Apache Parquet:优于 CSV 的数据存储新选择
相较于 CSV 等传统方法,Apache Parquet 在数据存储和检索方面展现出诸多优势。 Parquet 格式专为更快处理复杂数据类型而设计。 本文将深入探讨 Parquet 格式如何适应当今不断增长的数据需求。
在详细了解 Parquet 格式之前,我们先简单回顾一下 CSV 数据及其在数据存储方面面临的挑战。
什么是 CSV 存储?
CSV(逗号分隔值)是一种常见的数据组织和格式化方式。CSV 数据存储基于行,文件以 .csv 为扩展名。 我们可以使用 Excel、Google 表格或任何文本编辑器来存储和打开 CSV 数据。打开文件后,数据一目了然。
然而,CSV 并非理想的数据库格式。 随着数据量的增加,查询、管理和检索的难度也会随之增加。
以下是一个存储在 .CSV 文件中的数据示例:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
在 Excel 中查看时,我们可以看到数据呈现为行列结构:
CSV 存储的挑战
基于行的存储(如 CSV)适用于创建、更新和删除操作。 但在读取操作方面却存在挑战。 假设上述 .csv 文件包含一百万行数据。 打开文件并搜索所需数据需要相当长的时间,效率低下。此外,大多数云服务提供商(如 AWS)会根据扫描或存储的数据量向公司收费,而 CSV 文件会占用大量空间。
CSV 存储缺乏存储元数据的能力,使得数据扫描变得繁琐。 那么,是否存在更具成本效益和更优的解决方案来执行 CRUD 操作呢? 让我们继续探索。
什么是 Parquet 数据存储?
Parquet 是一种开源的数据存储格式,广泛应用于 Hadoop 和 Spark 生态系统中。Parquet 文件以 .parquet 为扩展名。
Parquet 是一种高度结构化的格式,可用于优化数据湖中大量存在的复杂原始数据,从而显著减少查询时间。 Parquet 采用行和列(混合)存储格式,提高了数据存储效率和检索速度。 数据在 Parquet 中进行水平和垂直分区,并大大减少了解析开销。 该格式限制了 I/O 操作的总量,从而降低了成本。
Parquet 还存储元数据,包含诸如数据模式、值数量、列位置、最小值、行组最大值、编码类型等信息。 元数据存储在文件的不同级别,从而加快数据访问速度。在基于行的存储(如 CSV)中,数据检索需要遍历每一行并获取特定的列值。 而使用 Parquet 存储,可以一次访问所有需要的列。
总而言之,Parquet 的优点包括:
- 基于列式结构进行数据存储
- 一种优化的数据格式,用于在存储系统中批量存储复杂数据
- 提供多种数据压缩和编码方法
- 与 CSV 等其他存储格式相比,显著减少数据扫描和查询时间,并占用更少的磁盘空间
- 最小化 I/O 操作,降低存储和查询执行成本
- 包含元数据,便于查找数据
- 提供开源支持
Parquet 数据格式
在深入示例之前,我们先更详细地了解 Parquet 格式的数据存储方式。一个 Parquet 文件可以包含多个水平分区,称为行组。 每个行组内进行垂直分区,将列分为若干列块。 数据以页面的形式存储在列块中。 每个页面都包含编码的数据值和元数据。 整个文件的元数据也存储在文件页脚的行组级别。
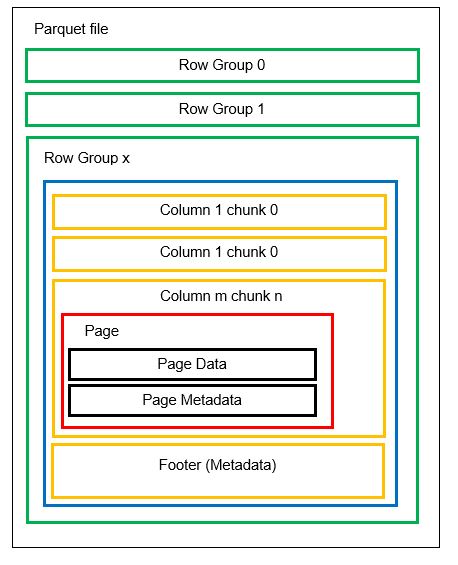
由于数据被拆分为列块,因此可以通过将新值编码到新块和文件中来轻松添加新数据。 然后更新受影响的文件和行组的元数据。 因此,Parquet 是一种非常灵活的格式。 Parquet 原生支持使用页面压缩和字典编码技术来压缩数据。 让我们看一个字典压缩的简单示例:
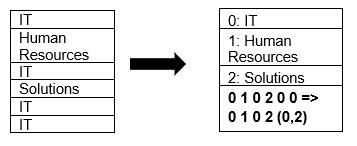
在上面的示例中,我们看到 “IT 部门” 出现了 4 次。 当使用字典进行存储时,该格式会使用另一个易于存储的值 (0,1,2…) 以及连续重复次数对数据进行编码,例如将 IT 替换为 0,2 以节省更多空间。 查询压缩数据所需的时间更少。
正面比较
现在我们对 CSV 和 Parquet 格式有了清晰的了解,是时候通过一些统计数据来比较这两种格式了:
| CSV | Parquet | |
| 存储格式 | 基于行的存储格式 | 混合的行和列式存储格式 |
| 空间占用 | 由于没有默认压缩选项,占用大量空间,例如,一个 1TB 的文件存储在云端时仍然占用 1TB 空间 | 存储时压缩数据,占用更少空间, 例如, 1TB 的文件以 Parquet 格式存储时仅占用 130GB 空间 |
| 查询速度 | 由于基于行的搜索,查询速度较慢, 必须检索每一行数据才能找到特定列的值 | 基于列式存储和元数据,查询速度快约 34 倍 |
| 数据扫描 | 每个查询必须扫描更多数据 | 为执行查询而扫描的数据减少约 99%,从而优化了性能 |
| 存储成本 | 大多数存储设备按存储空间收费,CSV 格式存储成本较高 | 数据以压缩编码格式存储,存储成本较低 |
| 文件模式 | 必须推断文件模式(可能导致错误)或提供(较为繁琐) | 文件模式存储在元数据中 |
| 数据类型 | 适用于简单数据类型 | 适用于嵌套模式、数组、字典等复杂数据类型 |
结论
通过以上对比可以看出,Parquet 在成本、灵活性和性能方面均优于 CSV。 它是一种高效的数据存储和检索机制,尤其是在全球向云存储和空间优化迈进的趋势下。 所有主要平台(如 Azure、AWS 和 BigQuery)都支持 Parquet 格式。