深入理解 grep 和正则表达式的强大功能
如果您已经熟悉 Linux 系统,那么您一定听说过 grep 命令。 这款强大的全局正则表达式打印工具,是文本处理和搜索的利器,尤其受到 Linux 高级用户的青睐。然而,仅仅使用 grep 而不结合正则表达式,可能会限制其功能的发挥。
那么,什么是正则表达式呢?
正则表达式 (regex) 是一种用于增强 grep 搜索能力的强大工具。 简单来说,正则表达式是一种高级的模式匹配语言,通过灵活的语法,可以实现更加精准和复杂的文本搜索。经过一定的练习,您将能够熟练运用正则表达式,并将其与其他 Linux 命令结合,发挥更大的威力。
本教程将引导您学习如何有效地使用 grep 命令,并结合正则表达式,提升您的文本处理能力。
先决条件
要熟练掌握 grep 和正则表达式的使用,需要您具备一定的 Linux 基础知识。 如果您是 Linux 新手,建议您先阅读一些 Linux 入门指南。
您还需要一台运行 Linux 操作系统的电脑。 您可以选择任何您喜欢的 Linux 发行版。 如果您使用的是 Windows 电脑,也可以通过 WSL2 (适用于 Linux 的 Windows 子系统 2) 来使用 Linux 环境。 您可以在这里找到有关 WSL2 的详细信息。
通过访问命令行或终端,您可以执行本教程中提供的所有 grep 和正则表达式命令。
此外,您还需要一个文本文件,用于测试命令。 我们使用 ChatGPT 生成了一段包含大量科技词汇的文本,并将其保存为 tech.txt 文件,本教程中我们将使用这个文件。
为了让您更好地理解,我使用了以下提示词来让 ChatGPT 生成文本:
“请生成一篇大约 400 个词的科技文章,其中应包含大多数科技领域的词汇,并确保在文本中多次重复这些科技词汇。”
最后,您需要对 grep 命令有一定的了解。 您可以查看一些 grep 命令示例,以巩固您的知识。 当然,我们也会简要回顾一下 grep 命令的基本用法。
grep 命令的语法和示例
grep 命令的语法非常简洁:
$ grep -options [regex/pattern] [files]
正如您所见,它需要一个模式 (regex/pattern) 以及您要搜索的文件列表 (files)。
grep 提供了许多选项,用于修改其行为。 一些常用的选项包括:
-i:忽略大小写。-r:递归搜索。-w:仅搜索整个单词。-v:显示所有不匹配的行。-n:显示匹配行的行号。-l:仅打印包含匹配内容的文件名。--color:彩色显示匹配结果。-c:显示匹配模式的行数。
#1. 搜索整个单词
要进行整个单词的搜索,需要使用 -w 参数。
$ grep -w 'tech\|5G' tech.txt
此命令将在 tech.txt 文件中查找 “5G” 和 “tech” 这两个完整的单词,并将它们以红色高亮显示。
在这里,我们使用转义符 \ 来转义管道符 |,避免 grep 将其视为元字符。
#2. 不区分大小写的搜索
要执行不区分大小写的搜索,请使用 -i 参数。
$ grep -i 'tech' tech.txt
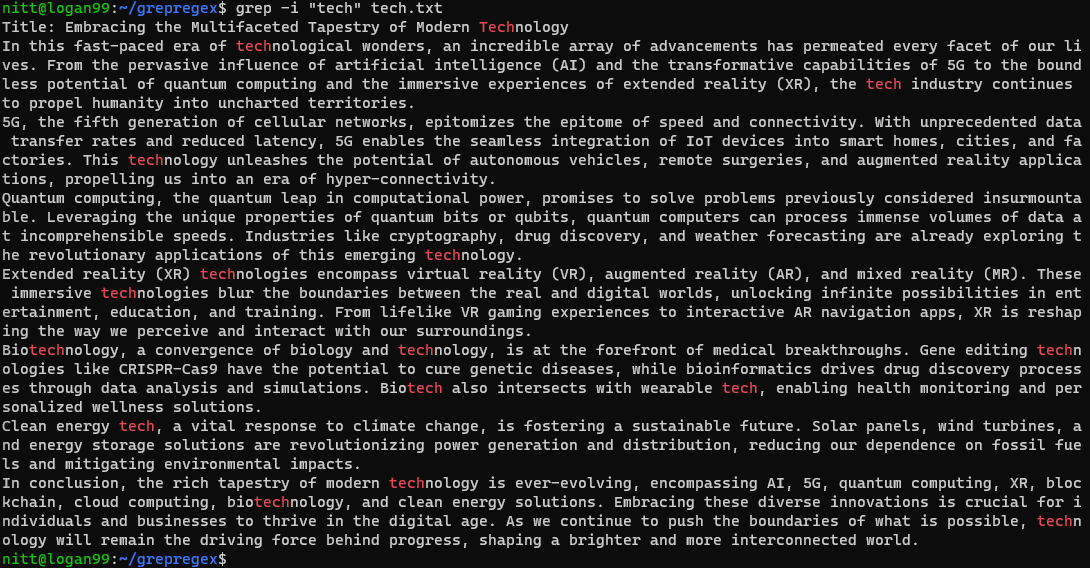
此命令将搜索 tech.txt 文件中所有不区分大小写的 “tech” 字符串,无论是完整的单词还是单词的一部分。
#3. 显示不匹配的行
要显示所有不包含给定模式的行,请使用 -v 参数。
$ grep -v 'tech' tech.txt

