优化应用性能:使用 TanStack 查询实现分页和无限滚动
大多数应用程序都需要处理数据,并且随着应用程序的复杂性增加,数据量也会随之增长。如果应用程序无法高效地管理大量数据,性能就会受到影响。
为了优化应用程序的性能,分页和无限滚动是两种常用的技术。它们可以帮助你更有效地处理数据的渲染,提升整体的用户体验。
利用 TanStack 查询进行分页与无限滚动
TanStack 查询,是 React Query 的一个改编版本,是一个功能强大的 JavaScript 应用程序状态管理库。它为管理应用程序状态提供了有效的解决方案,同时也提供了诸如数据缓存等其他与数据相关的任务。

分页是将大型数据集分割成较小的页面,允许用户通过导航按钮浏览内容。而无限滚动则提供了更为流畅的浏览体验,当用户向下滚动时,新数据会自动加载并显示,无需用户进行额外的操作。
分页和无限滚动旨在更高效地管理和呈现大量数据。具体选择哪一种方法取决于应用程序的数据需求。
你可以在 GitHub 存储库中找到该项目的代码。
搭建 Next.js 项目
首先,我们需要创建一个 Next.js 项目。使用最新版本 Next.js 13,并启用 App 目录。
npx create-next-app@latest next-project --app
接下来,使用 npm 在项目中安装 TanStack 包。
npm i @tanstack/react-query
将 TanStack 查询集成到 Next.js 应用
为了将 TanStack Query 集成到你的 Next.js 项目中,你需要在应用程序的根目录(通常是 `layout.js` 文件)中创建并初始化 TanStack Query 的一个新实例。 从 TanStack Query 导入 `QueryClient` 和 `QueryClientProvider`,然后使用 `QueryClientProvider` 包裹 `children` prop,如下所示:
"use client"
import React from 'react'
import { QueryClient, QueryClientProvider } from '@tanstack/react-query';
const metadata = {
title: 'Create Next App',
description: 'Generated by create next app',
};
export default function RootLayout({ children }) {
const queryClient = new QueryClient();
return (
{children}
);
}
export { metadata };
这个设置确保了 TanStack Query 能够访问应用程序的所有状态。
`useQuery` 钩子简化了数据获取和管理。 通过提供诸如页码之类的分页参数,你可以轻松地检索特定的数据子集。
此外,该钩子还提供了多种选项和配置,可以自定义数据获取功能,包括设置缓存选项以及处理加载状态。 这些功能使得创建无缝的分页体验变得非常简单。
现在,为了在 Next.js 应用程序中实现分页,需要在 `src/app` 目录中创建一个 `Pagination/page.js` 文件。在该文件中,导入必要的模块:
"use client"
import React, { useState } from 'react';
import { useQuery} from '@tanstack/react-query';
import './page.styles.css';
然后,定义一个 React 函数组件。 在该组件中,定义一个从外部 API 获取数据的函数。这里我们使用 JSONPlaceholder API 来获取一组帖子。
export default function Pagination() {
const [page, setPage] = useState(1);
const fetchPosts = async () => {
try {
const response = await fetch(`https://jsonplaceholder.typicode.com/posts?
