利用 Google 表格进行网页数据抓取
网络数据抓取是一项强大的技术,能够从网站提取信息并自动进行分析。 虽然手动执行此操作是可行的,但它可能是一项单调且耗时的任务。 而网络抓取工具则可以更快、更高效地完成这项工作,同时还能降低成本。
值得注意的是,Google 表格凭借其 IMPORTXML 功能,具备成为一站式网络抓取工具的潜力。 通过 IMPORTXML,您可以轻松地从网页中提取数据,并将其应用于分析、报告或任何其他数据驱动型任务。
Google 表格中的 IMPORTXML 函数
Google 表格内置了一个名为 IMPORTXML 的函数,它允许您从 XML、HTML、RSS 和 CSV 等网络格式导入数据。 如果您希望从网站收集数据,而无需进行复杂的编程,此功能将是您得力的助手。
以下是 IMPORTXML 的基本语法:
=IMPORTXML(url, xpath_query)
- url: 您要从中抓取数据的网页的 URL。
- xpath_query: 定义要提取的数据的 XPath 查询。
XPath(XML 路径语言)是一种用于在 XML 文档(包括 HTML)中进行导航的语言,它允许您指定 HTML 结构中数据的位置。 了解 XPath 查询对于正确使用 IMPORTXML 至关重要。
理解 XPath
XPath 提供了各种函数和表达式来导航和筛选 HTML 文档中的数据。 详细的 XML 和 XPath 指南超出了本文的讨论范围,因此我们将探讨一些基本的 XPath 概念:
- 元素选择:您可以使用 / 和 // 来表示路径,从而选择元素。例如,/html/body/div 会选择文档正文中的所有 div 元素。
