Linux的stat命令提供的文件信息远比ls命令详尽。这个功能强大且可配置的实用工具能帮助你深入了解系统底层。接下来,我们将详细介绍如何使用它。
深入了解 stat
ls命令在其职责范围内表现出色,但对于Linux来说,总有更深层次的探索空间。这不仅仅是揭开表面的冰山一角,而是可以像剥洋葱一样逐层深入了解Linux系统的内核。
ls命令可以显示文件的多种信息,例如权限设置、大小以及是文件还是符号链接。为了展示这些信息,ls命令会访问称为inode的文件系统结构。
每个文件和目录都有对应的inode。 inode存储着关于文件的元数据,如文件占用的文件系统块以及与文件相关的时间戳。可以将inode比作文件的借书卡。然而,ls命令只显示其中的一部分信息。要查看所有信息,我们需要使用stat命令。
与ls命令类似,stat命令也有许多选项,这使其非常适合使用别名。一旦你找到一组特定的选项,可以使stat为你提供你需要的输出,你可以将它封装在一个别名或shell函数中。这使其使用起来更加方便,并且你无需记住一堆晦涩难懂的命令行选项。
快速对比
让我们使用ls命令,并加上长列表(-l选项)和人类可读的文件大小(-h选项):
ls -lh ana.h

从左到右,ls提供的信息如下:
- 第一个字符是连字符“
-”,表明这是一个常规文件,而不是套接字、符号链接或其他类型的对象。 - 接下来是文件所有者、组和其他用户的权限,以八进制格式显示。
- 指向此文件的硬链接数量,通常情况下是1。
- 文件所有者是戴夫。
- 文件所属的组是戴夫。
- 文件大小为802字节。
- 文件最后一次修改是在2015年12月13日,星期五。
- 文件名为
ana.c。
现在,我们来看看stat命令的输出:
stat ana.h
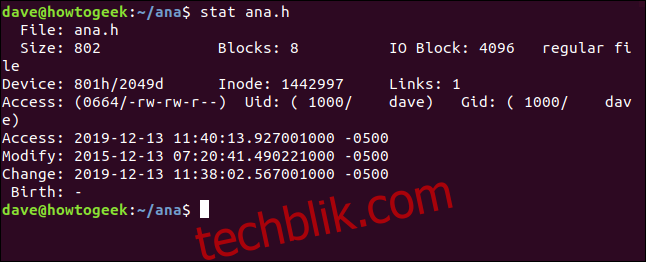
stat命令给出的信息如下:
- 文件:文件的名称。通常情况下,它与我们在命令行中传递给
stat的名称相同。但如果我们查看的是符号链接,它可能会有所不同。 - 大小:文件的大小(以字节为单位)。
- 块:文件在硬盘上存储所需的文件系统块的数量。
- IO 块:文件系统块的大小。
- 文件类型:描述对象类型的元数据。最常见的类型是文件和目录,但也可以是链接、套接字或命名管道。
- 设备:十六进制和十进制的设备号。这是存储文件的硬盘驱动器的ID。
- 索引节点:inode编号。也就是这个inode的ID号。 inode号和设备号一起唯一标识一个文件。
- 链接:表示有多少硬链接指向这个文件。每个硬链接都有自己的inode。因此,另一种理解方式是有多少个inode指向该文件。每次创建或删除硬链接时,此数字都会增加或减少。当它为零时,文件本身已被删除,inode被删除。如果在目录上使用stat,此数字表示目录中的文件数,包括“.”(当前目录的条目)和“..”(父目录的条目)。
- 访问:文件权限以八进制和传统的
rwx(读、写、执行)格式显示。 - Uid:所有者的用户ID和帐户名称。
- Gid:所有者的组ID和帐户名称。
- 访问:访问时间戳。不像看起来那么简单。现代Linux发行版使用一种称为relatime的方案,它试图优化更新访问时间所需的硬盘写入。简单地说,如果访问时间早于修改时间,则更新访问时间。
- 修改:修改时间戳。这是文件内容最后一次修改的时间。(幸运的是,这个文件的内容最后一次更改是四年前到今天。)
- 更改:更改时间戳。这是文件属性或内容最后一次更改的时间。如果通过设置新的文件权限来修改文件,更改时间戳会更新(因为文件属性已更改),但修改后的时间戳不会更新(因为文件内容未更改)。
