Llama 2 是由 Meta 开发的一个开源大型语言模型(LLM)。它是一款性能卓越的开源模型,在某些方面甚至超越了一些闭源模型,例如 GPT-3.5 和 PaLM 2。它包含三种不同规模的预训练和微调文本生成模型,参数量分别为 70 亿、130 亿和 700 亿。
本文将指导您如何利用 Streamlit 和 Llama 2 构建聊天机器人,从而探索 Llama 2 的对话能力。
深入了解 Llama 2:特点与优势
Llama 2 与其前身 Llama 1 相比有哪些改进?
- 更大的模型规模:Llama 2 拥有更大的模型,其参数数量高达 700 亿,能够学习单词和句子之间更复杂的关联。
- 增强的对话能力:通过人类反馈强化学习(RLHF),Llama 2 的对话应用能力得到了提升,即使在复杂的交互中也能生成类似人类的文本。
- 更快的推理速度:Llama 2 引入了一种名为分组查询注意力的新技术,加速了推理过程,使其在构建如聊天机器人和虚拟助手等实用应用程序时更加高效。
- 更高的效率:与前代模型相比,Llama 2 在内存和计算资源的使用上更加高效。
- 开源且非商业许可:Llama 2 是开源的,允许研究人员和开发者自由使用和修改。
Llama 2 在各方面都显著超越了其前身。这些特性使得 Llama 2 成为了构建聊天机器人、虚拟助手以及进行自然语言理解等多种应用的强大工具。
为聊天机器人开发配置 Streamlit 环境
在开始构建应用之前,您需要设置一个独立的开发环境,以便将项目与计算机上的其他项目隔离。
首先,使用 Pipenv 库创建一个虚拟环境:
pipenv shell
然后,安装构建聊天机器人所需的必要库:
pipenv install streamlit replicate
Streamlit 是一个开源 Web 应用程序框架,用于快速创建机器学习和数据科学应用。
Replicate 是一个云平台,提供对大型开源机器学习模型的访问,用于部署。
从 Replicate 获取 Llama 2 API 令牌
要获得 Replicate 令牌密钥,您需要先使用 GitHub 账号在 Replicate 上注册。
登录后,导航至“探索”按钮并搜索 Llama 2 chat,找到 llama-2-70b-chat 模型。
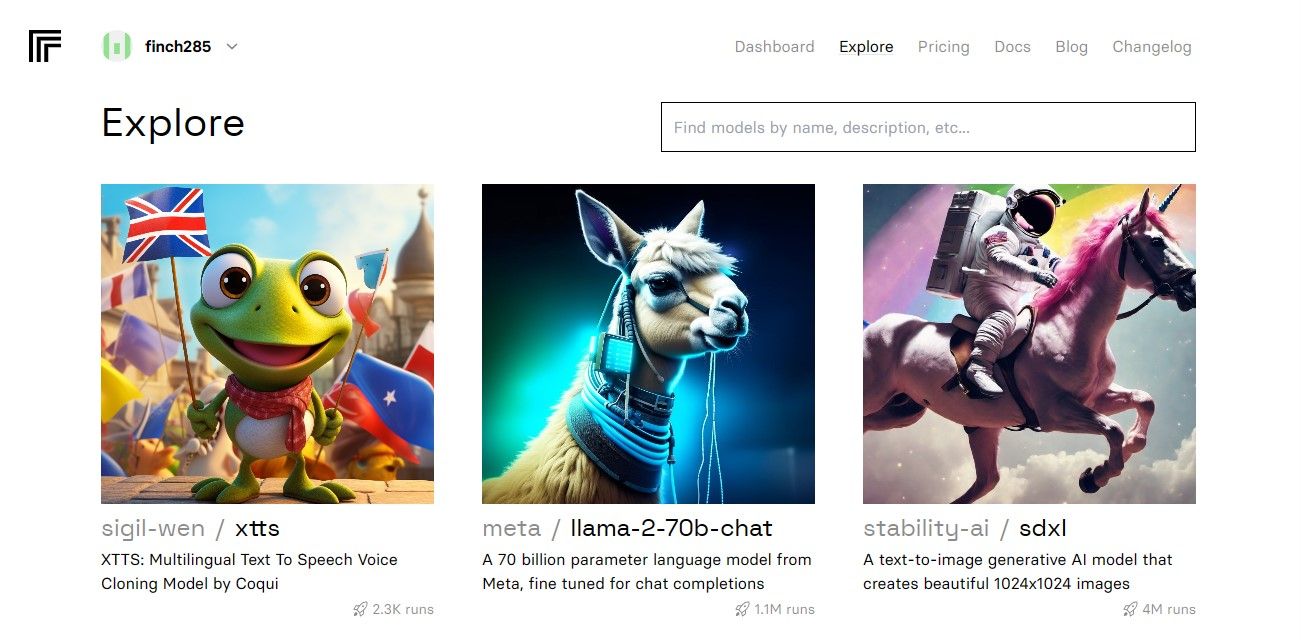
点击 llama-2-70b-chat 模型,进入 Llama 2 API 端点页面。在模型导航栏上点击“API”按钮。在页面右侧,选择“Python”按钮。这将使您能够获取 Python 应用所需的 API 令牌。
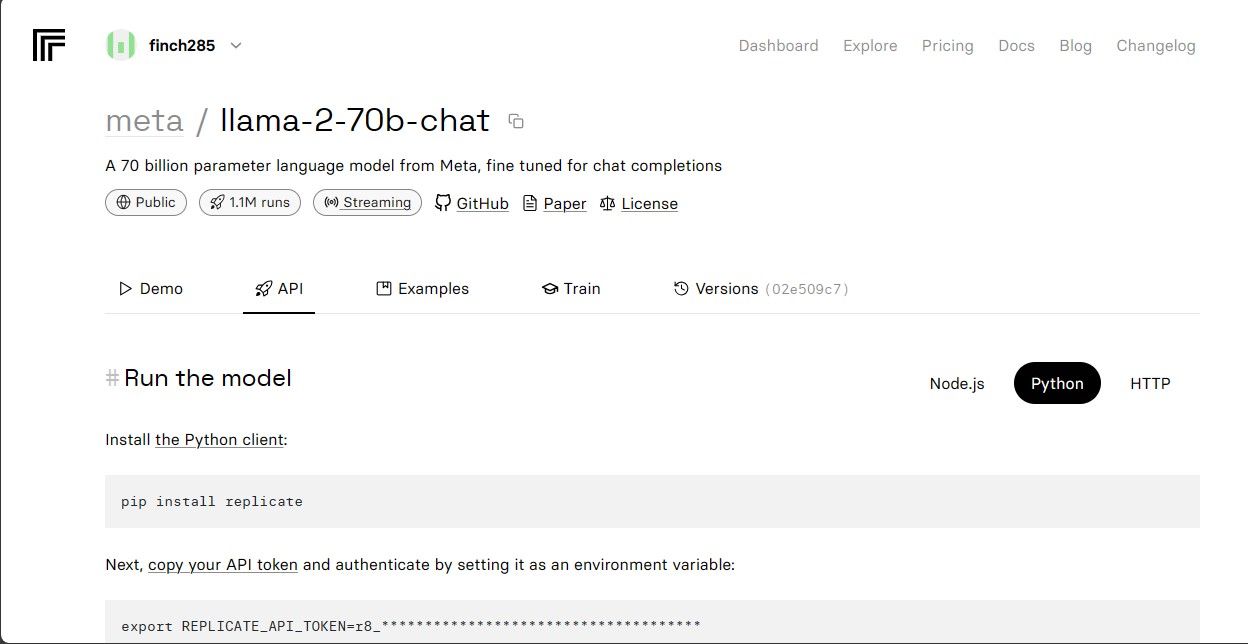
