使用自然语言分析数据:PandasAI 教程
您是否对使用自然语言分析数据感兴趣?本文将引导您了解如何利用 Python 库 PandasAI 实现这一目标。
在当今数据驱动的世界中,理解和分析数据至关重要。然而,传统的数据分析方法往往复杂且耗时。PandasAI 的出现改变了这一现状,它允许您通过自然语言与数据互动,从而简化了数据分析过程。
PandasAI 的核心功能是将您提出的问题转化为可执行的数据分析代码。 它构建在流行的 Python 数据分析库 Pandas 之上,并在此基础上扩展了生成式 AI 功能。 它的目标是增强 Pandas 的功能,而不是取代它。
PandasAI 为 Pandas(以及其他广泛使用的数据分析库)引入了对话功能,使得用户能够通过自然语言查询与数据进行交互。
本教程将详细介绍如何设置 PandasAI、将其应用于实际数据集、生成图表、探索快捷方式以及了解这个强大工具的优点和局限性。
完成本教程后,您将掌握使用自然语言更轻松、直观地进行数据分析的能力。
现在,让我们一起踏上 PandasAI 自然语言数据分析的探索之旅吧!
配置您的环境
要开始使用 PandasAI,首先需要安装 PandasAI 库。
本文示例使用 Jupyter Notebook,您也可以根据自己的喜好选择 Google Colab 或 VS Code 等环境。
如果您计划使用 OpenAI 大型语言模型(LLM),则还需要安装 OpenAI Python SDK 以获得更流畅的体验。
# 安装 Pandas AI !pip install pandas-ai # Pandas AI 使用 OpenAI 的语言模型,因此需要安装 OpenAI Python SDK !pip install openai
接下来,导入所有必要的库:
# 导入必要的库 import pandas as pd import numpy as np # 导入 PandasAI 及其组件 from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
使用 PandasAI 进行数据分析的关键因素之一是 API 密钥。该工具支持多种大型语言模型(LLM)和 LangChain 模型,以便从自然语言查询生成代码,从而使数据分析更加便捷和用户友好。
PandasAI 具有广泛的兼容性,可以与各种模型协同工作,包括 Hugging Face 模型、Azure OpenAI、Google PALM 和 Google VertexAI。每个模型都有其独特的优势,从而增强了 PandasAI 的整体功能。
请注意,使用这些模型时,您需要有效的 API 密钥。这些密钥用于验证您的请求,并允许您在数据分析任务中利用这些高级语言模型的强大功能。因此,在配置 PandasAI 时,请确保您已准备好相应的 API 密钥。
您可以获取 API 密钥,并将其设置为环境变量。
接下来,您将学习如何将 PandasAI 与 OpenAI 和 Hugging Face Hub 的不同大型语言模型(LLM)结合使用。
使用大型语言模型
您可以通过实例化 LLM 并将其传递给 SmartDataFrame 或 SmartDatalake 构造函数来选择 LLM,或者在 `pandasai.json` 文件中指定 LLM。
如果模型需要一个或多个参数,您可以将其传递给构造函数或在 `pandasai.json` 文件的 `llm_options` 参数中指定,如下所示:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
如何使用 OpenAI 模型?
要使用 OpenAI 模型,您需要一个 OpenAI API 密钥。您可以从此处获取。
获取 API 密钥后,您可以使用它来实例化 OpenAI 对象:
# 我们在前面的步骤中导入了所有必要的库
llm = OpenAI(api_token="my-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
不要忘记将 “my-api-key” 替换为您的实际 API 密钥。
作为替代方案,您可以设置 `OPENAI_API_KEY` 环境变量,并在实例化 OpenAI 对象时无需传递 API 密钥:
# 设置 OPENAI_API_KEY 环境变量
llm = OpenAI() # 无需传递 API 密钥,它将从环境变量中读取
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
如果您位于显式代理后面,则可以在实例化 OpenAI 对象时指定 `openai_proxy` 或设置 `OPENAI_PROXY` 环境变量。
重要提示:在使用 PandasAI 库通过 API 密钥进行数据分析时,跟踪令牌的使用情况以管理成本非常重要。
想知道如何实现吗?只需运行以下令牌计数器代码即可清楚地了解令牌的使用情况和相应的费用。这样,您可以有效地管理资源并避免意外费用。
您可以按以下方式计算提示使用的令牌数量:
"""使用 PandasAI 和 pandas 数据帧的示例"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False 旨在显示较低的使用率和成本
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
print(cb)
您将获得类似的结果:
# 北美国家的 GDP 总和为 19,294,482,071,552。 # 使用的令牌:375 # 提示令牌:210 # 完成令牌:165 # 总成本(美元):0.000750 美元
如果您有信用额度限制,请务必记录您的总费用!
