在当今这个信息爆炸的时代,互联网的演变速度令人瞩目。网站如同一个个鲜活的生命体,不断地经历着改版和内容更新的洗礼。然而,世事无常,一些网站可能会因为公司倒闭或其他因素而最终关闭。值得庆幸的是,存在着一些历史记录工具,它们能够帮助我们回溯时光,查看网站的旧版本及其演变历程。有时,当你试图访问某个网站时,却发现它已不复存在,这或许意味着该网站已被删除。别担心,本文将深入探讨如何找回那些已消失的旧网站,让我们一起探索吧。

如何找回已逝去的旧网站
接下来,我们将详细介绍几种查找不再存在的旧网站的方法。
为什么我们需要访问旧版本的网站?
你可能会好奇,为什么我们需要查找旧网站?对于不断发展的网站而言,其整体设计、数据以及页面内容都会随着时间的推移而持续更新。这些多次的迭代有助于网站的完善,使其比以往版本更出色。以下是一些可能需要访问旧版本网站的原因:
- 如果你钟爱的某个网站因故被移除,例如审查或其他原因,你可以通过访问其存档版本来重温旧时光。
- 如果你想了解网站早期的设计理念,查阅存档会是一个不错的选择。
- 如果某些对你而言至关重要的数据因定期更新而丢失,你可以返回网站的旧版本来重新找回。
- 对于撰写文章的博主或科研人员,你可能需要在文章中引用过往的资料。如果原始文章已失效,你仍然可以使用这些链接的缓存版本,方便读者追溯信息的来源。
- 如果你是SEO从业者,你可以使用这些存档工具来识别并修复失效的链接,并调整网页的改动。
- 有时候,当你需要互联网上某些滥用或威胁的证据,并希望向上级举报时,旧版本的网站可能派上用场,因为网站评论的实时版本可能会被删除。
正是由于以上这些原因,你可能会想知道如何才能找到那些已不复存在的旧网站。你可以利用互联网存档资源来查看网站的旧版本,并观察其发展轨迹。
方法一:利用谷歌搜索
你还可以借助谷歌搜索引擎来查找旧网站。这将是一个很好的关于如何查找已消失旧网站的教程。你也可以对网页的URL进行细微修改,来加载旧版本的网站。