输出结果显示了所有不包含 “tech” 单词的行,包括空行 (段落之间的空行)。
#4. 递归搜索
要进行递归搜索,请使用 -r 参数。
$ grep -R 'error\|warning' /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
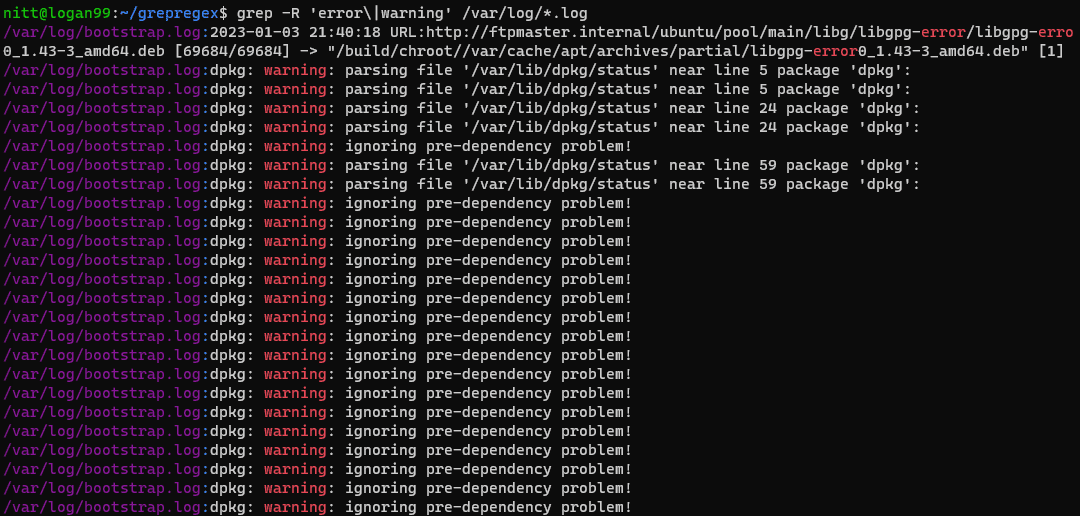
此命令将在 /var/log 目录下的所有 *.log 文件中递归搜索 “error” 或 “warning” 这两个单词。 这对于检查日志文件中的警告和错误信息非常有用。
grep 和正则表达式:概念与示例
当使用正则表达式时,您需要了解正则表达式提供了三种语法选项:
- 基本正则表达式 (BRE)
- 扩展正则表达式 (ERE)
- Perl 兼容正则表达式 (PCRE)
grep 默认使用 BRE。 如果您想使用其他正则表达式模式,则需要在命令中明确指定。 此外,grep 会将元字符视为普通字符。 因此,如果您想使用 ?, +, ) 等元字符,需要使用反斜杠 \ 对它们进行转义。
grep 与正则表达式的语法如下:
$ grep [regex] [filenames]
通过以下示例来了解 grep 和正则表达式的实际应用。
#1. 字面词匹配
要进行字面词匹配,您只需要将字符串作为正则表达式传递给 grep。 毕竟,单词本身也是一种简单的正则表达式。
$ grep "technologies" tech.txt