如何使用 Hugging Face 模型?
要使用 Hugging Face 模型,您需要一个 Hugging Face API 密钥。您可以在此处创建一个 Hugging Face 帐户,并在此处获取 API 密钥。
获取 API 密钥后,您可以使用它来实例化其中一个 Hugging Face 模型。
目前,PandasAI 支持以下 Hugging Face 模型:
- Starcoder: bigcode/starcoder
- Falcon: tiiuae/falcon-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="my-huggingface-api-key")
# or
llm = Falcon(api_token="my-huggingface-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
作为替代方案,您可以设置 `HUGGINGFACE_API_KEY` 环境变量并在实例化 Hugging Face 对象时无需传递 API 密钥:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # 无需传递 API 密钥,它将从环境变量中读取
# or
llm = Falcon() # 无需传递 API 密钥,它将从环境变量中读取
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder 和 Falcon 都是 Hugging Face 上可用的 LLM 模型。
我们已成功配置了环境并探索了如何使用 OpenAI 和 Hugging Face LLM 模型。现在,让我们继续我们的数据分析之旅。
我们将使用 Big Mart Sales 数据集,其中包含有关 Big Mart 不同商店的各种产品的销售信息。该数据集有 12 列和 8524 行。 您将在文章末尾找到数据集链接。
使用 PandasAI 进行数据分析
现在,我们已经成功安装并导入了所有必要的库,接下来加载数据集。
加载数据集
您可以通过实例化 LLM 并将其传递给 SmartDataFrame 来选择 LLM。 您可以在文章末尾获取数据集的链接。
# 从设备加载数据集 path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
使用 OpenAI 的 LLM 模型
加载数据后,我们就可以开始使用 OpenAI 的 LLM 模型与 PandasAI 进行交互了。