1. 如果你想要搜索旧文章或旧页面,可以输入关键字“site:”后接网页的URL。
2. 现在,执行搜索,例如 “site:techcult.com”。
谷歌
注意:以上示例仅用于说明。
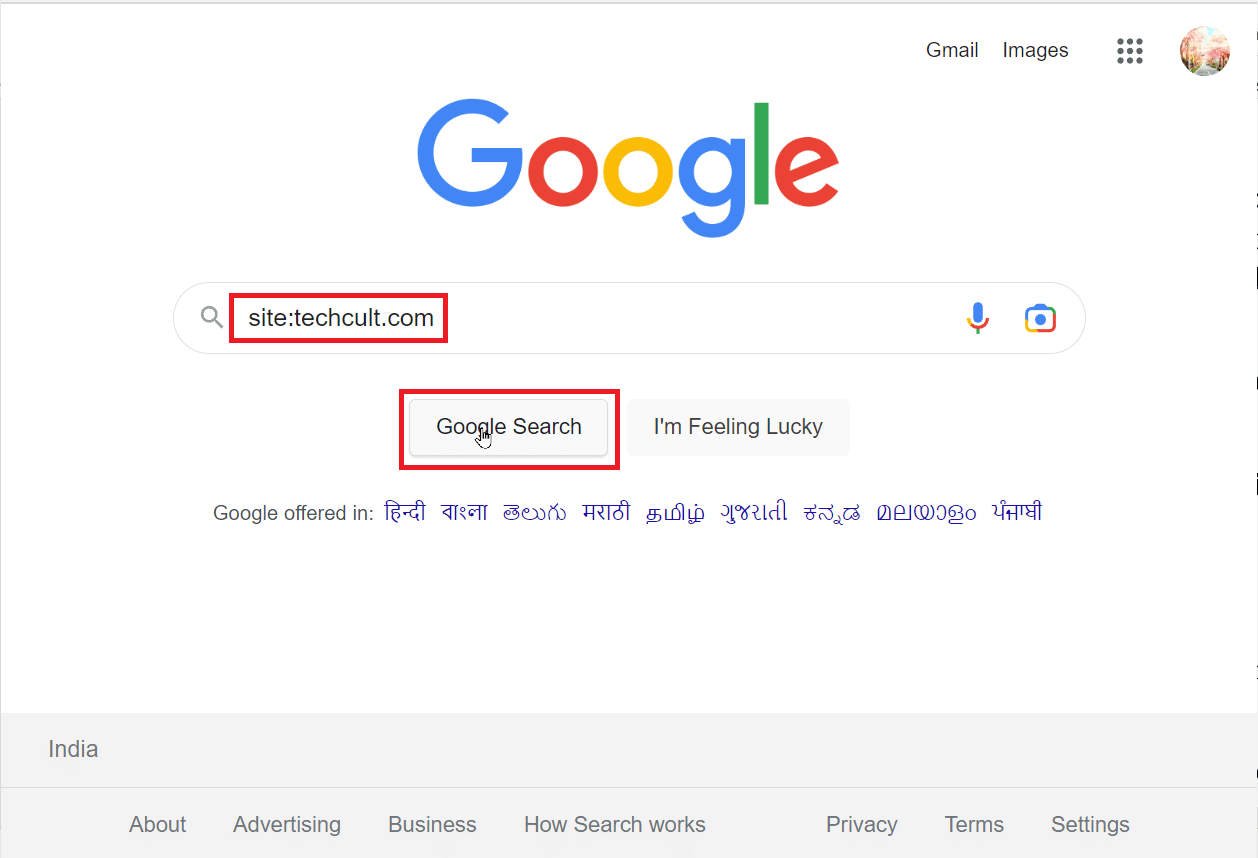
3. 点击顶部的“工具”,会弹出一个下拉菜单。接着,点击“任何时间”下拉菜单,查看你想要整理的档案的时间范围。
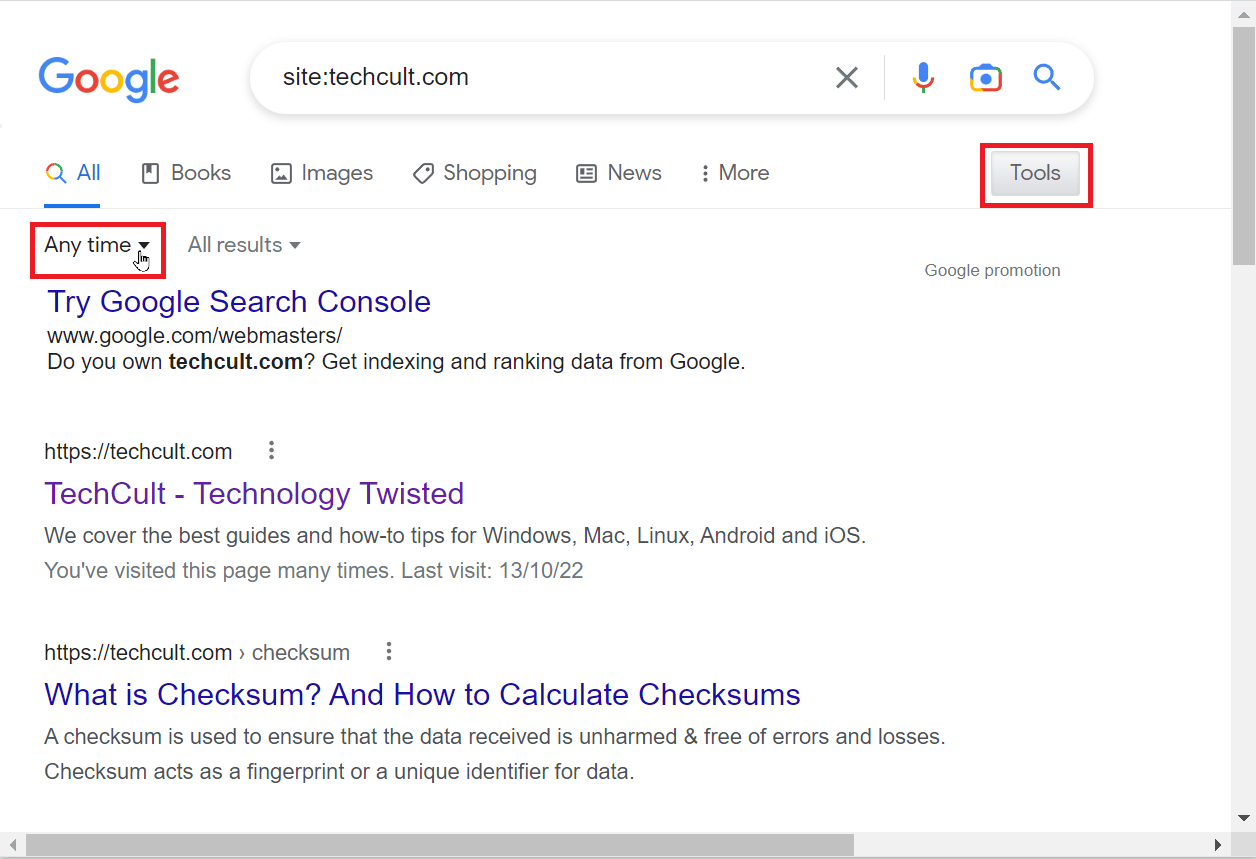
4. 如果你想要输入自定义时间,请点击“任何时间”下拉菜单,然后点击“自定义范围”。
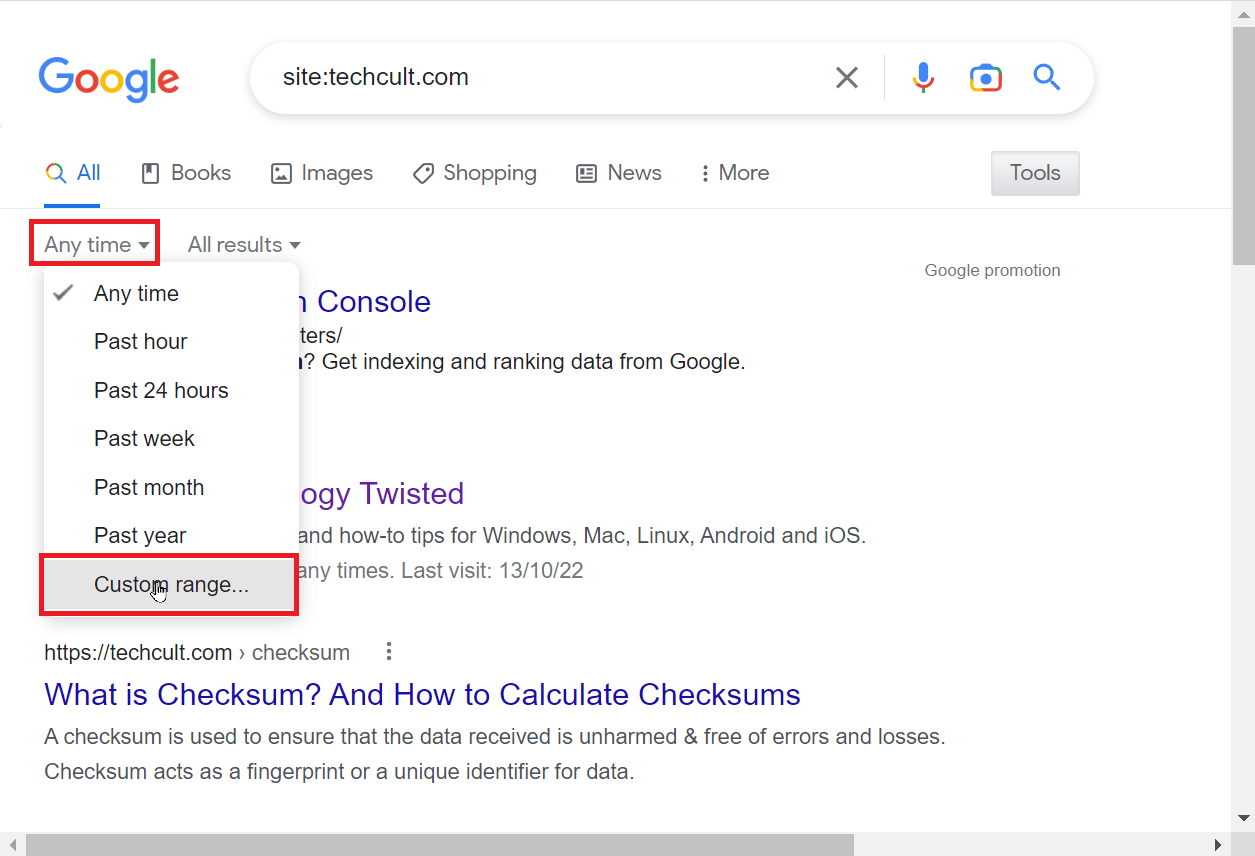
5. 将会显示一个新的窗口。你可以在“从”和“到”框中输入日期,设定你希望搜索的网站时间范围。
6. 最后,点击“前往”按钮,根据你输入的时间范围进行搜索。
注意:需要注意的是,有些网站由于某些问题没有被存档,搜索这些网站的旧文章可能会将你重定向到它们当前的网站。
