jit
def my_function(x):
……一些代码行
这段代码要快得多,因为转换会将代码的编译版本返回给调用者,而不是使用Python解释器。这对于向量输入特别有用,例如数组和矩阵。
所有现有的python函数也是如此。例如,来自NumPy包的函数。在这种情况下,我们应该将jax.numpy导入为jnp而不是NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
完成此操作后,称为DeviceArray的核心JAX数组对象将替换标准NumPy数组。DeviceArray是惰性的 – 值保存在加速器中,直到需要。这也意味着JAX程序不等待结果返回到调用(Python)程序,因此遵循异步调度。
#4. 自动向量化 (vmap)
在典型的机器学习世界中,我们拥有包含一百万个或更多数据点的数据集。最有可能的是,我们会对这些数据点中的每一个或大部分执行一些计算或操作-这是一项非常耗时和耗费内存的任务!例如,如果您想找到数据集中每个数据点的平方,您首先想到的是创建一个循环并逐个取平方 – 啊!
如果我们把这些点创建为向量,我们可以通过使用我们最喜欢的NumPy对数据点执行向量或矩阵操作,一次性完成所有的平方。如果您的程序可以自动执行此操作,您还能要求更多吗?这正是JAX所做的!它可以自动矢量化您的所有数据点,因此您可以轻松地对它们执行任何操作-使您的算法更快、更高效。
JAX使用vmap函数进行自动矢量化。考虑以下数组:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
通过执行上述操作,将针对数组中的每个点执行square方法。但是,如果您执行以下操作:
vmap(jnp.square(x))
square方法将只执行一次,因为现在在执行函数之前使用vmap方法自动对数据点进行矢量化,并且循环被下推到基本操作级别 – 导致矩阵乘法而不是标量乘法,从而提供更好的性能。
#5. SPMD 编程 (pmap)
SPMD——或单程序多数据编程在深度学习环境中是必不可少的——您经常将相同的函数应用于驻留在多个GPU或TPU上的不同数据集。JAX有一个名为pmap的函数,它允许在多个GPU或任何加速器上进行并行编程。与JIT一样,使用pmap的程序将由XLA编译并跨系统同时执行。这种自动并行化适用于正向和反向计算。
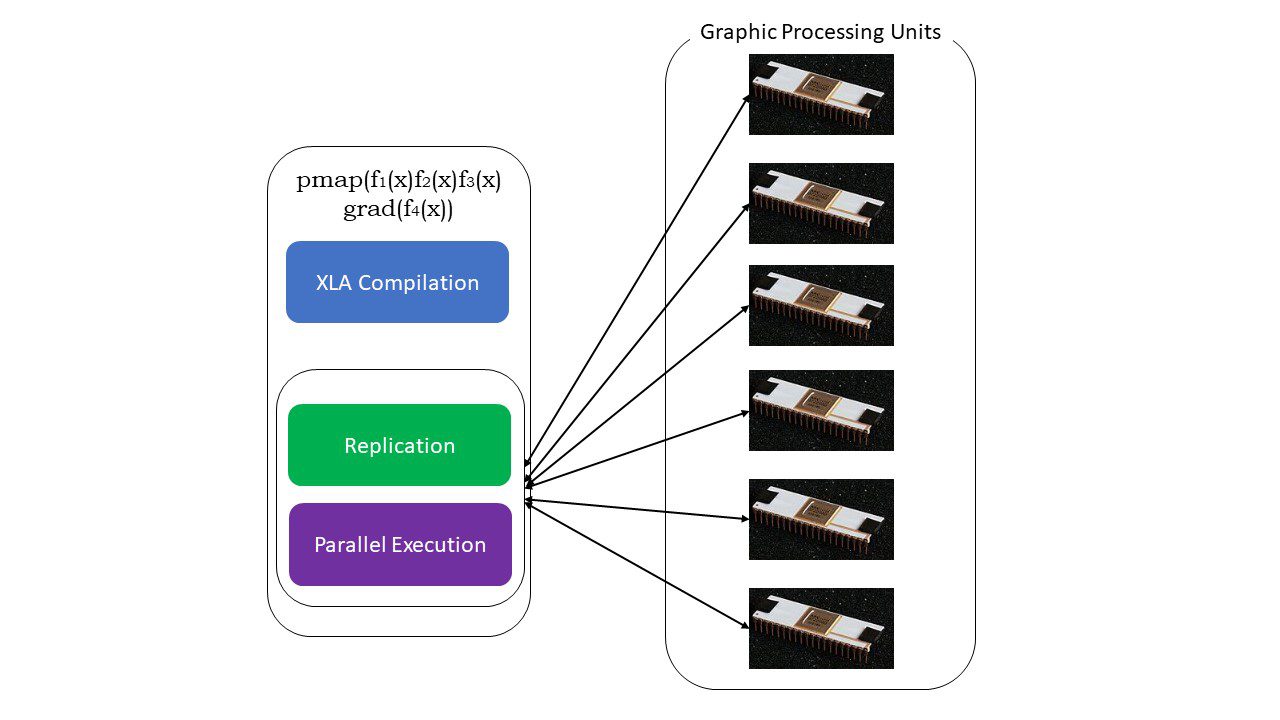
pmap是如何工作的
我们还可以在任何函数上以任何顺序一次性应用多个转换:
pmap(vmap(jit(grad(f(x)))))
多个可组合的转换
Google JAX 的限制
Google JAX开发人员在引入所有这些令人敬畏的转换的同时,已经很好地考虑了加速深度学习算法。科学计算函数和包都在NumPy的线上,所以你不必担心学习曲线。但是,JAX有以下限制:
- Google JAX仍处于早期发展阶段,虽然其主要目的是性能优化,但它并没有为CPU计算带来太多好处。NumPy似乎性能更好,使用JAX可能只会增加开销。
- JAX仍处于研究或早期阶段,需要更多微调才能达到TensorFlow等框架的基础设施标准,这些框架更成熟,有更多的预定义模型、开源项目和学习材料。
- 截至目前,JAX不支持Windows操作系统 – 您需要一个虚拟机才能使其工作。
- JAX仅适用于纯函数 – 那些没有任何副作用的函数。对于有副作用的函数,JAX可能不是一个好的选择。
如何在 Python 环境中安装 JAX
如果您在系统上安装了python并希望在本地计算机(CPU)上运行JAX,请使用以下命令:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
如果您想在GPU或TPU上运行Google JAX,请按照GitHub JAX页面的说明进行操作。要设置Python,请访问python官方下载页面。
结论
Google JAX非常适合编写高效的深度学习算法、机器人技术和研究。尽管有这些限制,但它被广泛用于其他框架,如Haiku、Flax等。当您运行程序时,您将能够欣赏JAX所做的事情,并了解使用和不使用JAX执行代码的时间差异。您可以从阅读官方Google JAX文档开始,该文档比较全面。