使用Python从PDF文档中提取文本、链接和图像的方法
Python作为一种极其灵活的编程语言,经常被开发者用于处理各种类型的文件,并从中提取信息进行进一步的分析和操作。在众多文件格式中,可移植文档格式(PDF)因其通用性而备受青睐。PDF文件不仅能存储文本,还能包含图像和链接等多种元素。当您需要在Python程序中处理数据时,您可能需要从PDF文档中提取这些信息。与列表、元组和字典等数据结构不同,从PDF文件中获取信息看似具有挑战性。
幸运的是,存在许多强大的库,能够帮助我们轻松地处理PDF文件并提取其中存储的数据。下面,我们将深入探讨如何利用这些库从PDF文档中提取文本、链接和图像。为了方便学习,请您下载一个PDF文件,并将其保存在与您的Python程序相同的目录下。
使用PyPDF2提取PDF中的文本
要从PDF文件中提取文本,我们将使用PyPDF2库。PyPDF2是一个免费且开源的Python库,它不仅能合并、裁剪和转换PDF文件的页面,还可以向PDF文件添加自定义数据、查看选项和密码。更重要的是,PyPDF2可以轻松地从PDF文档中提取文本。
为了使用PyPDF2,您需要先使用Python的包管理工具pip来安装它。pip可以帮助您在计算机上轻松安装各种Python包。
安装pip:
1. 首先,您可以通过运行以下命令检查是否已安装pip:
pip --version
如果命令返回版本号,则表明pip已经安装。否则,您需要安装pip。
2. 点击获取pip以下载安装脚本。此链接将打开一个页面,其中包含安装pip的脚本。右键单击该页面并选择“另存为”来保存文件,文件默认名为get-pip.py。
3. 打开终端,导航到您保存get-pip.py文件的目录,并执行以下命令:
sudo python3 get-pip.py
此命令将安装pip,如下所示:
4. 安装完成后,再次运行以下命令以确认pip是否安装成功:
pip --version
如果一切正常,您应该会看到版本号:

使用PyPDF2:
1. 使用以下命令安装PyPDF2:
pip install PyPDF2
2. 创建一个Python文件,并导入PyPDF2库中的PdfReader类:
from PyPDF2 import PdfReader
PyPDF2库提供了多种用于处理PDF文件的类。PdfReader类可以帮助您打开PDF文件、读取内容以及提取文本。
3. 要开始处理PDF文件,您需要先打开它。创建一个PdfReader类的实例,并传入您要使用的PDF文件名:
reader = PdfReader('games.pdf')
上述代码实例化了PdfReader类,并准备好访问指定PDF文件的内容。该实例存储在名为reader的变量中,您可以通过该变量访问PdfReader类提供的各种方法和属性。
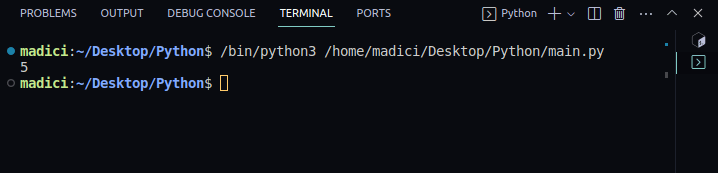
4. 为了验证一切是否正常,您可以使用以下代码打印出PDF文件中的页数:
print(len(reader.pages))
输出:
5
5. 由于我们的PDF文件有5页,我们可以访问每一页。需要注意的是,页码从0开始,这与Python的索引规则一致。因此,PDF文件的第一页的索引为0。要获取PDF文件的第一页,请在代码中添加以下行:
page1 = reader.pages[0]
以上代码将PDF文件的第一页存储在名为page1的变量中。
6. 要提取PDF文件第一页中的文本,请添加以下代码:
textPage1 = page1.extract_text()
这会将PDF第一页中的文本提取出来,并将其存储在名为textPage1的变量中。您可以通过该变量访问第一页的文本内容。
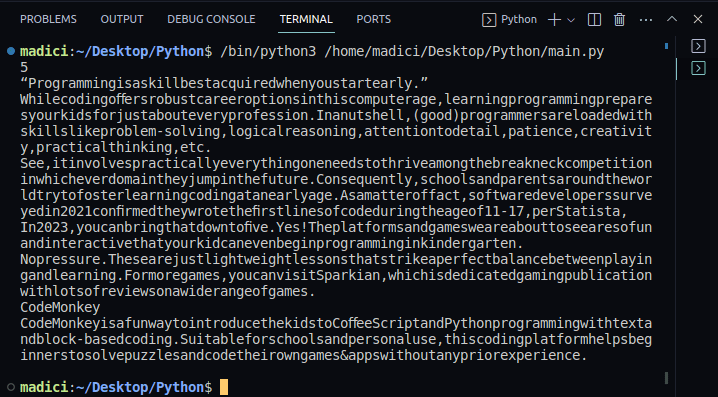
7. 为了确认文本是否成功提取,您可以打印textPage1变量的内容。完整的代码如下所示(同时打印了PDF文件第一页中的文本):