_page=${page}&_limit=10`);
if (!response.ok) {
throw new Error('Failed to fetch posts');
}
const data = await response.json();
return data;
} catch (error) {
console.error(error);
throw error;
}
};
}
现在,定义 `useQuery` 钩子,并传入一个对象作为参数:
const { isLoading, isError, error, data } = useQuery({
keepPreviousData: true,
queryKey: ['posts', page],
queryFn: fetchPosts,
});
`keepPreviousData` 设置为 `true`,确保应用程序在获取新数据时保留旧数据。`queryKey` 参数是一个包含查询键的数组,这里包括端点和当前页面。 `queryFn` 参数是 `fetchPosts` 函数,用来触发数据获取。
该钩子会返回几种不同的状态,你可以利用这些状态来改善用户体验(例如,渲染合适的 UI)。这些状态包括 `isLoading`、`isError` 等等。
为了实现这一点,可以加入以下代码,根据当前进程的不同状态显示不同的消息:
if (isLoading) {
return (<h2>Loading...</h2>);
}
if (isError) {
return (<h2 className="error-message">{error.message}</h2>);
}
最后,添加将在浏览器页面上渲染的 JSX 元素。 代码还包含以下两个功能:
- 从 API 获取到帖子后,它们会被存储在 `useQuery` 钩子返回的 `data` 变量中。 你可以使用此变量来管理应用程序的状态。 然后,你可以映射 `data` 变量中的帖子列表,并在浏览器中显示它们。
- 添加两个导航按钮,分别为“上一页”和“下一页”,允许用户浏览分页数据。
return (
<div>
<h2 className="header">Next.js Pagination</h2>
{data && (
<div className="card">
<ul className="post-list">
{data.map((post) => (
<li key={post.id} className="post-item">{post.title}</li>
))}
</ul>
</div>
)}
<div className="btn-container">
<button
onClick={() => setPage(prevState => Math.max(prevState - 1, 0))}
disabled={page === 1}
className="prev-button"
>Prev Page</button>
<button
onClick={() => setPage(prevState => prevState + 1)}
className="next-button"
>Next Page</button>
</div>
</div>
);
最后,启动开发服务器。
npm run dev
然后,在浏览器中访问 http://localhost:3000/Pagination。
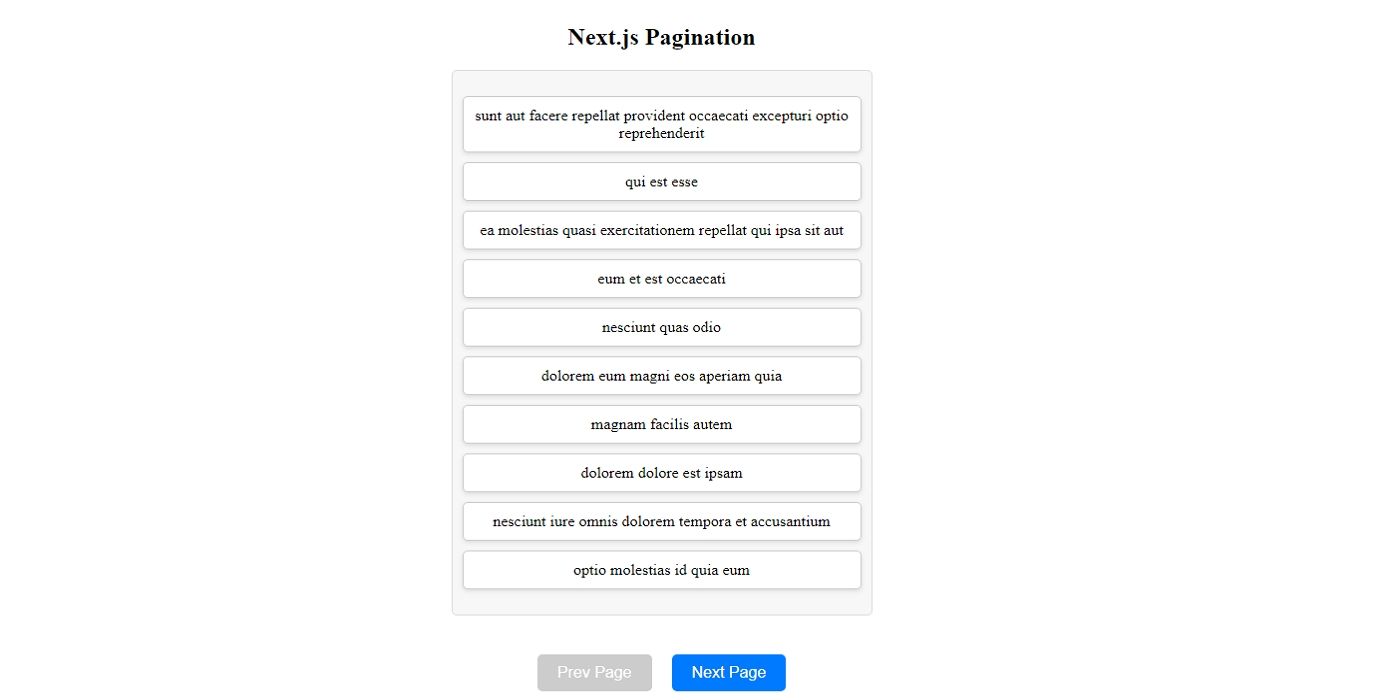
因为你已经在应用程序目录中添加了 `Pagination` 文件夹,Next.js 会将其视为一个路由,允许你访问该 URL 的页面。
无限滚动提供了一种无缝的浏览体验。 例如,YouTube 会在用户向下滚动时自动加载并显示新的视频。
`useInfiniteQuery` 钩子允许你从服务器获取数据,并在用户向下滚动时自动获取并渲染下一页数据,从而实现无限滚动。
为了实现无限滚动,需要在 `src/app` 目录中添加一个 `InfiniteScroll/page.js` 文件。 导入以下模块:
"use client"
import React, { useRef, useEffect, useState } from 'react';
import { useInfiniteQuery } from '@tanstack/react-query';
import './page.styles.css';
接下来,创建一个 React 函数组件。 在该组件中,和分页实现类似,创建一个函数来获取帖子数据。
export default function InfiniteScroll() {
const listRef = useRef(null);