同样,您可以使用字面词匹配来查找当前用户。 例如:
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
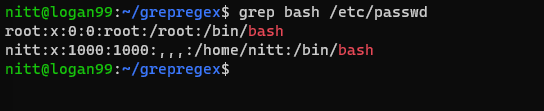
这会显示所有可以访问 bash 的用户。
#2. 锚点匹配
锚点匹配是一种使用特殊字符进行高级搜索的技术。 正则表达式中可以使用不同的锚点字符来表示文本中的特定位置,例如:
^(插入符号): 匹配输入字符串或行的开头,同时可以匹配空字符串。$(美元符号):匹配输入字符串或行的末尾,同时可以匹配空字符串。
另外两个锚点匹配字符是 \b (单词边界) 和 \B (非单词边界):
\b(单词边界):\b用于断言单词字符和非单词字符之间的位置,简单来说,它使您可以匹配完整的单词,从而避免部分匹配。您也可以使用它来替换单词或统计字符串中单词的出现次数。\B(非单词边界): 它与正则表达式中的\b相反,断言匹配不在两个单词或非单词字符之间的位置。
下面通过一些例子来加深理解:
$ grep '^From' tech.txt

使用插入符号时,需要输入正确的字符大小写,因为它是区分大小写的。 如果运行以下命令,则不会返回任何结果:
$ grep '^from' tech.txt
同样,您可以使用 $ 符号来查找以指定模式、字符串或单词结尾的句子:
$ grep 'technology.$' tech.txt

您也可以组合 ^ 和 $ 符号。 如下所示:
$ grep "^From \| technology.$" tech.txt
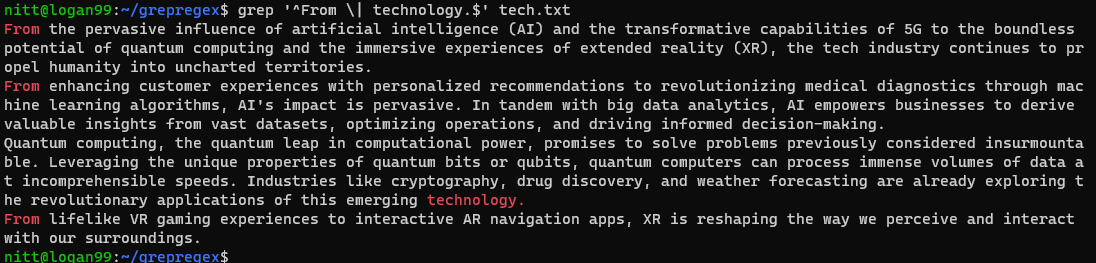
此命令将查找以 “From” 开头的行和以 “technology.” 结尾的行。
#3. 分组
如果您需要一次搜索多个模式,可以使用分组。 分组可以将多个字符和模式视为一个单元。 例如,您可以创建一个包含字母 “t”、“e”、“c”、“h” 的组 (表示 “tech” 或 “technology”)。
以下示例可以帮助您更好地理解分组:
$ grep 'technol\(ogy\)\?' tech.txt

通过分组,您可以匹配重复模式、捕获组和进行替代搜索。
分组替代搜索
下面是一个替代搜索的示例:
$ grep "\(tech\|technology\)" tech.txt
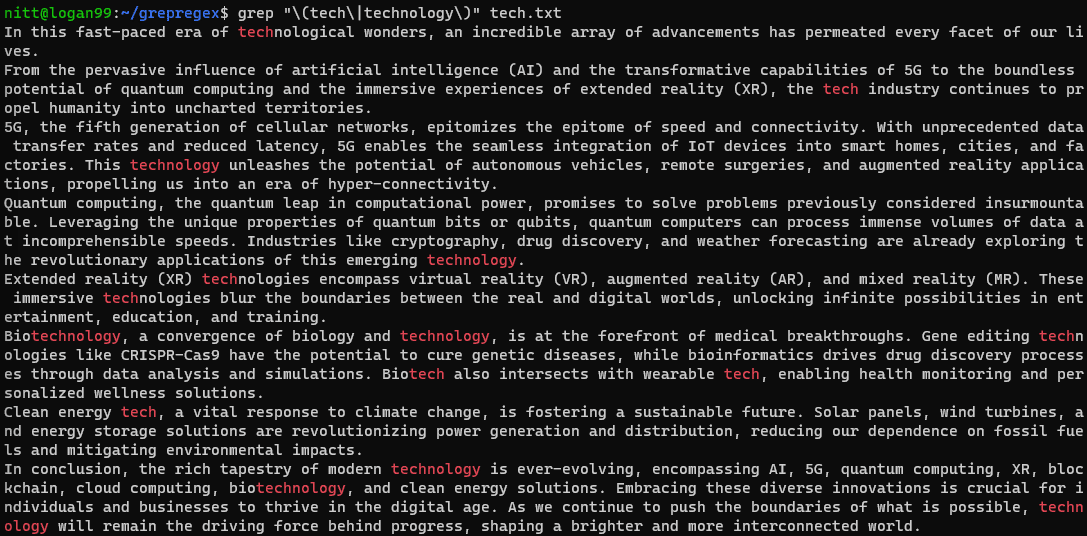
如果需要在字符串上执行搜索,可以使用管道符号传递:
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