- Birth:保留用于显示文件的原始创建日期,但该功能在Linux中没有实现。
理解时间戳
时间戳对时区敏感。每行末尾的-0500表示该文件是在计算机上以协调世界时 (UTC) 时区创建的,比当前计算机的时区早五个小时。所以这台电脑比创建这个文件的电脑晚了五个小时。实际上,该文件是在英国时区计算机上创建的,而我们在美国东部标准时区的计算机上查看它。
修改和更改时间戳可能会引起混淆,因为对于非专业人士来说,它们的名称听起来好像含义相同。
让我们使用chmod来修改名为ana.c的文件的文件权限。我们将使它对所有人可写。这不会影响文件的内容,但会影响文件的属性。
chmod +w ana.c
然后,我们将使用stat查看时间戳:
stat ana.c
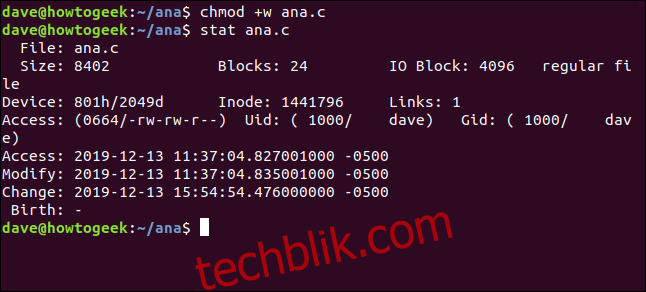
更改时间戳已更新,但修改后的时间戳尚未更新。
只有当文件内容发生更改时,才会更新修改后的时间戳。更改时间戳则会在内容更改和属性更改时更新。
对多个文件使用stat
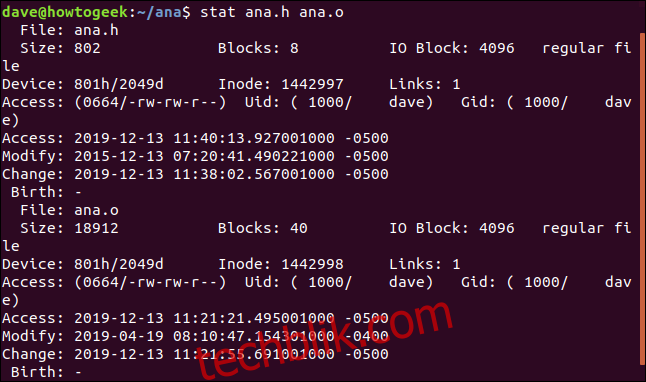
要一次对多个文件进行stat报告,只需在命令行上将文件名传递给stat:
stat ana.h ana.o
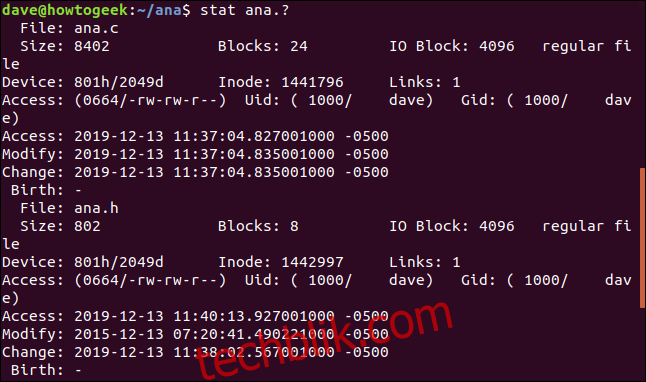
要对一组文件使用stat,请使用模式匹配。问号“?”表示任意单个字符,星号“*”表示任意字符串。我们可以使用以下命令让stat报告任何名为ana且具有单个字母扩展名的文件:
stat ana.?
使用stat报告文件系统
stat可以报告文件系统的状态,以及文件的状态。 -f(文件系统)选项告诉stat报告文件所在的文件系统。 请注意,我们还可以将诸如“/”之类的目录传递给stat,而不是文件名。
stat -f ana.c
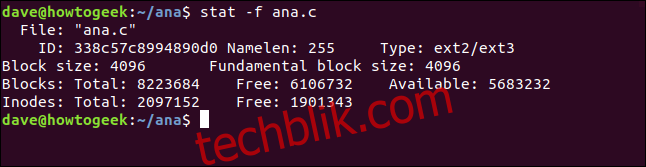
stat给出的信息如下:
- 文件:文件的名称。
- ID:以十六进制表示的文件系统ID。
- Namelen:文件名的最大允许长度。
- 类型:文件系统的类型。
- 块大小:请求读取以获得最佳数据传输速率的数据量。
- 基本块大小:每个文件系统块的大小。
块:
- Total:文件系统中所有块的总数。
- Free:文件系统中的空闲块数。
- 可用:普通(非root)用户可用的空闲块数。
索引节点:
- Total:文件系统中的inode总数。
- Free:文件系统中空闲inode的数量。
取消引用符号链接
如果在实际上是符号链接的文件上使用stat,它将报告该链接的信息。如果希望stat报告链接指向的文件,请使用-L(取消引用)选项。文件code.c是ana.c的符号链接。让我们看看没有-L选项的情况:
stat code.c
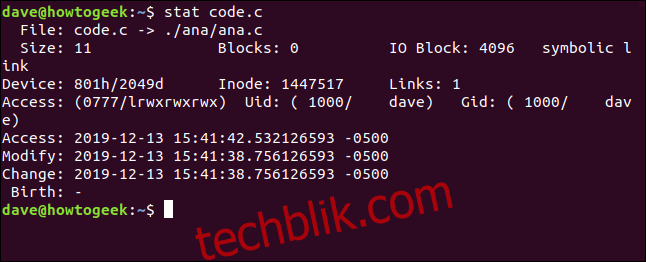
文件名显示code.c指向 (->) ana.c。文件大小只有11个字节。没有专门用于存储此链接的块。文件类型被列为符号链接。
显然,我们在这里看到的不是实际的文件。让我们再次执行此操作,并添加-L选项:
stat -L code.c
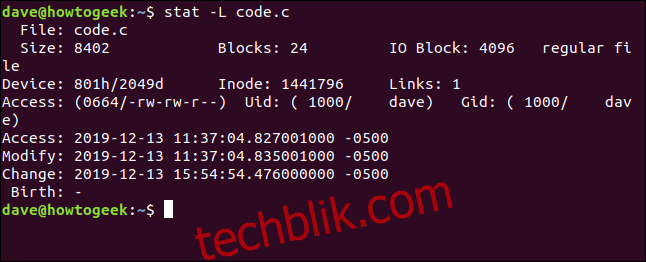
现在显示符号链接指向的文件的详细信息。但是请注意,文件名仍然是code.c。这是链接的名称,而不是目标文件。发生这种情况是因为这是我们在命令行上传递给stat的名称。
简洁报告
-t (简洁) 选项使stat提供一个简洁的摘要:
stat -t ana.c

没有给出任何线索。 为了理解它,直到你记住了字段序列,你需要交叉引用这个输出到完整的统计输出。
自定义输出格式
从stat获取不同数据集的更好方法是使用自定义格式。 有一长串称为格式序列的标记。 这些中的每一个都代表一个数据元素。 选择要包含在输出中的那些,并创建一个格式字符串。 当我们调用stat并将格式字符串传递给它时,输出将只包含我们请求的数据元素。
文件和文件系统有不同的格式序列集。 文件列表如下:
%a:八进制的访问权限。%A:人类可读形式的访问权限(rwx)。%b:分配的块数。%B:每个块的大小(以字节为单位)。%d:十进制的设备号。%D:十六进制的设备号。%f:十六进制的原始模式。%F文件类型。%g:所有者的组ID。%G:所有者的组名。%h:硬链接数。%i:inode编号。%m:挂载点。%n:文件名。%N:引用的文件名,如果是符号链接,则带有取消引用的文件名。%o:最佳I/O传输大小提示。%s:总大小,以字节为单位。%t:十六进制的主要设备类型,用于字符/块设备特殊文件。%T:十六进制的次要设备类型,用于字符/块设备特殊文件。%u:所有者的用户ID。%U:所有者的用户名。%w:文件诞生的时间,人类可读的,如果未知,则为连字符“-”。%W:文件诞生的时间,自Epoch以来的秒数; 0 如果未知。%x:上次访问时间,可读。%X:上次访问的时间,自Epoch以来的秒数。%y:最后一次数据修改的时间,可读。%Y:最后一次数据修改的时间,自Epoch以来的秒数。%z:上次状态变化的时间,可读。%Z:上次状态变化的时间,自Epoch以来的秒数。
“时代”是 Unix时代,发生在1970-01-01 00:00:00 +0000 (UTC)。
对于文件系统,格式序列是:
%a:普通(非root)用户可用的空闲块数。%b:文件系统中的总数据块。%c:文件系统中的inode总数。%d:文件系统中空闲inode的数量。%f:文件系统中空闲块的数量。%i:十六进制的文件系统ID。%l:文件名的最大长度。%n:文件名。%s:块大小(最佳写入大小)。%S:文件系统块的大小(用于块计数)。%t:十六进制的文件系统类型。%T:人类可读形式的文件系统类型。
有两个选项可以接受格式序列的字符串。它们是--format和--printf。它们之间的区别是--printf解释C风格的转义序列,例如换行符\n和制表符\t,并且它不会自动在其输出中添加换行符。
让我们创建一个格式字符串并将其传递给stat。我们将使用的格式序列是文件名的%n、文件大小的%s和文件类型的%F。我们将在字符串末尾添加\n转义序列,以确保每个文件都在新行上处理。我们的格式字符串如下所示:
"File %n is %s bytes, and is a %F\n"
我们将使用--printf选项将其传递给stat。我们将要求stat报告名为code.c的文件和一组匹配ana.?的文件。这是完整的命令。请注意--printf和格式字符串之间的等号“=”:
stat --printf="File %n is %s bytes, and is a %F\n" code.c ana/ana.?
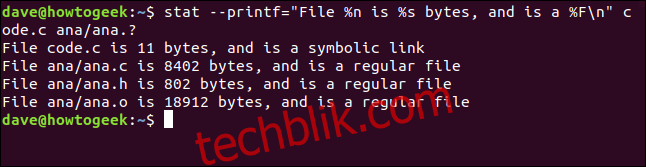
每个文件的报告都列在新行上,这是我们要求的。它为我们提供了文件名、文件大小和文件类型。
自定义格式使你可以访问比标准统计输出中包含的更多的数据元素。
细粒度控制
正如你所见,提取你感兴趣的特定数据元素有很大的空间。你可能还会明白,为什么我们建议为更长更复杂的命令使用别名。