上述方法可以帮助你了解如何在谷歌上查找旧网站。
方法二:利用必应搜索
如果谷歌搜索没有提供你想要的结果,你还可以尝试必应搜索引擎。请按照以下步骤操作:
1. 在必应搜索引擎上输入“site:”加上你想要搜索的网站并按下Enter键。
注意:这里使用了techcult.com作为参考。
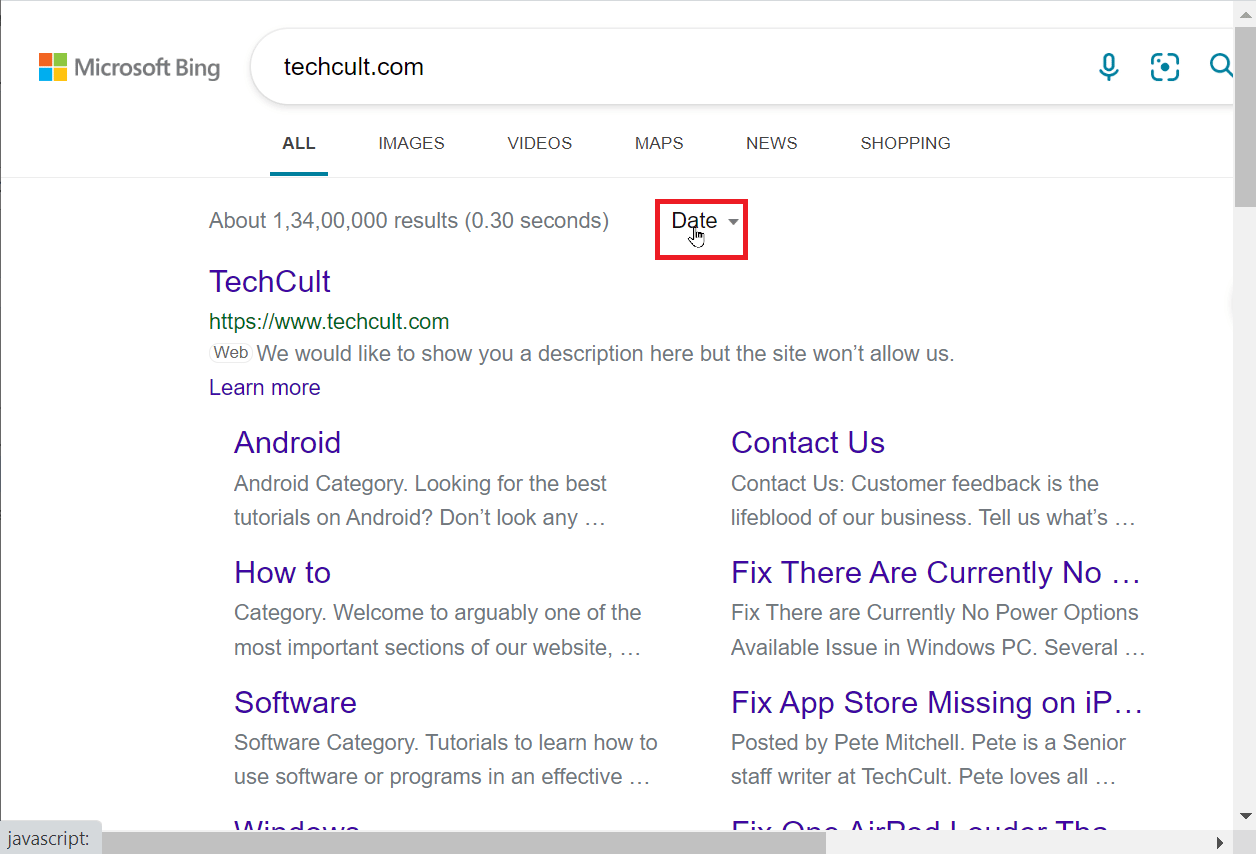
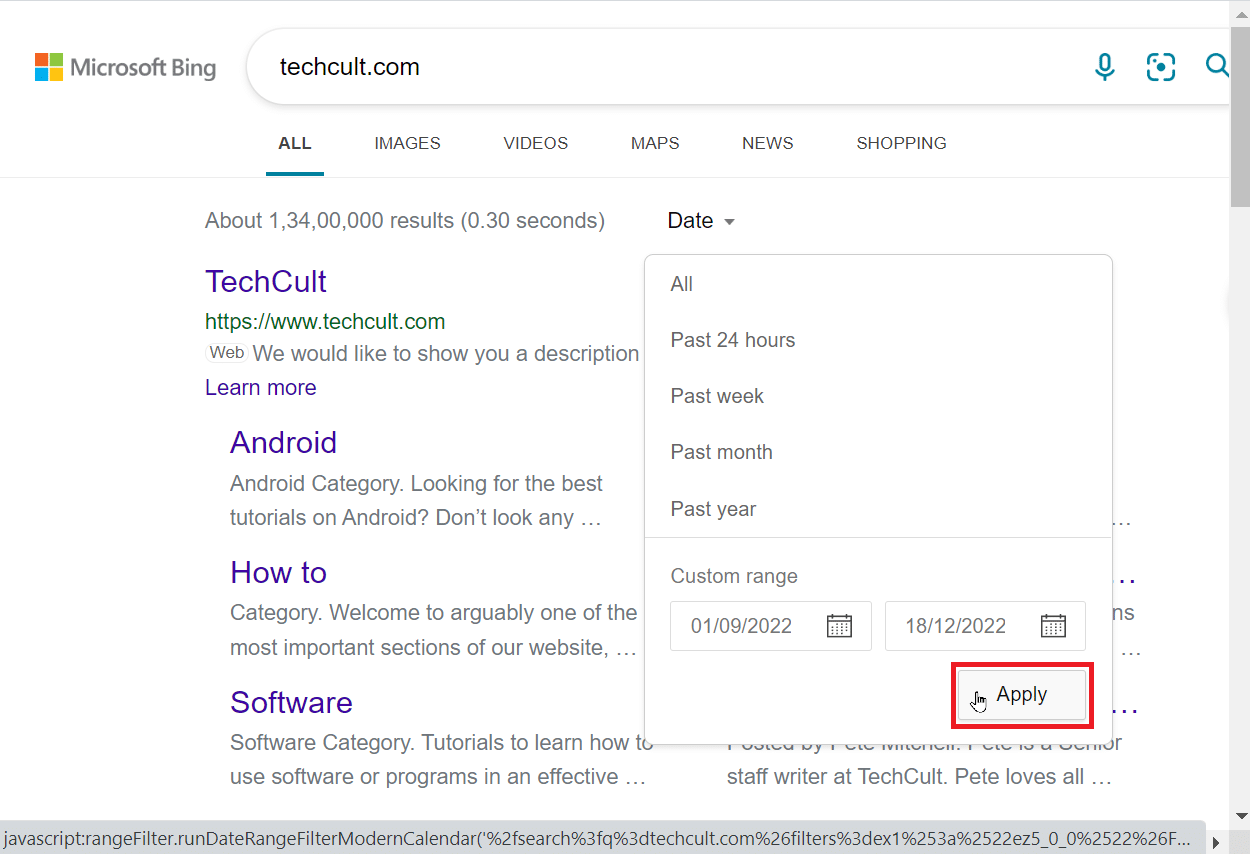
2. 搜索完成后,你可以根据日期对搜索结果进行排序。点击“日期”下拉菜单。
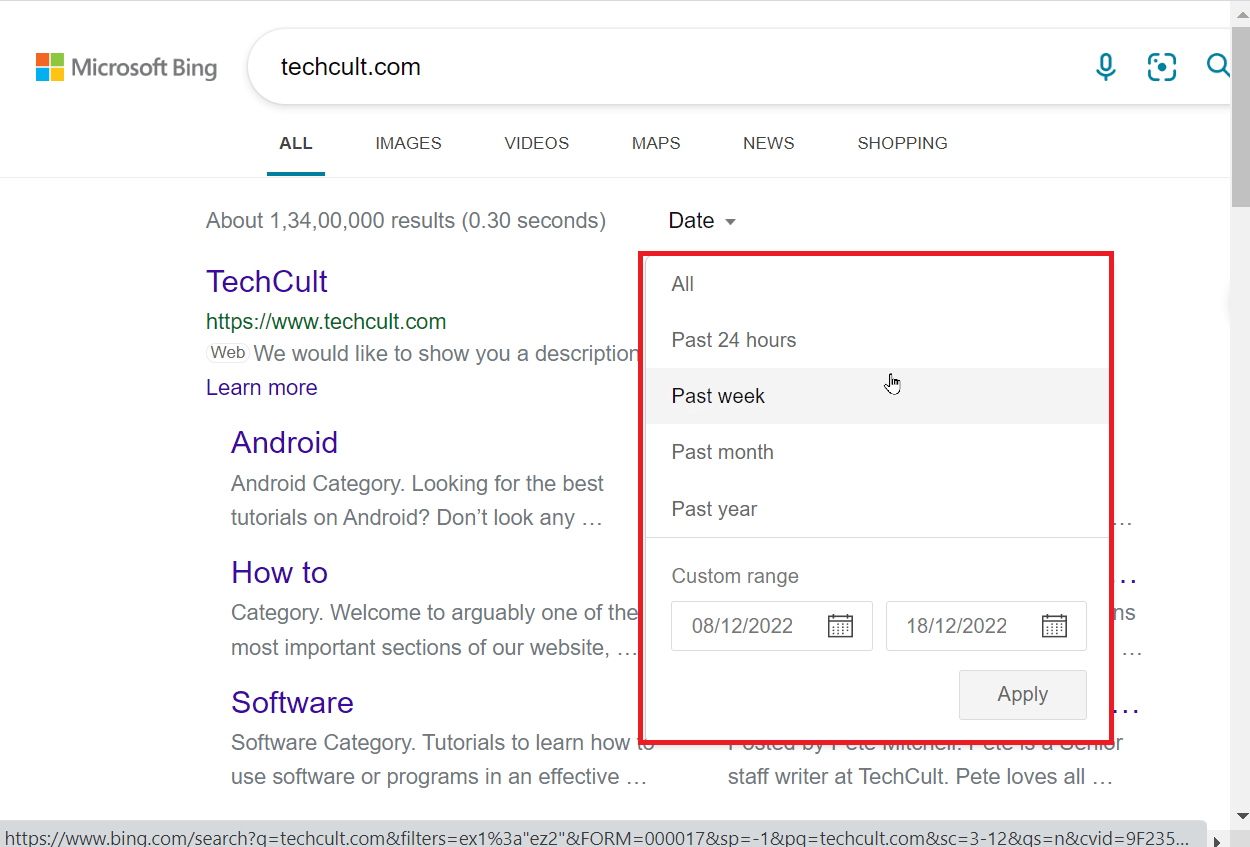
3. 现在,你可以选择在该网站上发布文章的时间范围。
4. 如果你想输入自定义日期,你可以编辑当前的自定义范围框。第一个框表示起始日期,第二个框表示结束日期。
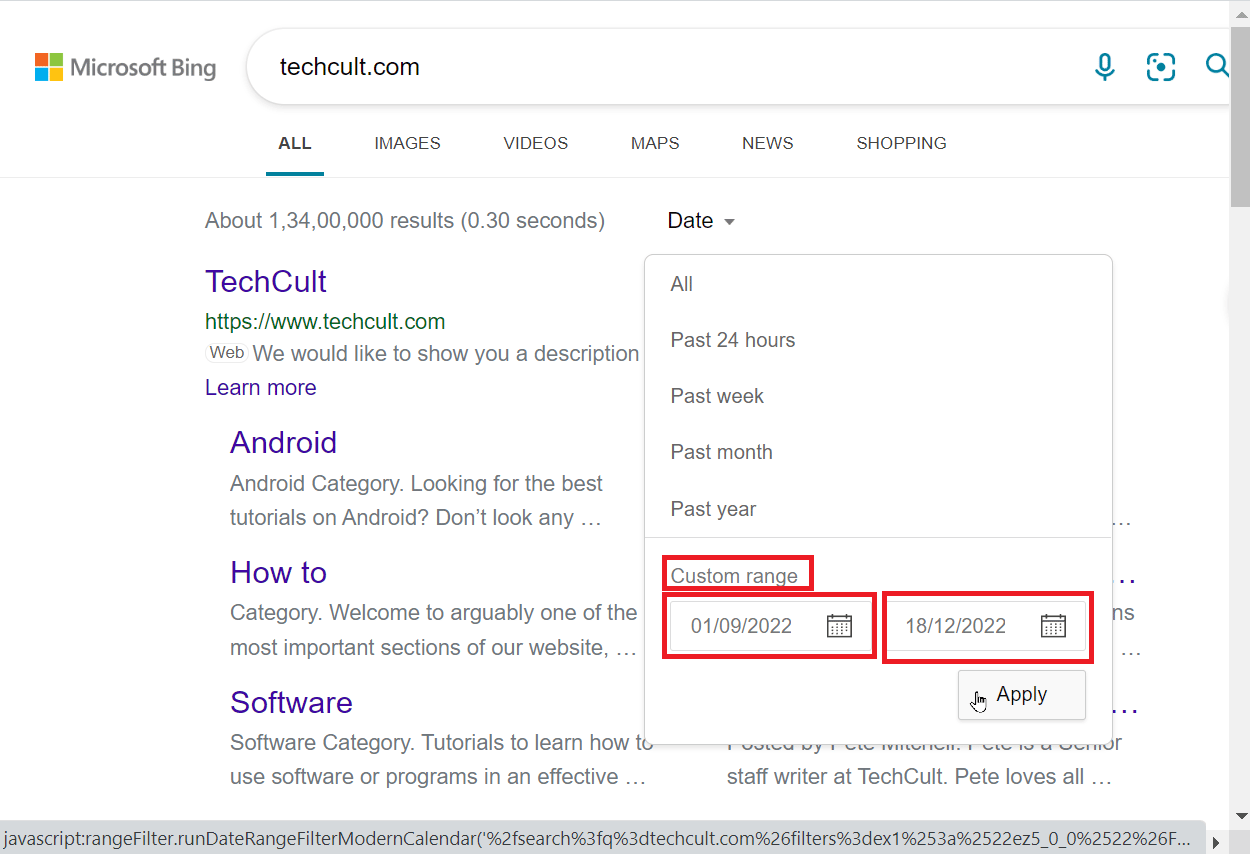