llm = OpenAI(api_token="API_Key") pandas_ai = PandasAI(llm, conversational=False)
一切就绪!现在,让我们尝试使用提示。
打印数据集的前 6 行
让我们尝试通过发出指令来加载前 6 行:
Result = pandas_ai(df, "以表格形式显示数据的前 6 行") Result
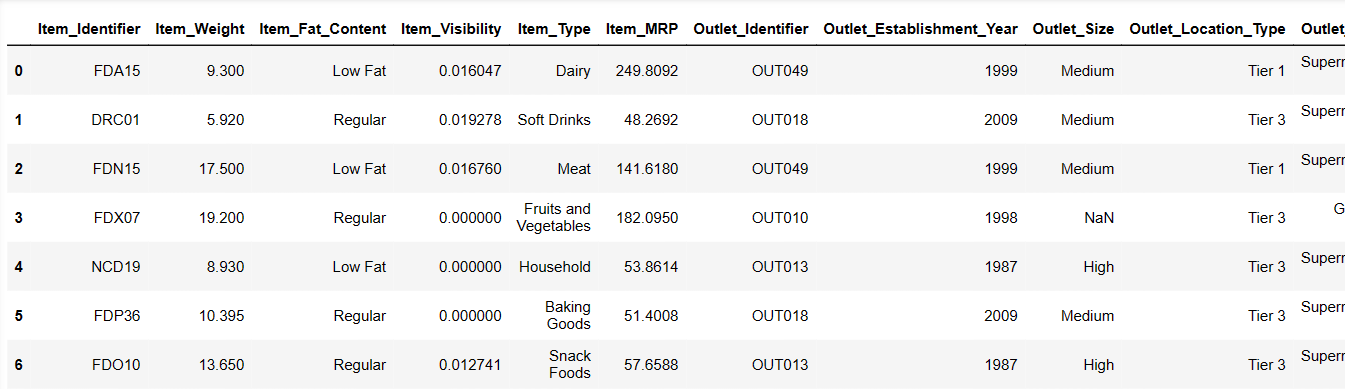 数据集中的前 6 行
数据集中的前 6 行
速度真快!现在,让我们深入了解数据集。
生成 DataFrame 的描述性统计数据
# 获取描述性统计数据 Result = pandas_ai(df, "以表格形式显示数据的描述") Result
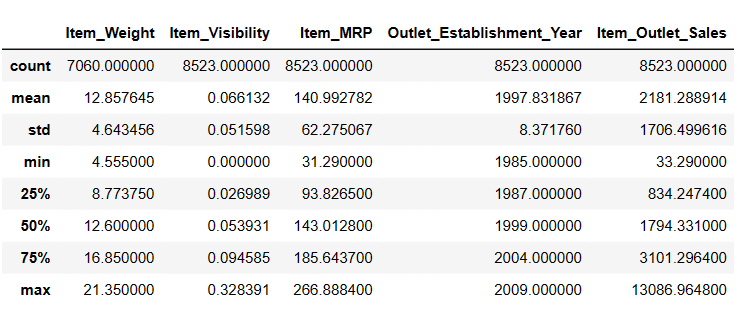 描述
描述
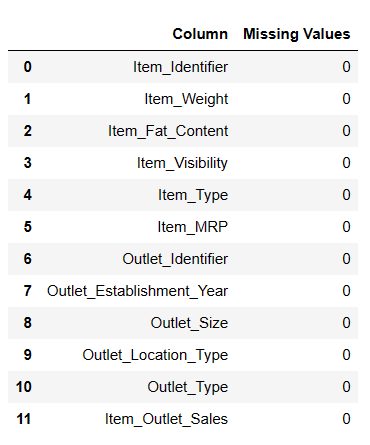
Item_Weight 列中有 7060 个值;可能存在一些缺失值。
查找缺失值
可以使用 PandasAI 通过两种方法查找缺失值。
# 查找缺失值 Result = pandas_ai(df, "以表格形式显示数据的缺失值") Result
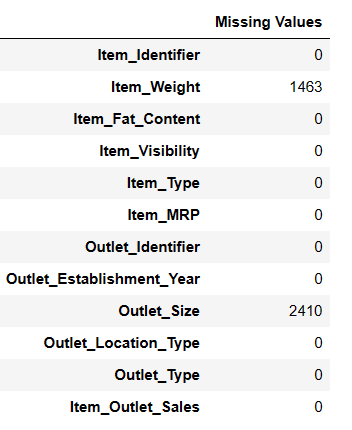 查找缺失值
查找缺失值
数据清理快捷方式
df = SmartDataframe('data.csv')
df.clean_data()
此快捷方式将对数据框进行数据清理。
现在,让我们填充缺失的空值。
填充缺失值
# 填充缺失值 result = pandas_ai(df, "用中位数填充 Item Weight,用众数填充 Item outlet size 的空值,并以表格形式显示数据的缺失值") result
 填充空值
填充空值
这是一种填充空值的有效方法,但我发现在填充空值时遇到了一些问题。
填充空值的快捷方式
df = SmartDataframe('data.csv')
df.impute_missing_values()
此快捷方式将估算数据框中的缺失值。
删除空值
如果要从 df 中删除所有空值,则可以尝试此方法。
result = pandas_ai(df, "删除具有缺失值的行,并使用 inplace=True") result
数据分析对于识别短期和长期趋势至关重要,这对于企业、政府、研究人员和个人来说都是非常有价值的。
让我们来看看自成立以来这些年的整体销售趋势。
寻找销售趋势
# 查找销售趋势 result = pandas_ai(df, "自商店成立以来,这些年的整体销售趋势是什么?") result
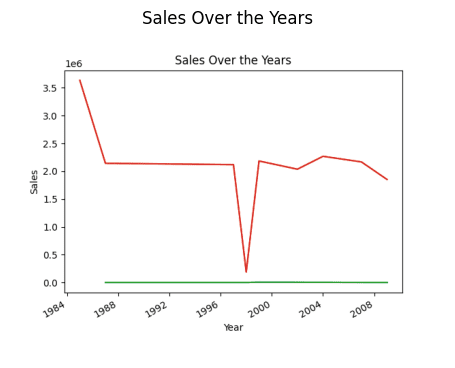 全年销售额(折线图)