from PyPDF2 import PdfReader
reader = PdfReader('games.pdf')
print(len(reader.pages))
page1 = reader.pages[0]
textPage1 = page1.extract_text()
print(textPage1)
输出:
使用PyMuPDF提取PDF中的链接
接下来,我们将使用PyMuPDF库来提取PDF文件中的链接。PyMuPDF是一个强大的Python库,它可以帮助您提取、分析、转换和操作PDF等文档中的数据。请确保您的Python版本为3.8或更高。
安装和导入:
1. 使用以下命令安装PyMuPDF:
pip install PyMuPDF
2. 在Python文件中导入PyMuPDF库:
import fitz
3. 打开您要提取链接的PDF文件:
doc = fitz.open("games.pdf")
4. 验证PDF文件是否已成功打开,并打印页数:
print(doc.page_count)
输出:
5
提取链接:
1. 加载您要从中提取链接的页面。在本例中,我们加载第一页(索引为0):
page = doc.load_page(0)
2. 提取页面中的所有链接:
links = page.get_links()
所有链接将被存储在名为links的变量中。
3. 打印links变量的内容:
print(links)
输出:
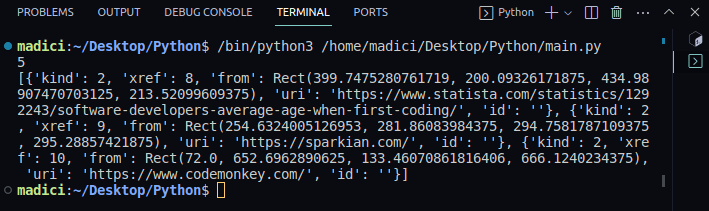
注意,links变量是一个字典列表,其中每个字典代表一个链接,实际的链接存储在”uri”键下。
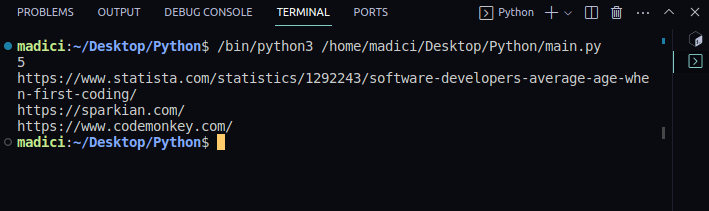
4. 迭代links列表,并打印每个链接的URI:
import fitz
doc = fitz.open("games.pdf")
print(doc.page_count)
page = doc.load_page(0)
links = page.get_links()
for obj in links:
print(obj["uri"])
输出:
5
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/
https://sparkian.com/
https://www.codemonkey.com/
代码优化:
为了使代码更具可复用性,您可以将其重构为两个函数:一个用于提取PDF中的所有链接,另一个用于打印这些链接。
import fitz
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
def print_all_links(links):
for link in links:
print(link["uri"])
all_links = extract_link("games.pdf")
print_all_links(all_links)
输出:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
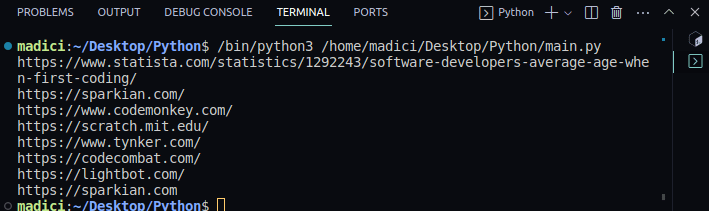
函数 extract_link() 接收一个PDF文件路径作为参数,提取所有链接并返回。函数 print_all_links() 接收链接列表作为参数,并打印每个链接的URI。
使用PyMuPDF和PIL提取PDF中的图像
最后,我们将使用PyMuPDF和PIL库来提取PDF文件中的图像。
导入库:
import fitz
from io import BytesIO
from PIL import Image
在这里,我们导入了PyMuPDF、io库和PIL库(Python Imaging Library)。PIL库提供了图像处理和保存功能,io库可以帮助我们有效地处理二进制数据。
提取图像:
1. 打开您要从中提取图像的PDF文件:
doc = fitz.open("games.pdf")
2. 加载您要从中提取图像的页面:
page = doc.load_page(0)
3. PyMuPDF使用交叉引用号(xref)来标识PDF文件中的图像。我们需要首先获取页面上图像的xref编号:
image_xref = page.get_images()
print(image_xref)
输出:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
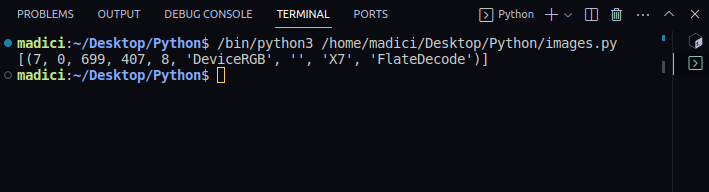
函数 get_images() 返回一个元组列表,其中包含图像的信息。每个元组的第一个元素是图像的xref编号。
4. 从元组列表中提取图像的xref值:
xref_value = image_xref[0][0]
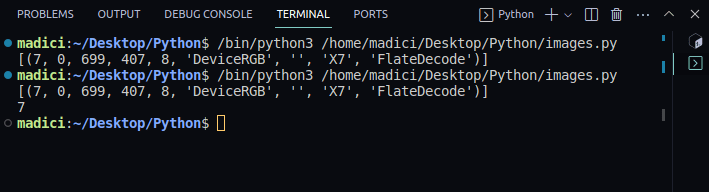
print(xref_value)
输出:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
7
5. 使用xref值提取图像数据:
img_dictionary = doc.extract_image(xref_value)
函数 extract_image() 返回一个字典,其中包含图像的二进制数据和元数据。
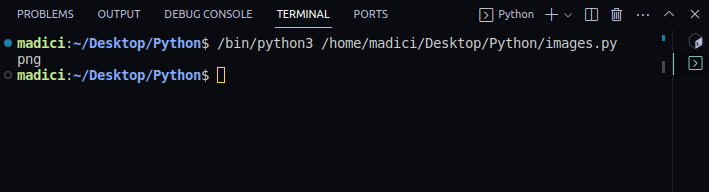
6. 获取图像的文件扩展名:
img_extension = img_dictionary["ext"]
print(img_extension)
输出:
png
7. 获取图像的二进制数据:
img_binary = img_dictionary["image"]
8. 创建一个BytesIO对象,并使用图像的二进制数据初始化它。这会创建一个类似文件的对象,PIL库可以使用它来处理图像:
image_io = BytesIO(img_binary)
9. 使用PIL库打开并解析存储在BytesIO对象中的图像数据。这将创建一个PIL图像对象,我们可以使用该对象来保存图像:
image = Image.open(image_io)
10. 指定要保存图像的路径和文件名:
output_path = "image_1.png"
11. 保存图像,并关闭BytesIO对象:
image.save(output_path)
image_io.close()
完整的代码如下所示:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
image_xref = page.get_images()
xref_value = image_xref[0][0]
img_dictionary = doc.extract_image(xref_value)
img_extension = img_dictionary["ext"]
img_binary = img_dictionary["image"]
image_io = BytesIO(img_binary)
image = Image.open(image_io)
output_path = "image_1.png"
image.save(output_path)
image_io.close()
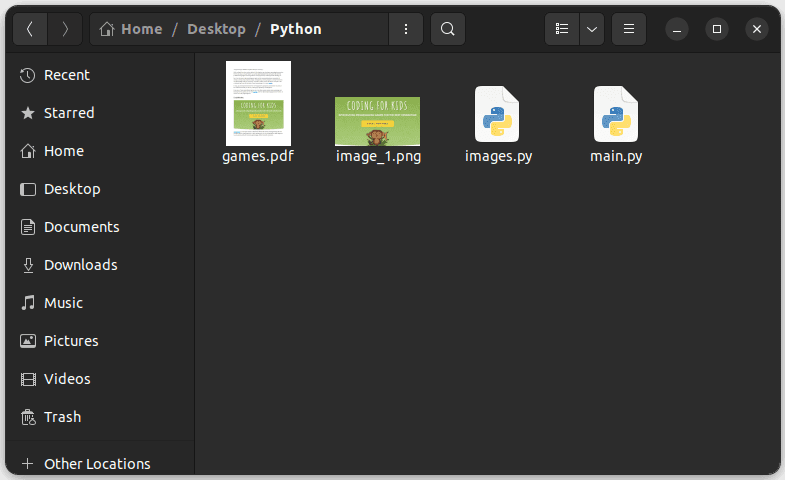
运行代码后,您会在包含Python文件的文件夹中找到名为 image_1.png 的提取图像:
总结
为了进一步练习从PDF文件中提取链接、图像和文本,请尝试重构示例代码,使其更具复用性,就像在链接示例中所做的那样。通过这种方式,您只需传入一个PDF文件,您的Python程序就可以提取整个PDF中的所有链接、图像或文本。希望您编码愉快!
您还可以探索各种适合您业务需求的PDF API。