5. 最后,点击“应用”搜索你输入的日期范围。
方法三:通过谷歌缓存页面搜索
谷歌有时会存储网站的缓存版本。这个版本是缓存的网站的最新版本,因此它不是实时版本,而是从以前的时间点缓存的,你可以访问它。 如果你想知道如何通过搜索引擎查找已不复存在的旧网站,这个方法将对你有所帮助。
1. 在谷歌搜索栏中搜索一个网站,并按下Enter键。
注意:这里使用了techcult作为参考。
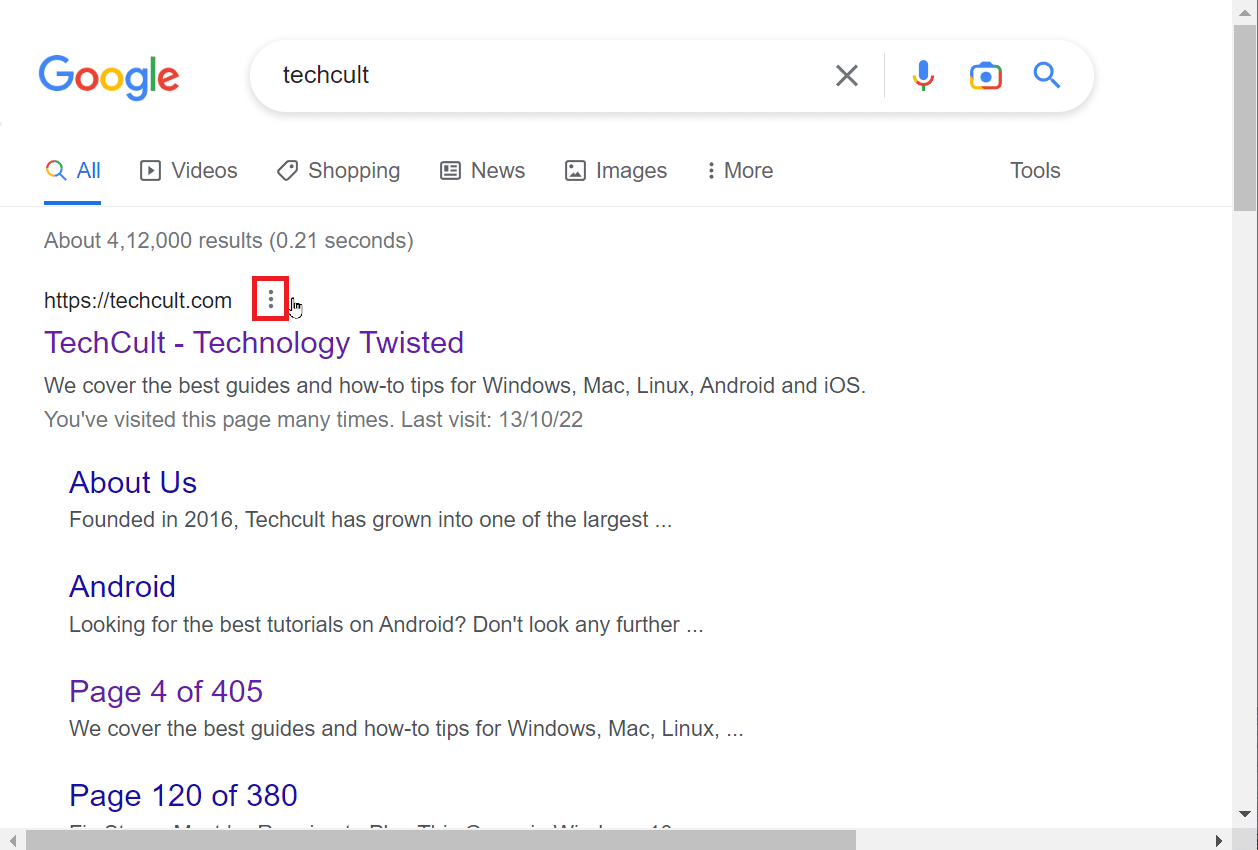
2. 点击出现的三个点。
3. 将会弹出一个特定的窗口。然后,如果可用,请点击“缓存”。
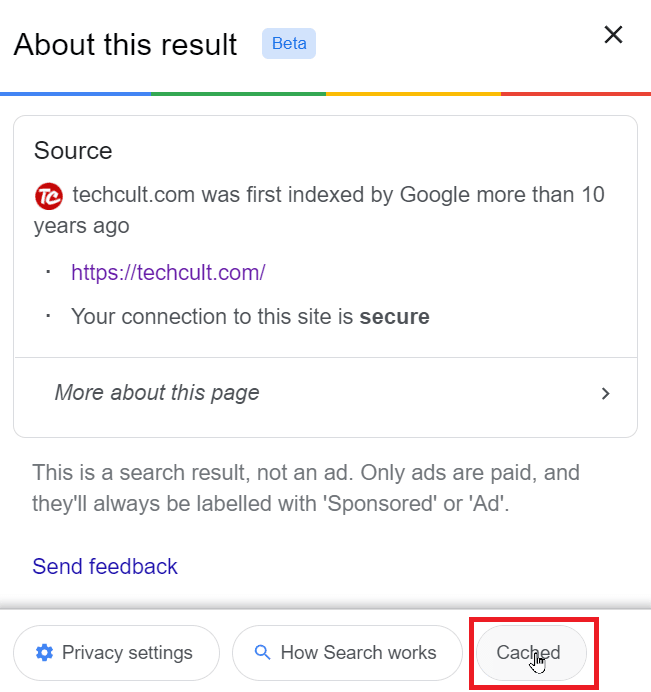
4. 这些缓存的网站提供了之前被删除或编辑过的信息。这些缓存由搜索引擎创建,因此你可能会在不同的搜索引擎上获得不同的缓存选项。
5. 如果你使用谷歌浏览器,并且你知道一个网站的URL,并想获得它的缓存版本页面。可以在网址前输入关键字“cache:”,例如“cache:techcult.com”。这将直接显示网站的缓存版本。