全年销售额(折线图)
最初的绘图过程有点慢,但是重新启动内核并全部运行后,它运行得更快了。
绘制折线图的快捷方式
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
此快捷方式将绘制数据框的折线图。
您可能想知道为什么趋势会下降。这是因为我们没有 1989 年至 1994 年的数据。
查找销售额最高的年份
现在,让我们看看哪一年的销售额最高。
# 查找销售额最高的年份 result = pandas_ai(df, "解释一下哪些年份的销售额最高") result

因此,1985 年的销售额最高。
但是,我想找出哪种商品类型产生最高的平均销售额,以及哪种类型产生最低的平均销售额。
最高和最低平均销售额
# 查找最高和最低的平均销售额 result = pandas_ai(df, "哪种商品类型的平均销售额最高,哪种最低?") result

淀粉类食品的平均销售额最高,而其他食品的平均销售额最低。如果不想让其他人成为最低的销售额,您可以根据需要调整提示。
太棒了!现在,我想了解不同销售点的销售额分布情况。
不同网点销售额分布
商店有四种类型:超市类型 1/2/3 和杂货店。
# 自成立以来不同网点类型的销售额分布 response = pandas_ai(df, "使用条形图可视化自成立以来不同网点类型的销售额分布,图表大小为 (13,10)") response
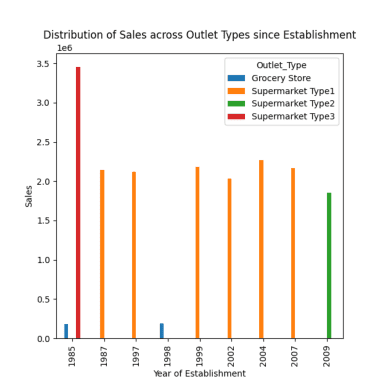 不同网点的销售额分布
不同网点的销售额分布
正如先前的提示所观察到的,销售额在 1985 年达到顶峰,该图显示 3 类超市商店在 1985 年的销售额最高。
绘制条形图的快捷方式
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
此快捷方式将绘制数据框的条形图。
绘制直方图的快捷方式
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
此快捷方式将绘制数据框的直方图。
现在,让我们了解“低脂”和“常规”脂肪含量商品的平均销售额是多少。
查找含有脂肪成分的商品的平均销售额
# 使用列的值查找行的索引 result = pandas_ai(df, "脂肪含量为 '低脂' 和 '常规' 的商品的平均销售额是多少?") result
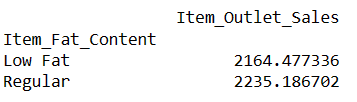
编写类似的提示可以比较两个或多个产品。
每种商品类型的平均销售额
我想将所有产品与其平均销售额进行比较。
