Linux uniq 命令:文本行处理的利器
Linux uniq 命令是一个强大的工具,用于在文本文件中快速定位唯一或重复的行。本文将深入探讨其多功能性和强大功能,并指导您如何充分利用这个出色的实用程序。
在Linux系统中查找匹配的文本行
uniq 命令以其速度、灵活性和专注性而闻名。然而,像许多 Linux 命令一样,它也有一些需要注意的特性。理解这些特性至关重要,否则您可能会对结果感到困惑。 我们将在本文中逐步揭示这些特性。
uniq 命令非常适合那些专注于做好一件事的工具。 这也是为什么它特别适合在命令管道中使用。uniq 命令最常见的搭配是 sort 命令,因为 uniq 只有在输入排序后才能正常工作。
让我们开始探索吧!
不带选项运行 uniq 命令
我们有一个包含歌曲歌词的文本文件,该歌曲来自 Robert Johnson 的 “I Believe I’ll Dust My Broom”。 让我们看看 uniq 在这里的表现。
我们将输入以下命令,将输出通过管道传输到 less:
uniq dust-my-broom.txt | less
我们得到的是整首歌,包括重复的行,使用 less 显示:
这似乎既没有显示唯一的行,也没有显示重复的行。
没错,这就是 uniq 的第一个特性。 如果您在没有选项的情况下运行 uniq,它的行为就像您使用了 -u (唯一行) 选项一样。 这告诉 uniq 只打印文件中唯一的行。 您之所以看到重复的行,是因为为了使 uniq 将一行视为重复,它必须与它的重复行相邻。 这也是 sort 命令发挥作用的原因。
当我们将文件排序后,重复的行会分组在一起,uniq 才会将它们识别为重复。 我们将使用 sort 对文件进行排序,将排序后的输出通过管道传输到 uniq,然后再将最终输出通过管道传输到 less。
为此,我们输入以下命令:
sort dust-my-broom.txt | uniq | less
排序后的行列表将出现在 less 中。
“我相信我会把扫帚除尘”这句歌词肯定在这首歌中出现了很多次。 实际上,它在歌曲的前四行中重复了两次。
那么,为什么它出现在唯一行列表中呢? 因为当一行第一次出现在文件中时,它是唯一的;只有后续的条目是重复的。 您可以把它看作是列出每个唯一行的第一次出现。
让我们再次使用 sort 并将输出重定向到一个新文件中。 这样,我们就不必在每个命令中都使用 sort。
我们输入以下命令:
sort dust-my-broom.txt > sorted.txt
现在我们有了一个预先排序的文件可以使用。
统计重复次数
您可以使用 -c(计数)选项来打印文件中每一行出现的次数。
输入以下命令:
uniq -c sorted.txt | less
每行都以该行在文件中出现的次数开头。 但是,您会注意到第一行是空白的。 这表明文件中存在五个空行。
如果您希望输出按数字顺序排序,您可以将 uniq 的输出传递给 sort。 在我们的例子中,我们将使用 -r (反向) 和 -n (数字排序) 选项,并将结果通过管道传输到 less。
我们输入以下命令:
uniq -c sorted.txt | sort -rn | less
该列表根据每行出现的频率按降序排序。
只列出重复行
如果您只想查看文件中重复的行,您可以使用 -d (重复) 选项。 无论一行在文件中重复多少次,它都只列出一次。
要使用此选项,我们输入以下内容:
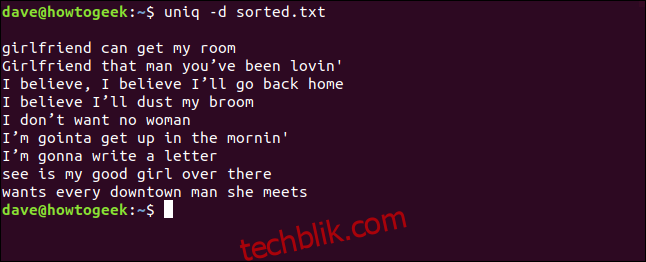
uniq -d sorted.txt
重复的行被列出。 你会注意到顶部的空白行,这表示该文件包含重复的空白行——它不是 uniq 留下的用于美化列表的空间。
我们还可以将 -d (重复) 和 -c (计数) 选项组合使用,并将输出通过管道传输到 sort。 这为我们提供了至少出现两次的行的排序列表。
输入以下命令以使用此选项:
uniq -d -c sorted.txt | sort -rn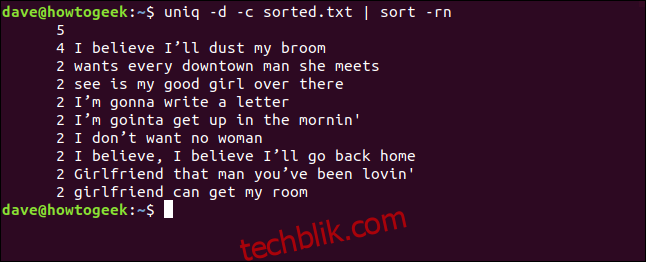
列出所有重复的行
如果您想查看每个重复行的列表,以及该行在文件中每次出现的条目,您可以使用 -D (所有重复行) 选项。
要使用此选项,请输入以下命令:
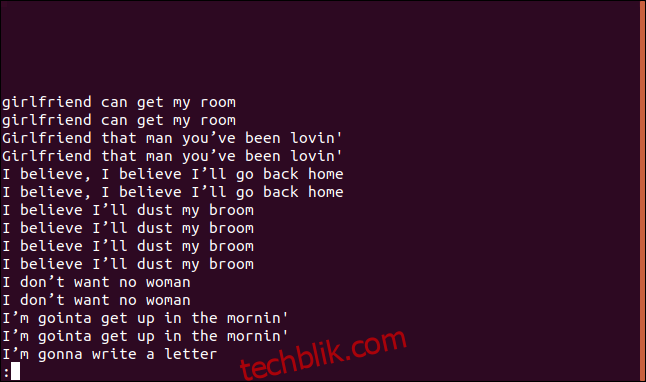
uniq -D sorted.txt | less
该列表包含每个重复行的条目。
如果您使用 --group 选项,它将在每个组之前(prepend)、之后(append) 或之前和之后 (both) 打印每个重复的行,并用一个空行分隔。
我们使用 append 作为修饰符,因此我们输入以下内容:
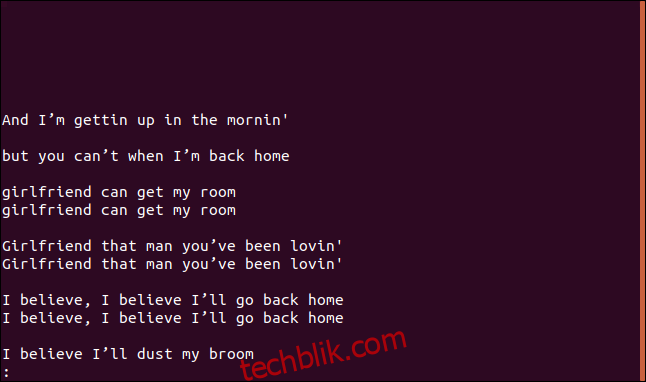
uniq --group=append sorted.txt | less
这些组由空行分隔,以便更易于阅读。
检查指定数量的字符
默认情况下,uniq 检查每一行的整个长度。 但是,如果要将检查限制为特定数量的字符,可以使用 -w (检查字符) 选项。
在本例中,我们将重复最后一个命令,但将比较限制为前三个字符。 为此,我们输入以下命令:
uniq -w 3 --group=append sorted.txt | less
我们收到的结果和分组完全不同。
