根据Statista的数据显示,Instagram是全球最庞大的社交媒体平台之一,截至2021年,用户数量达到约12.1亿,这大约占据了互联网用户总数的28%。
本文将指导您如何使用Python,通过两种不同的方式,以编程方式下载Instagram个人资料的数据。第一种方法是利用Instaloader工具下载媒体内容;第二种方法则是编写一个简单的Python脚本,以获取有关个人资料的JSON数据。
请务必注意,数据抓取行为可能违反Instagram的服务条款,我们建议您仅下载自己账户的数据。
使用 Instaloader
Instaloader是一个专门用于下载Instagram媒体的Python包。它操作简便,能够快速便捷地提取并下载所需数据。若要开始使用Instaloader,首先需要使用pip进行安装:
pip install instaloader
安装完成后,您既可以通过命令行界面使用,也可以将其作为Python脚本中的一个包来调用。
若要通过命令行使用,可直接使用`instaloader`命令。例如,若要显示帮助信息,可以在终端输入以下指令:
instaloader --help
若要下载用户的个人资料图片,需要输入带有`–profile`标记的命令,并随后输入用户名,如下所示:
instaloader --profile <目标用户名>
然而,要使此命令生效,您需要先进行登录。为此,需要添加`–login`选项:
instaloader --login <您的用户名> --profile <目标用户名>
下载内容
借助Instaloader,您可以下载多种类型的媒体。以下是手册页的节选,列出了您可以下载的各种内容:
profile 下载个人资料。若已下载的个人资料被重命名,Instaloader会根据其唯一ID自动查找并重命名文件夹。 @profile 下载个人资料关注的所有用户。需要`--login`选项。建议使用`:feed`代替`@yourself`。 "#hashtag" 下载#标签。 %location_id 下载%位置ID。需要`--login`选项。 :feed 下载您的动态中的图片。需要`--login`选项。 :stories 下载您关注用户的快拍。需要`--login`选项。 :saved 下载您标记为保存的帖子。需要`--login`选项。 -- -shortcode 下载具有给定短代码的帖子。 filename.json[.xz] 重新下载给定的对象。 +args.txt 从给定的文本文件中读取目标(和选项)。
若要下载特定用户的帖子,您可以输入如下命令:
instaloader --login <您的用户名> <目标用户名>
其中,您的用户名是经过身份验证的Instagram账户的用户名;目标用户名是您希望下载其帖子的个人资料。
若要下载某个用户关注者的帖子,您可以输入以下命令:
instaloader --login <您的用户名> @<目标用户名>
请注意,此命令与前一个命令的区别在于目标用户名前的`@`。
除了使用Instaloader的命令行界面,您还可以将其作为Python包来使用。该软件包的详细文档在此处。
使用Instaloader,您可以下载各种媒体文件。然而,如果需要提取元数据,例如用户的个人资料页面信息,仅依靠Instaloader是不足够的。接下来介绍的方法中,您将编写一个Python脚本来提取用户个人资料的数据。
编写Python脚本以下载Instagram数据
概述
在本节中,我们将编写一个简单的Python脚本来下载Instagram数据。此方法依赖于利用一个相对不太公开的Instagram JSON API来提取公共个人资料的数据。
该API的工作原理是,如果您在个人资料URL的末尾附加`__a=1&__d=1`查询参数,Instagram将返回关于该个人资料的JSON数据。
例如,我的用户名是`0xanesu`。因此,如果我向`https://instagram.com/instagram/?__a=1&__d=1`发出请求,我将获得关于我的个人资料的JSON数据作为响应。
编写脚本
要在Python中发送请求,我们将使用Python的requests模块。当然,您也可以使用pycURL,urllib或您偏爱的其他任何HTTP客户端库。首先,使用pip安装requests模块:
pip install requests
安装完成后,创建一个文件来编写脚本,并从requests模块导入`get`函数。此外,还要从json模块导入`loads`函数,它将用于解析JSON响应。
from requests import get from json import loads
导入必要模块后,创建一个变量来存储您的Instagram个人资料的URL。
url="https://instagram.com/<您的用户名>"
如前所述,要提取Instagram数据,需要添加`__a=1`和`__d=1`查询参数。为了定义这些参数,我们创建一个带有这些参数的字典对象。
params = { '__a': 1, '__d': 1 }
为了授权我们的请求,Instagram需要会话ID。稍后,我将向您展示如何获取会话ID。现在,只需放置一个占位符值,稍后会被替换。
cookies = { 'sessionid': '<您的会话ID>' }
接下来,定义一个函数,在请求成功时运行。
def on_success(response):
profile_data_json = response.text
parsed_data = loads(profile_data_json)
print('用户全名:', parsed_data['graphql']['user']['full_name'])
print('用户简介:', parsed_data['graphql']['user']['biography'])
我定义的函数会接收响应对象,从响应主体中提取JSON,然后将JSON解析为一个对象。在此之后,我仅提取个人资料的全名和简介。
接下来,定义一个在发生错误时将运行的函数。
def on_error(response):
# 如果出现错误,则打印错误信息
print('发生错误')
print('错误代码:', response.status_code)
print('原因:', response.reason)
然后,我们调用`get`函数来发送请求,将URL、参数和cookie作为参数传递。
response = get(url, params, cookies=cookies)
最后,我们检查错误的状态码。如果状态码为200,我们调用`on_success`函数,否则调用`on_error`函数。
if response.status_code == 200:
on_success(response)
else:
on_error(response)
至此,我们完成了代码的编写。接下来就是获取`sessionid`。要获取会话ID,请打开您的Google Chrome浏览器,并在网页上打开Instagram。请确保您已登录,然后使用`Ctrl + Shift + I`或`Cmd + Shift + I`打开开发者工具。
在打开的开发者工具中,点击“Application”选项卡。
然后单击“Cookies”子菜单,以查看Instagram使用的cookie。
之后,从开发者工具面板中列出的cookie列表中复制`sessionid` cookie的值。
复制会话ID后,将其粘贴到脚本中,然后执行脚本。在我的示例中,使用Instagram作为用户名 (https://instgram.com/instagram?__a=1&__d=1),输出如下所示:
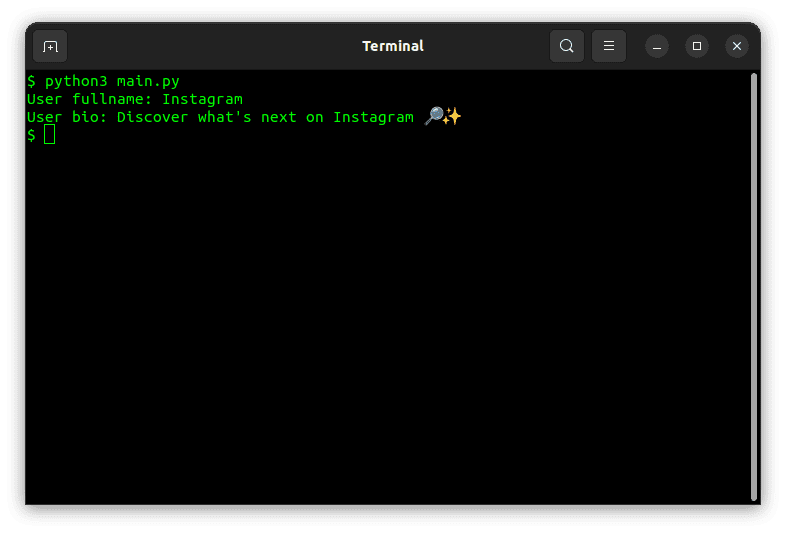
就这样,我们成功地动态下载了个人资料数据。JSON API返回的数据非常丰富,这是打印所有内容时的输出:
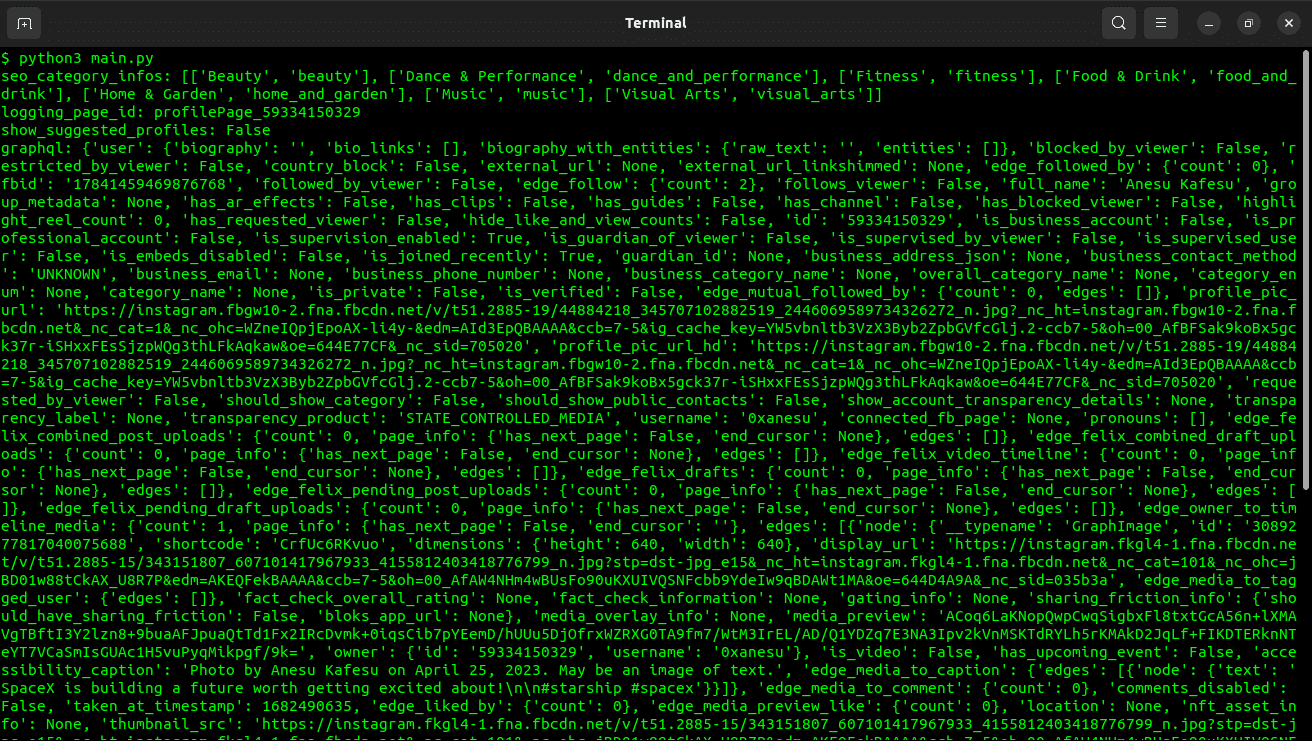
以上就是您如何从Instagram个人资料中提取数据和帖子的方法。
总结
在本文中,我们介绍了如何使用Instaloader下载帖子和媒体内容。此外,我们还编写了一个自定义脚本来提取个人资料的JSON数据,其中包含比媒体内容更丰富的信息。如果您对这个项目感兴趣,您可能还想了解我们关于Python Timeit的文章,它可以帮助您测量代码的运行时间。
如果您有兴趣进一步探索Instagram体验,请查看我们关于Qoob Stories的文章:一篇关于Instagram下载器的详细评论。