# 每种商品类型的平均销售额 result = pandas_ai(df, "过去 5 年中每种商品类型的平均销售额是多少?使用饼图,大小为 (6,6)") result
 平均销售额饼图
平均销售额饼图
饼图的所有部分看起来都很相似,因为它们的销售额几乎相同。
绘制饼图的快捷方式
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
此快捷方式将绘制数据框的饼图。
最畅销的 5 种商品类型
虽然我们已经根据平均销售额比较了所有产品,但现在我想确定销售额最高的前 5 种商品。
# 查找销量最高的前 5 种商品 result = pandas_ai(df, "根据平均销售额,销量最高的前 5 种商品类型是什么?以表格形式书写") result
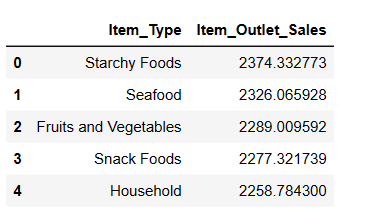
不出所料,淀粉食品的平均销售额最高。
销量最低的 5 种商品类型
result = pandas_ai(df, "根据平均销售额,销量最低的前 5 种商品类型是什么?") result
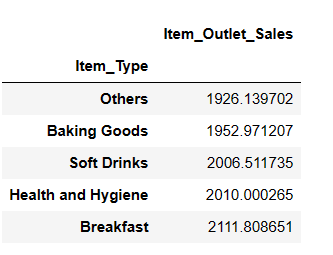
您可能会惊讶地发现软饮料属于销量最低的类别。然而,值得注意的是,该数据仅截至 2008 年,而软饮料的流行趋势是在几年后才开始出现的。
产品类别销售
在这里,我使用了“产品类别”而不是“商品类型”,PandasAI 仍然创建了图表,显示了它对类似词的理解。
result = pandas_ai(df, "给出上一财年各种产品类别的堆叠大尺寸条形图") result
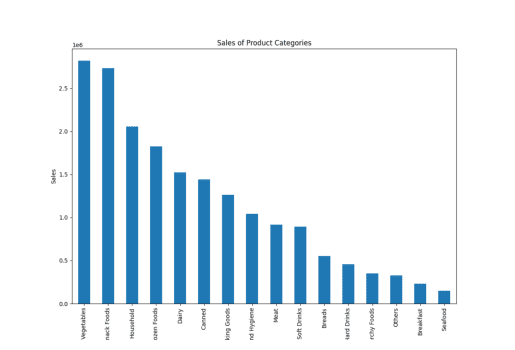 商品类型销售
商品类型销售
您可以在此处找到其余的快捷方式。
您可能会注意到,当我们编写提示并向 PandasAI 提供指令时,它只会根据该特定提示给出结果。它不会分析您以前的提示来给出更准确的答案。
但是,在聊天代理的帮助下,您也可以实现此功能。
聊天代理
通过聊天代理,您可以参与动态对话,代理会在整个讨论过程中保留上下文。这使得您可以进行更多互动和更有意义的交流。
实现这种交互的关键功能包括上下文保留,代理可以记住对话历史记录,从而实现无缝的上下文感知交互。 您可以使用澄清问题方法来要求澄清对话的任何方面,以确保您完全理解所提供的信息。
此外,解释方法可用于获取代理如何得出特定解决方案或响应的详细解释,从而提供对代理决策过程的透明度和洞察力。
请随意开始对话、寻求澄清并探索解释,以增强您与聊天代理的互动!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("MRP 最高的前 5 项商品是什么?")