- 属性选择:要选择属性,可以使用 @ 符号。例如,//@href 会选择页面上的所有 href 属性。
- 谓词筛选器:您可以使用方括号 [ ] 进行筛选。例如,/div[@class=”container”] 会选择所有 class 属性为 container 的 div 元素。
- 函数:XPath 提供各种函数,例如 contains()、starts-with() 和 text(),以执行特定操作,如检查文本内容或属性值。
到目前为止,您已经了解了 IMPORTXML 语法,获取网站 URL,并且知道要提取哪个元素。 但是,如何获取元素的 XPath 呢?
您不需要记住网站的结构即可使用 IMPORTXML 提取数据。 实际上,每个浏览器都内置一个实用工具,可让您立即复制任何元素的 XPath。
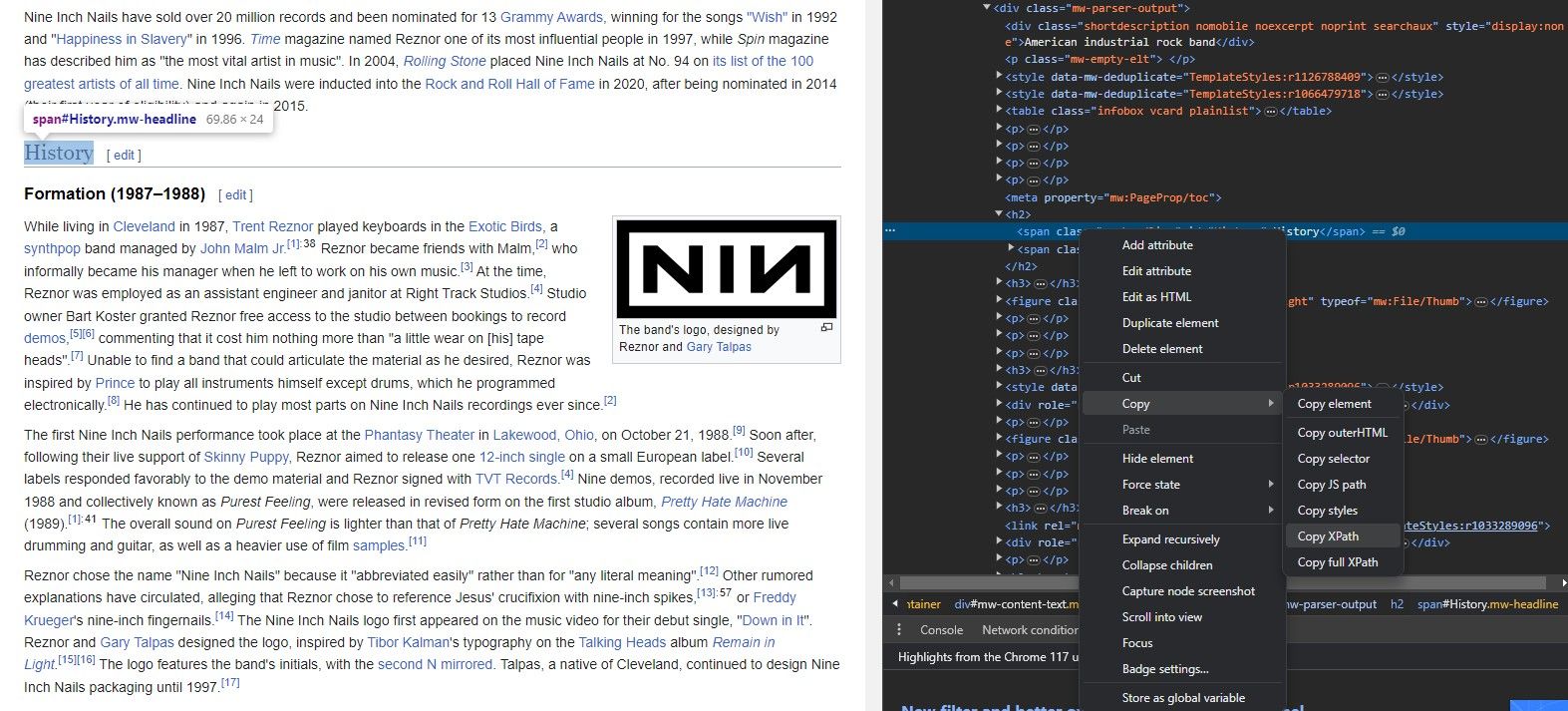
Inspect Element(检查元素)工具可以让您从网站元素提取 XPath,操作方法如下:
现在,您已掌握所有必要的信息,可以实际运用 IMPORTXML 来抓取链接了。
如何使用 IMPORTXML 从网站抓取链接
您可以使用 IMPORTXML 从网站上抓取各种数据,其中包括链接、视频、图像,以及几乎所有网站元素。 链接是网络分析中最重要的元素之一,通过分析网站所链接的页面,您可以了解有关该网站的许多信息。
IMPORTXML 让您可以快速在 Google 表格中抓取链接,并使用 Google 表格的多种功能进一步分析这些链接。
1. 抓取所有链接
要从网页中抓取所有链接,您可以使用以下公式:
=IMPORTXML(url, "//a/@href")