复制 REPLICATE_API_TOKEN 并将其安全保存,以备将来使用。
构建聊天机器人
首先,创建一个名为 llama_chatbot.py 的 Python 文件和一个名为 .env 的环境变量文件。您将在 llama_chatbot.py 文件中编写代码,并将密钥和 API 令牌存储在 .env 文件中。
在 llama_chatbot.py 文件中,导入必要的库:
import streamlit as st
import os
import replicate
接下来,设置 llama-2-70b-chat 模型的全局变量:
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
在 .env 文件中,按以下格式添加 Replicate 令牌和模型端点:
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
粘贴您的 Replicate 令牌并保存 .env 文件。
设计聊天机器人的对话流程
为了启动 Llama 2 模型,需要根据您希望其执行的任务创建预提示。在本例中,您希望模型充当助手:
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
为您的聊天机器人设置页面配置:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
编写一个函数来初始化和设置会话状态变量:
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
该函数设置会话状态中的关键变量,如 chat_dialogue、pre_prompt、llm、top_p、max_seq_len 和 temperature。它还根据用户的选择处理 Llama 2 模型的选择。
编写一个函数来渲染 Streamlit 应用程序的侧边栏内容:
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
该函数显示 Llama 2 聊天机器人的标题,并提供调整变量的选项。
编写一个函数,在 Streamlit 应用的主内容区域中渲染聊天历史记录:
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
该函数遍历会话状态中保存的 chat_dialogue,显示每条消息以及相应的角色(用户或助手)。
使用以下函数处理用户的输入:
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