const [isLoadingMore, setIsLoadingMore] = useState(false);
const fetchPosts = async ({ pageParam = 1 }) => {
try {
const response = await fetch(`https://jsonplaceholder.typicode.com/posts?
_page=${pageParam}&_limit=5`);
if (!response.ok) {
throw new Error('Failed to fetch posts');
}
const data = await response.json();
await new Promise((resolve) => setTimeout(resolve, 2000));
return data;
} catch (error) {
console.error(error);
throw error;
}
};
}
和分页实现不同,这段代码在获取数据时引入了两秒的延迟,以便用户在滚动触发重新获取数据时,能够有时间浏览当前数据。
现在,定义 `useInfiniteQuery` 钩子。当组件首次挂载时,钩子将从服务器获取第一页数据。 当用户向下滚动时,钩子会自动获取下一页数据并将其渲染到组件中。
const { data, fetchNextPage, hasNextPage, isFetching } = useInfiniteQuery({
queryKey: ['posts'],
queryFn: fetchPosts,
getNextPageParam: (lastPage, allPages) => {
if (lastPage.length < 5) {
return undefined;
}
return allPages.length + 1;
},
});
const posts = data ? data.pages.flatMap((page) => page) : [];
`posts` 变量将不同页面的所有帖子合并成一个数组,生成 `data` 变量的扁平化版本。这使得映射和渲染各个帖子更加容易。
为了跟踪用户的滚动行为,并在用户接近列表底部时加载更多数据,你可以定义一个函数,使用 Intersection Observer API 来检测元素何时进入视图。
const handleIntersection = (entries) => {
if (entries[0].isIntersecting && hasNextPage && !isFetching && !isLoadingMore) {
setIsLoadingMore(true);
fetchNextPage();
}
};
useEffect(() => {
const observer = new IntersectionObserver(handleIntersection, { threshold: 0.1 });
if (listRef.current) {
observer.observe(listRef.current);
}
return () => {
if (listRef.current) {
observer.unobserve(listRef.current);
}
};
}, [listRef, handleIntersection]);
useEffect(() => {
if (!isFetching) {
setIsLoadingMore(false);
}
}, [isFetching]);
最后,添加 JSX 元素来渲染浏览器中的帖子。
return (
<div>
<h2 className="header">Infinite Scroll</h2>
<ul ref={listRef} className="post-list">
{posts.map((post) => (
<li key={post.id} className="post-item">
{post.title}
</li>
))}
</ul>
<div className="loading-indicator">
{isFetching ? 'Fetching...' : isLoadingMore ? 'Loading more...' : null}
</div>
</div>
);
完成所有修改后,访问 http://localhost:3000/InfiniteScroll 查看效果。
TanStack 查询:不仅仅是数据获取
分页和无限滚动是体现 TanStack Query 功能的优秀示例。 简单来说,它是一个全能的数据管理库。
凭借其广泛的功能,你可以简化应用程序的数据管理流程,包括有效处理状态。 除了其他与数据相关的任务外,你还可以提高 Web 应用程序的整体性能和用户体验。