这个 XPath 查询选择所有 元素的 href 属性,从而有效地提取页面上的所有链接。
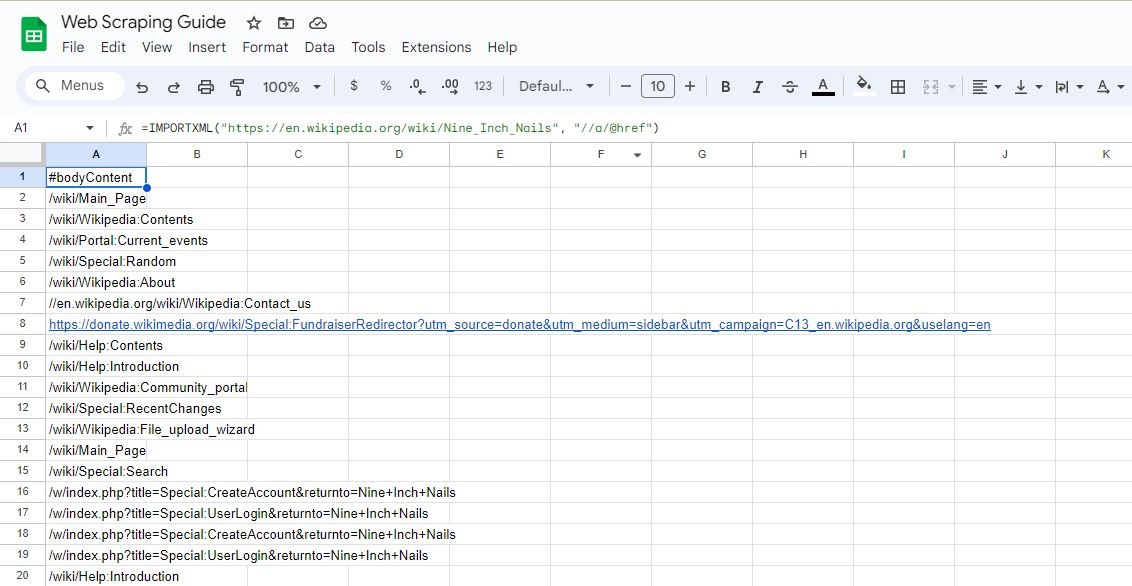
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
上述公式将从维基百科文章中抓取所有链接。
建议将网页 URL 输入到单独的单元格中,然后在公式中引用该单元格。 这样可以避免公式过于冗长和复杂。 您也可以对 XPath 查询执行相同的操作。
2. 抓取所有链接文本
要提取链接的文本及其 URL,您可以使用以下公式:
=IMPORTXML(url, "//a")
此查询选择所有的 元素,您可以从结果中提取链接的文本和 URL。
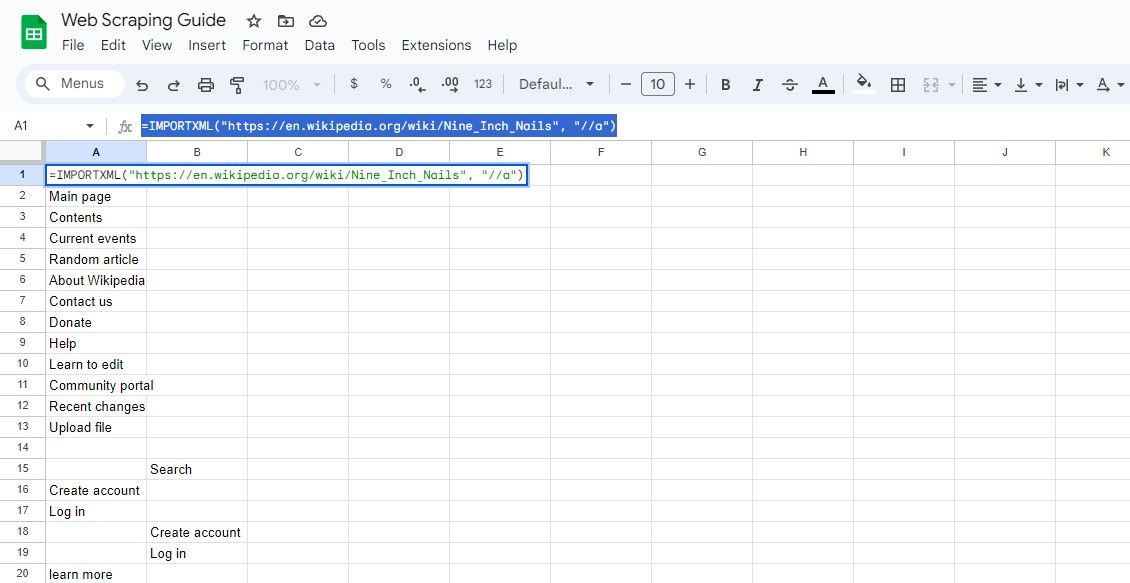
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
上述公式将获取同一篇维基百科文章的链接文本。
如何使用 IMPORTXML 从网站中抓取特定链接
有时,您可能需要根据条件抓取特定的链接。 例如,您可能需要提取包含特定关键字的链接,或提取页面特定部分的链接。
通过对 XPath 的正确理解,您可以精确定位到您要查找的任何元素。
1. 抓取包含关键词的链接
要抓取包含特定关键字的链接,您可以使用 contains() XPath 函数:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
此查询选择 href 属性包含指定关键字的 元素的 href 属性。
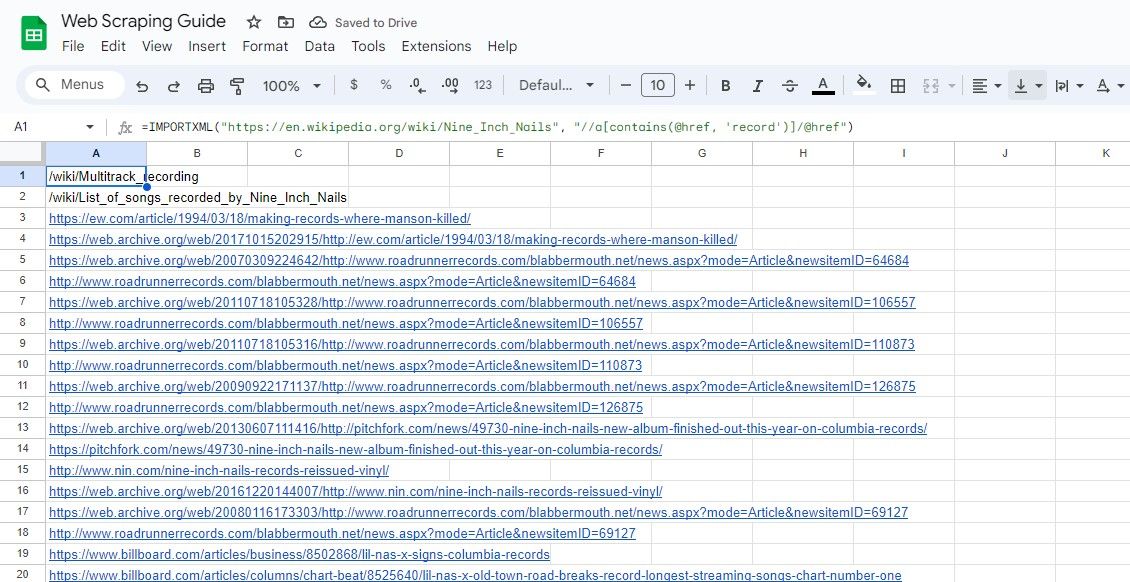