result
与 SmartDataFrame 或 SmartDatalake 相反,代理将跟踪对话的状态,并且能够回答多轮对话。
让我们看一下 PandasAI 的优点和局限性。
PandasAI 的优势
使用 PandasAI 具有许多优点,使其成为一个有价值的数据分析工具,例如:
- 可访问性:PandasAI 简化了数据分析,使其对更广泛的用户群体可用。 任何用户,无论其技术背景如何,都可以使用它从数据中提取见解并回答业务问题。
- 自然语言查询:使用自然语言查询直接提出问题并从数据中接收答案的能力使数据探索和分析更加用户友好。此功能甚至使非技术用户也能有效地与数据交互。
- 座席聊天功能:聊天功能允许用户以交互方式处理数据,而座席聊天功能则利用以前的聊天历史记录来提供上下文相关的答案。这促进了数据分析的动态和对话方法。
- 数据可视化:PandasAI 提供了一系列数据可视化选项,包括热图、散点图、条形图、饼图、折线图等。这些可视化有助于理解和呈现数据模式和趋势。
- 节省时间的快捷方式:快捷方式和节省时间的功能的可用性简化了数据分析过程,有助于用户更高效地工作。
- 文件兼容性:PandasAI 支持各种文件格式,包括 CSV、Excel、Google Sheets 等。这种灵活性允许用户处理来自各种来源和格式的数据。
- 自定义提示:用户可以使用简单的指令和 Python 代码创建自定义提示。此功能使用户能够自定义与数据的交互以满足特定的需求和查询。
- 保存更改:保存对数据框所做的更改的功能可确保您的工作得到保留,并且您可以随时重新访问和共享分析。
- 自定义响应:创建自定义响应的选项允许用户定义特定的行为或交互,从而使该工具更加通用。
- 模型集成:PandasAI 支持各种语言模型,包括 Hugging Face、Azure、Google Palm、Google VertexAI 和 LangChain 模型。这种集成增强了工具的功能并支持高级自然语言处理和理解。
- 内置 LangChain 支持:对 LangChain 模型的内置支持进一步扩展了可用模型和功能的范围,从而增强了从数据中得出的分析和见解的深度。
- 理解名称:PandasAI 展示了理解列名称和现实生活中术语之间相关性的能力。例如,即使您在提示中使用“产品类别”而不是“商品类型”等术语,该工具仍然可以提供相关且准确的结果。这种识别同义词并将其映射到适当数据列的灵活性增强了用户便利性以及该工具对自然语言查询的适应性。
虽然 PandasAI 具有许多优点,但也存在一些用户应该注意的局限性和挑战:
PandasAI 的局限性
以下是我观察到的一些局限性:
- API 密钥要求:要使用 PandasAI,拥有 API 密钥至关重要。如果您的 OpenAI 帐户中没有足够的积分,您可能无法使用该服务。然而,值得注意的是,OpenAI 为新用户提供了 5 美元的积分,使该平台的新用户也可以使用它。
- 处理时间:有时,服务在提供结果时可能会出现延迟,这可能是由于使用率高或服务器负载造成的。用户在查询服务时应为潜在的等待时间做好准备。
- 提示的解释:虽然您可以通过提示提出问题,但系统解释答案的能力可能尚未完全开发,并且解释的质量可能会有所不同。随着 PandasAI 的进一步发展,这方面未来可能会得到改进。
- 提示敏感度:用户在制作提示时需要小心,因为即使是微小的变化也可能会导致不同的结果。这种对措辞和提示结构的敏感性可能会影响结果的一致性,尤其是在处理数据图表或更复杂的查询时。
- 复杂提示的局限性:PandasAI 可能无法像处理简单提示或查询那样有效地处理高度复杂的提示或查询。用户应该注意问题的复杂性,并确保该工具适合他们的特定需求。
- 不一致的数据帧更改:用户报告了在对数据帧进行更改时遇到问题,例如填充空值或删除空值行,即使指定了 “Inplace=True” 也是如此。这种不一致性可能会让尝试修改数据的用户感到沮丧。
- 可变结果:重新启动内核或重新运行提示时,您可能会收到与先前运行不同的结果或数据解释。对于需要一致且可重现结果的用户来说,这种可变性可能具有挑战性。请注意,并非所有提示都会发生这种情况。
您可以在此处下载数据集。
该代码可在GitHub上找到。
结论
PandasAI 提供了一种用户友好的数据分析方法,即使是没有丰富编码技能的人也可以使用。
在本文中,我介绍了如何设置和利用 PandasAI 进行数据分析,包括创建图表、处理空值以及利用代理聊天功能。
订阅我们的新闻通讯以获取更多信息文章。您可能有兴趣了解用于创建生成式人工智能的人工智能模型。
本文是否有帮助?
感谢您的反馈!