注意:以上示例仅用于说明。

方法四:使用外部网站
许多服务提供查看网站旧版本的功能,之所以可行,是因为这些服务存储了网站的各种副本。 根据需求,这些服务可以抓取特定页面的快照,这意味着你可以找到数以千计的网站改版版本。接下来,我们将讨论这些服务。那些正在搜索如何查找不再存在的旧网站的人可能会发现此方法很有帮助。
1. 互联网档案馆回顾
互联网档案馆是一个允许搜索档案的组织。这是因为其存档了网站、书籍、音频记录、图片等等的数字图书馆。即使是一些旧的游戏模拟版本,你也可以直接在浏览器中玩。互联网档案馆存储了超过4480亿个网页。该网站允许用户通过一个名为Wayback Machine的工具来搜索其档案。
1. 前往回程机工具的官方网站。
2. 要检查特定网站的所有存档,请输入该网站的URL。
3. 点击“BROWSE HISTORY”进行搜索。
4. Wayback Machine会显示在过去几年里保存了多少个副本,并用图表描述这些数据。
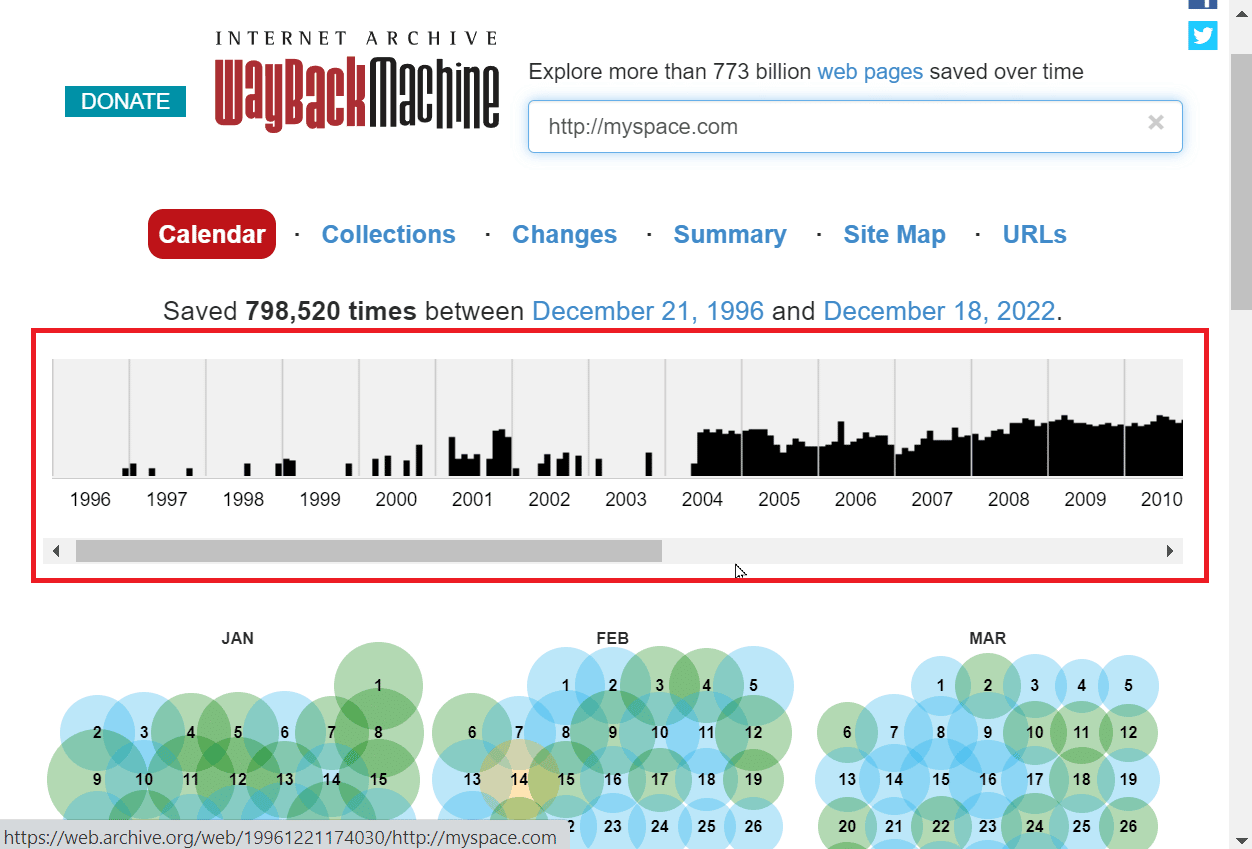
5. 你还可以通过对年份进行排序来访问这些数据。点击图表上的年份以按年份排序。
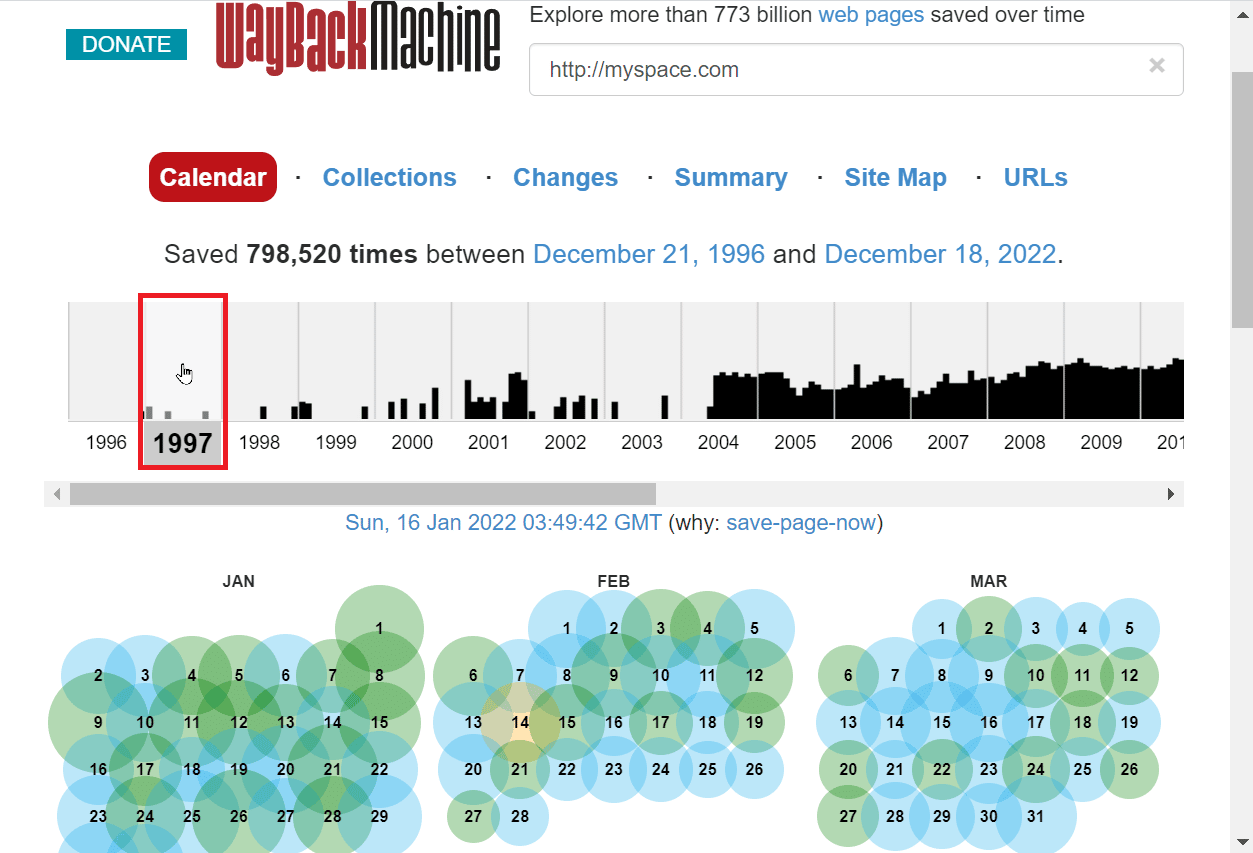
6. 所选年份的页面上将显示月份。
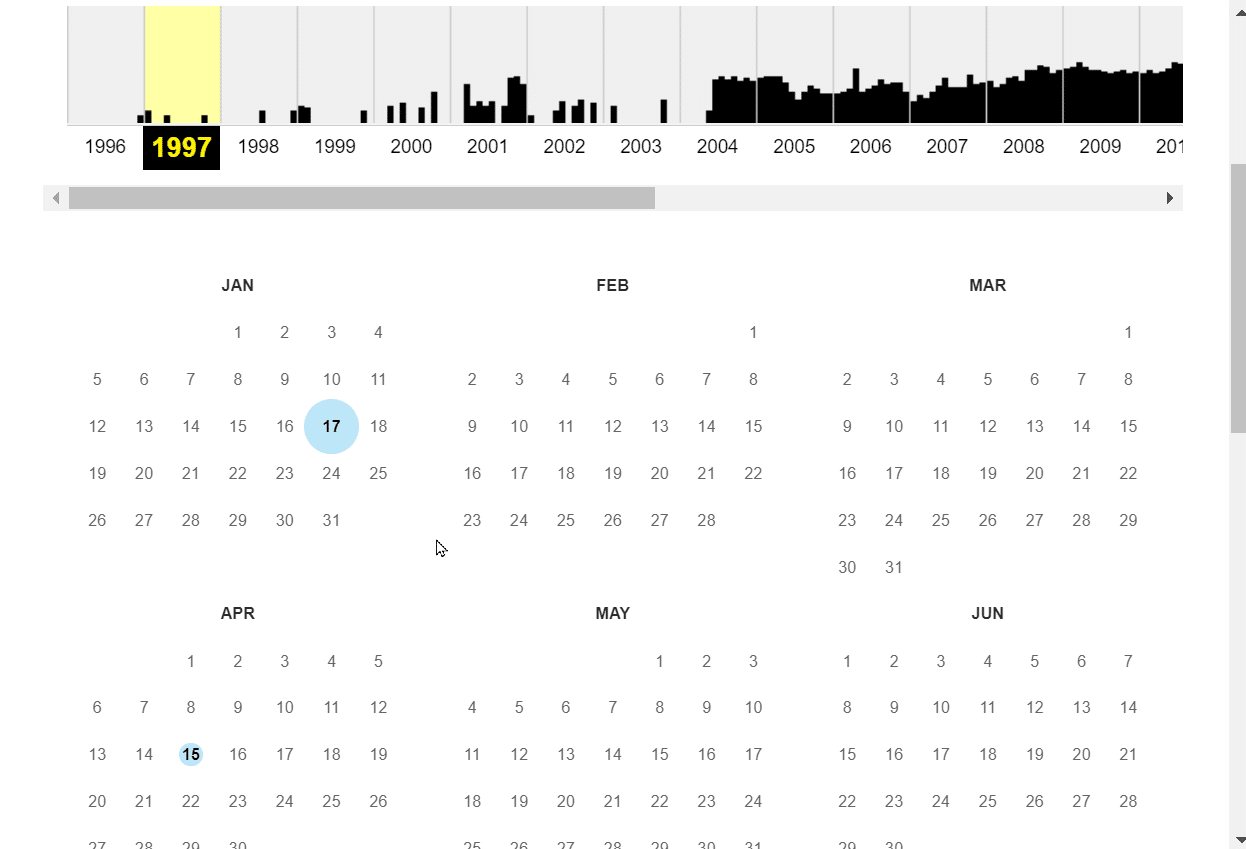
7. 你可以点击一个日期,将提供特定日期的所有快照。
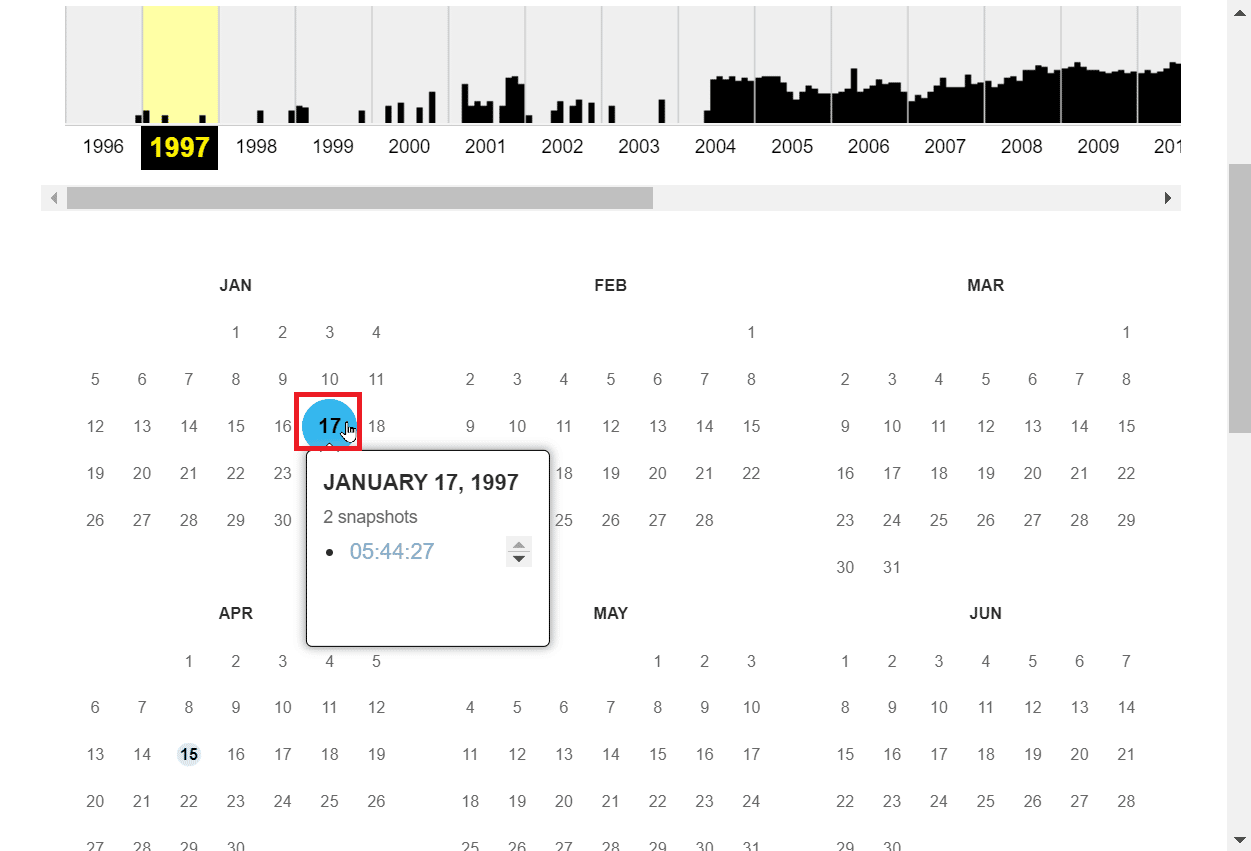
8. 当你点击你想要查看的快照时,快照将在同一标签页打开。
注意:只有突出显示为圆圈的日期才会有快照,并且只能查看这些日期。
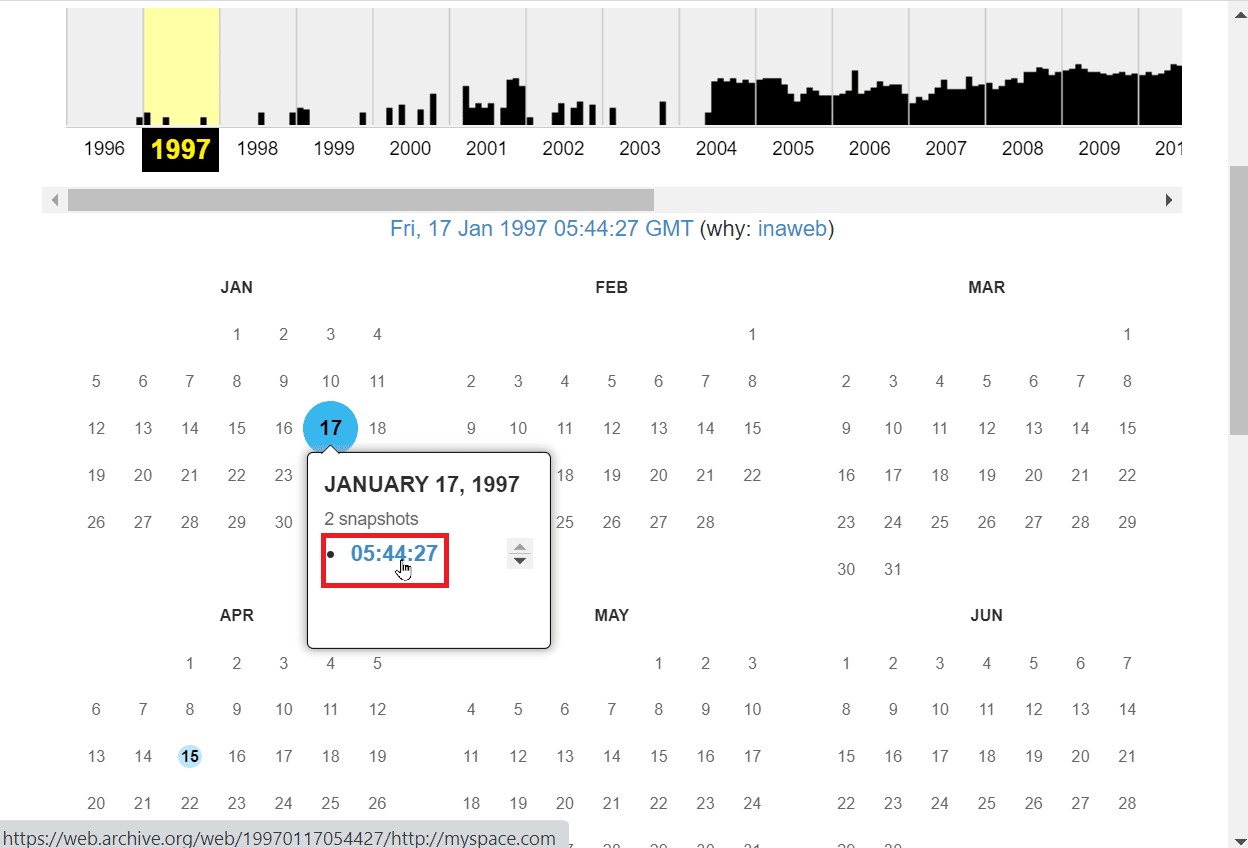
9. 由于Wayback Machine会搜索海量的数据库,所以搜索可能需要一些时间。