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
以上公式将抓取维基百科示例文章中包含单词 “record” 的所有链接。
2. 抓取节内的链接
要从页面的特定部分抓取链接,您可以指定该部分的 XPath。 例如:
=IMPORTXML(url, "//div[@class='section']//a/@href")
此查询选择 class 属性为 “section” 的 div 元素中所有 元素的 href 属性。
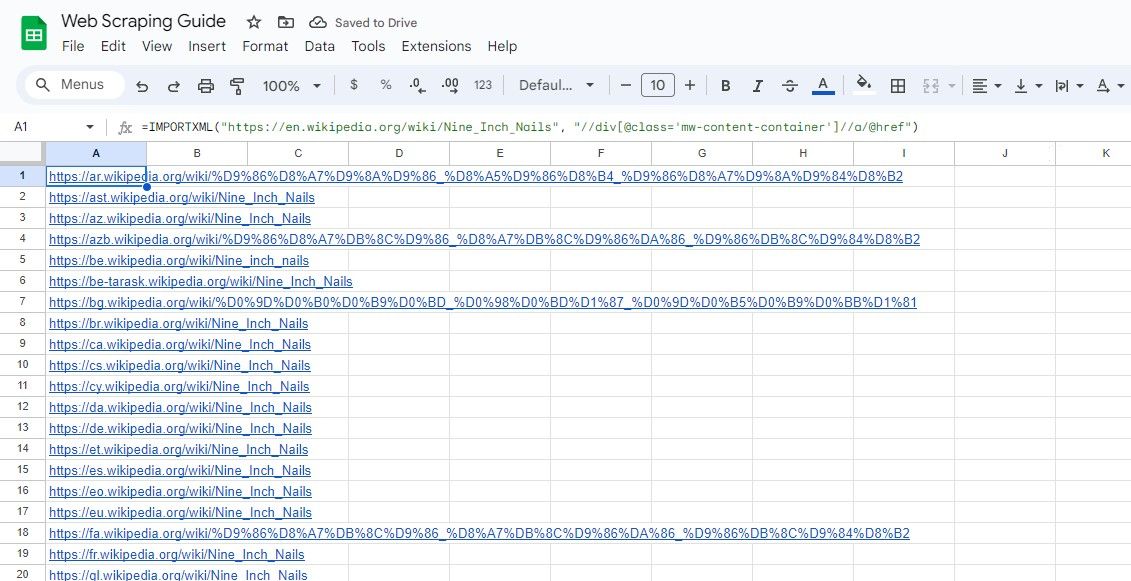
同样,以下公式选择 class 属性为 “mw-content-container” 的 div 元素中的所有链接:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class='mw-content-container']//a/@href")
值得注意的是,IMPORTXML 的用途不仅仅是网络数据抓取。 您可以使用 IMPORT 系列函数将数据表从网站导入 Google 表格。
尽管 Google 表格和 Excel 共享大部分功能,但 IMPORT 系列函数是 Google 表格独有的。 您需要考虑其他方法将数据从网站导入 Excel。
使用 Google 表格简化网页抓取
使用 Google 表格和 IMPORTXML 功能进行网络数据抓取是一种通用且易于上手的方法,可用于从网站收集数据。
通过掌握 XPath 并了解如何构建有效的查询,您可以充分释放 IMPORTXML 的潜力,并从网络资源中获取宝贵的见解。 所以,开始抓取数据,将您的网络分析提升到一个新的水平!