捕获组、非捕获组和重复模式
那么,捕获组和非捕获组又是什么呢?
要在正则表达式中创建一个捕获组,需要将该组用括号括起来,并将其传递给要搜索的字符串或文件。
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

对于非捕获组,需要在括号内使用 ?:。
最后,我们来看重复模式。您需要修改正则表达式来检查重复模式。
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
此正则表达式将查找一个或多个 “t” 字符。
#4. 字符类
使用字符类,可以更轻松地编写正则表达式。 字符类使用方括号 []。 一些常用的字符类包括:
[:digit:]– 0 到 9 的数字[:alpha:]– 字母字符[:alnum:]– 字母数字字符[:lower:]– 小写字母[:upper:]– 大写字母[:xdigit:]– 十六进制数字,包括 0-9、A-F、a-f[:blank:]– 空白字符,例如制表符或空格
接下来我们看几个实例:
$ grep [[:digit]] tech.txt

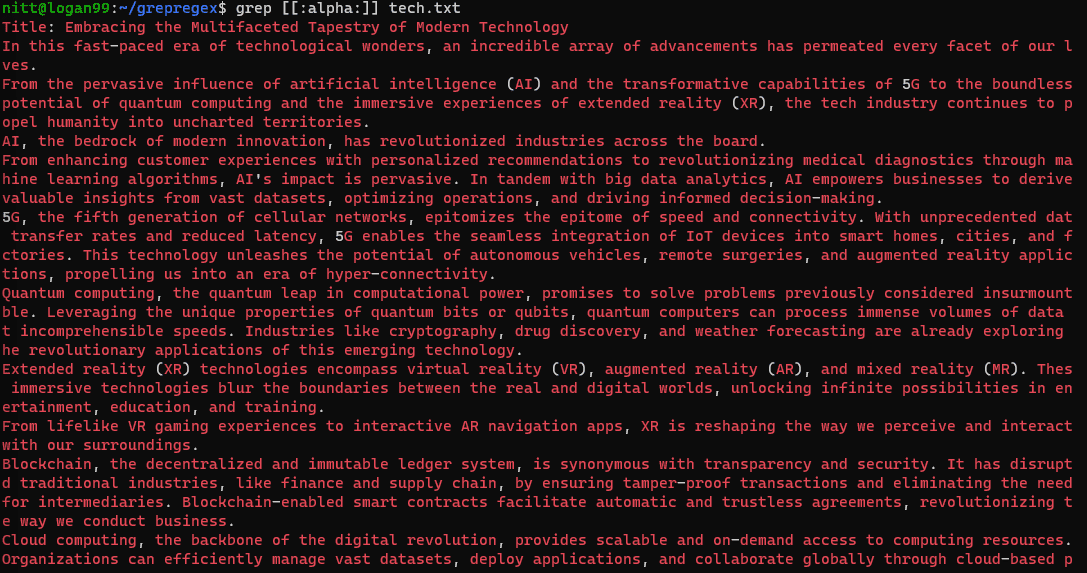
$ grep [[:alpha:]] tech.txt
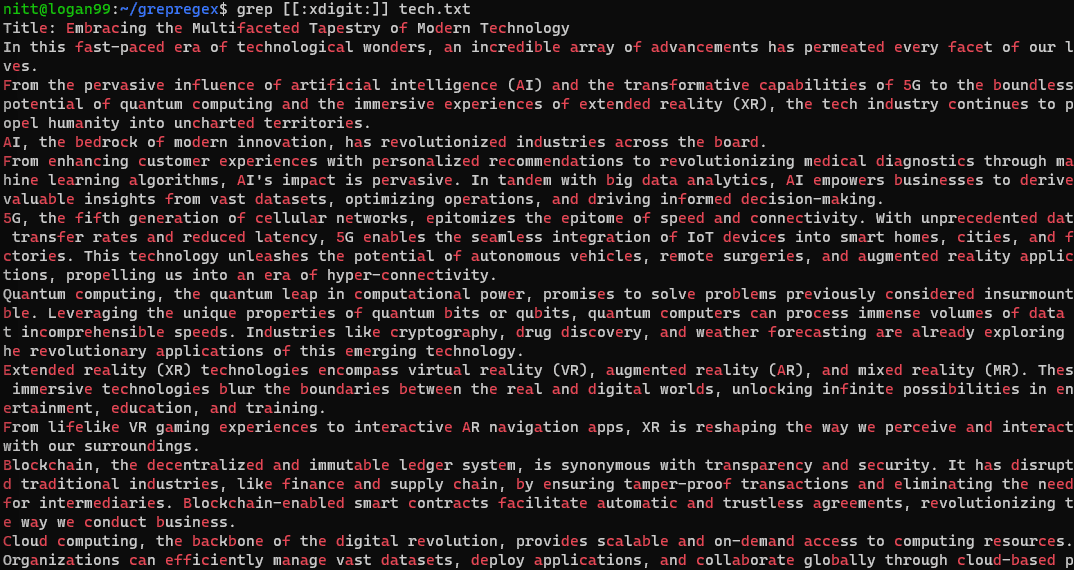
$ grep [[:xdigit:]] tech.txt
#5. 量词
量词是正则表达式的核心,它们是用来匹配特定模式的元字符。 它们可以帮助您精确控制匹配次数。 下面是一些常用的量词:
*→ 零个或多个匹配项+→ 一个或多个匹配项?→ 零个或一个匹配项{x}→ 匹配 x 次{x, }→ 匹配 x 次或更多{x,z}→ 匹配 x 到 z 次{, z}→ 最多匹配 z 次
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