此函数提供了一个用户可以输入消息和问题的输入字段。用户提交消息后,该消息将以用户角色添加到会话状态的 chat_dialogue 中。
编写一个函数,从 Llama 2 模型生成响应并将其显示在聊天区域中:
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
该函数创建一个包含用户和助手消息的对话历史记录字符串,然后调用 debounce_replicate_run 函数以获取助手的响应。它会持续更新用户界面中的响应,提供实时的聊天体验。
编写主函数来渲染整个 Streamlit 应用程序:
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
它按逻辑顺序调用所有定义的函数,包括设置会话状态、渲染侧边栏、聊天历史记录、处理用户输入和生成助手响应。
编写一个函数来调用 render_app 函数,并在执行脚本时启动应用程序:
def main():
render_app()if __name__ == "__main__":
main()
现在,您的应用程序应该可以运行了。
处理 API 请求
在项目目录中创建一个 utils.py 文件,并添加以下函数:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
该函数执行防抖动机制,以防止对用户输入进行频繁且过多的 API 查询。
接下来,将防抖响应函数导入到 llama_chatbot.py 文件中:
from utils import debounce_replicate_run
现在,运行应用程序:
streamlit run llama_chatbot.py
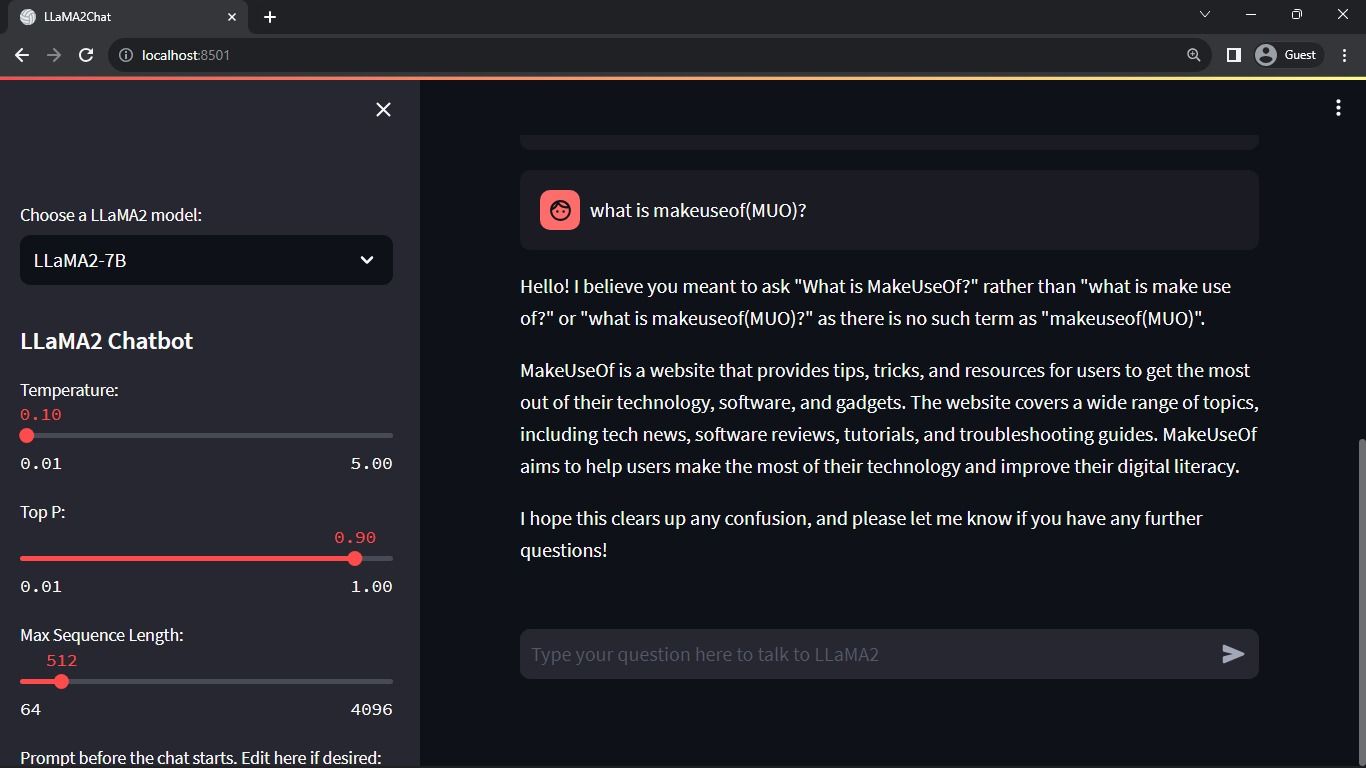
预期输出:
输出将显示模型和用户之间的对话。
Streamlit 和 Llama 2 聊天机器人的实际应用
Llama 2 应用的一些实际示例包括:
- 聊天机器人:可用于创建类似人类的聊天机器人,可以就多个主题进行实时对话。
- 虚拟助手:适用于创建能够理解并响应人类语言查询的虚拟助手。
- 语言翻译:可用于语言翻译任务。
- 文本摘要:适用于将大型文本总结为简短的文本,以便于理解。
- 研究:您可以通过回答一系列主题的问题,应用 Llama 2 进行研究。
人工智能的未来
对于 GPT-3.5 和 GPT-4 等闭源模型,小型企业很难利用 LLM 构建任何实质性内容,因为访问 GPT 模型 API 的成本可能相当昂贵。
向开发者社区开放 Llama 2 等先进的大型语言模型只是人工智能新时代的开始。这将导致在现实世界应用中更具创造性和创新性的模型实施,从而加速实现通用人工智能(ASI)的竞赛。