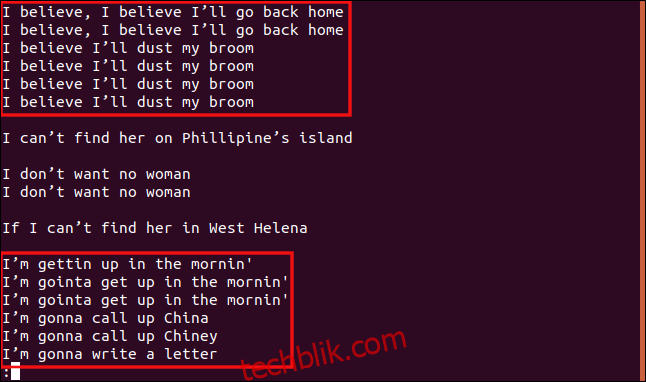
所有以 “I b” 开头的行都被组合在一起,因为这些行的那些部分是相同的,所以它们被认为是重复的。
同样,所有以 “I’m” 开头的行也被视为重复行,即使文本的其余部分不同。
忽略指定数量的字符
在某些情况下,跳过每行开头的特定数量的字符可能是有益的,例如当文件中的行被编号时。或者,假设您需要 uniq 跳过时间戳并从第 6 个字符开始检查行,而不是从第一个字符开始检查。
下面是我们排序后的文件的一个版本,其中包含编号的行。
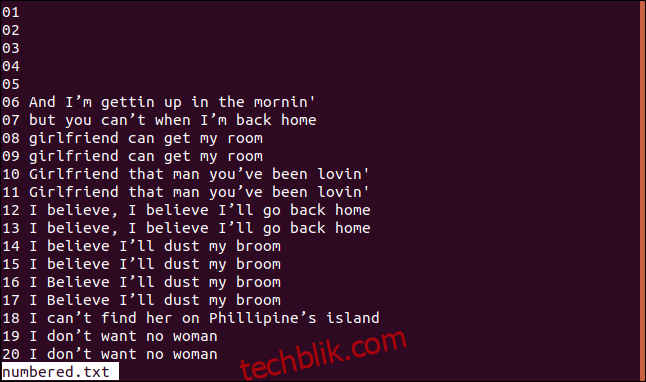
如果我们希望 uniq 在第 3 个字符处开始比较检查,我们可以通过输入以下命令使用 -s (跳过字符) 选项:
uniq -s 3 -d -c numbered.txt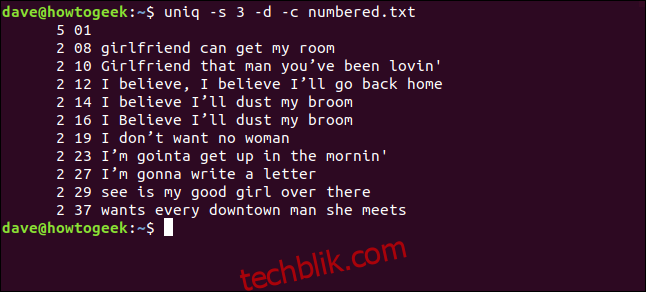
这些行被检测为重复并正确计数。 请注意,显示的行号是每个重复项第一次出现的行号。
您还可以跳过字段 (一系列字符和一些空格),而不是字符。 我们将使用 -f (字段) 选项来告诉 uniq 要忽略哪些字段。
我们输入以下命令来告诉 uniq 忽略第一个字段:
uniq -f 1 -d -c numbered.txt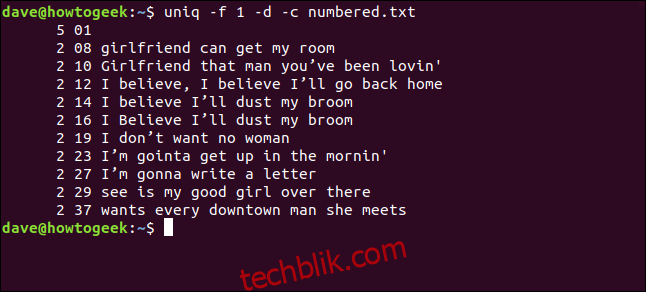
当我们告诉 uniq 跳过每行开头的三个字符时,我们得到了相同的结果。
忽略大小写
默认情况下,uniq 区分大小写。 如果相同的字母出现大写和小写,uniq 会认为这些行是不同的。
例如,查看以下命令的输出:
uniq -d -c sorted.txt | sort -rn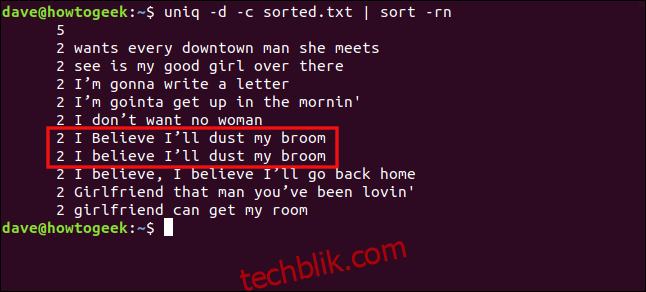
由于“believe”中“B”的大小写不同,“我相信我会为我的扫帚除尘”和“我相信我会为我的扫帚除尘”这行不被视为重复。
但是,如果我们包含 -i (忽略大小写) 选项,这些行将被视为重复。 我们输入以下内容:
uniq -d -c -i sorted.txt | sort -rn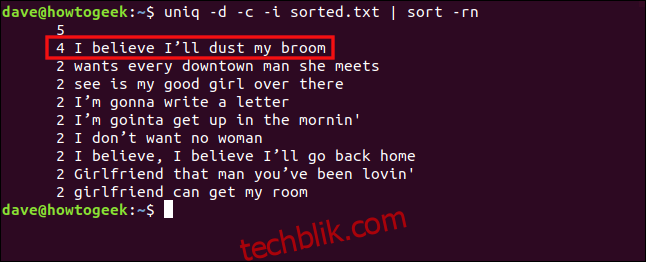
这些行现在被视为重复并组合在一起。
Linux 提供了许多特殊的实用程序供您使用。 像它们中的许多一样,uniq 不是您每天都会使用的工具。
这就是为什么掌握 Linux 的一个重要部分是记住哪个工具可以解决您当前的问题,以及在哪里可以再次找到它。 不过,如果您多加练习,您将做得很好。
或者,您可以随时搜索 How-To Geek——我们可能有相关的文章。