这里,此命令将搜索出现一个或多个 “t” 字符的实例。其中 -E 表示使用扩展正则表达式 (稍后会讨论)。

#6. 扩展正则表达式
如果您不想在正则表达式模式中添加反斜杠来转义元字符,则必须使用扩展正则表达式。 它消除了添加转义字符的需要。 为此,您需要使用 -E 标志。
$ grep -E 'in+ovation' tech.txt

#7. 使用 PCRE 进行复杂搜索
PCRE (Perl 兼容正则表达式) 可以让您做的事情远不止编写基本表达式。 例如,您可以使用 \d 表示 [0-9]。
例如,您可以使用 PCRE 搜索电子邮件地址:
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

在这里,PCRE 确保了模式匹配。 同样,您可以使用 PCRE 模式检查日期模式:
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

此命令查找 YYYY-MM-DD 格式的日期。 当然,您也可以修改它以匹配其他日期格式。
#8. 交替
如果您需要进行替代匹配,可以使用转义的管道符 \|。
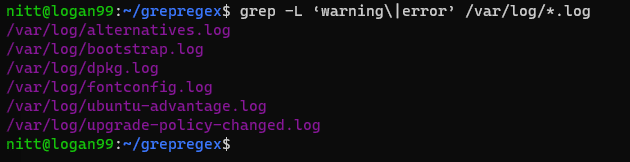
$ grep -L 'warning\|error' /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
输出结果列出了包含 “warning” 或 “error” 的文件名。
最后的话
至此,本教程关于 grep 和正则表达式的内容就结束了。 您可以使用 grep 和正则表达式来优化搜索,提高文本处理的效率。 通过合理运用它们,可以节省大量时间并帮助自动化许多任务,特别是在编写脚本或使用正则表达式执行文本搜索时。
接下来,您可以了解一些常见的 Linux 面试问题和答案。