注意:有时,你可能无法获得所需的信息,或者可能没有为网站保存任何缓存副本,并且可能会遇到网站不再可用的提示。造成这种情况的原因可能是网页没有被缓存,这对于所有在其网站上拥有庞大内容库的网站而言很常见。
10. 下面给出的是1997年的Myspace网站。
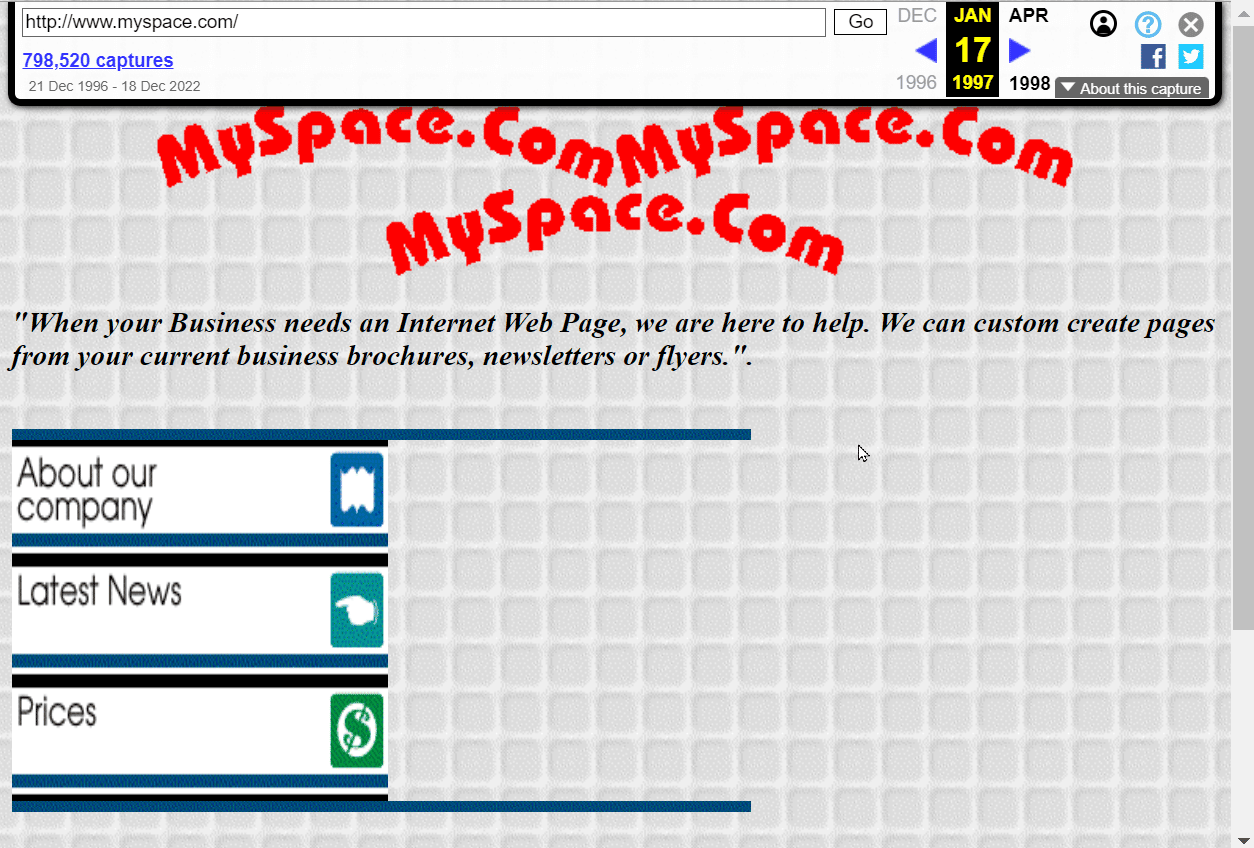
2. 旧网今日
oldweb.today是一项服务,它能为你提供任何旧网站的数据,同时还能模拟旧浏览器,为你提供完整的旧浏览体验。使用oldweb.today将允许你使用最旧版本的Internet Explorer和Netscape Navigator。这个网站上有足够多的档案,包括来自互联网档案和其他国家档案馆的内容。该网站最适合一次查看一个网站,因为使用该网站的个人需要等待几分钟才能再次使用。
1. 访问 oldweb.today 网站。
2. 从浏览器/仿真器下拉列表中选择一个浏览器。
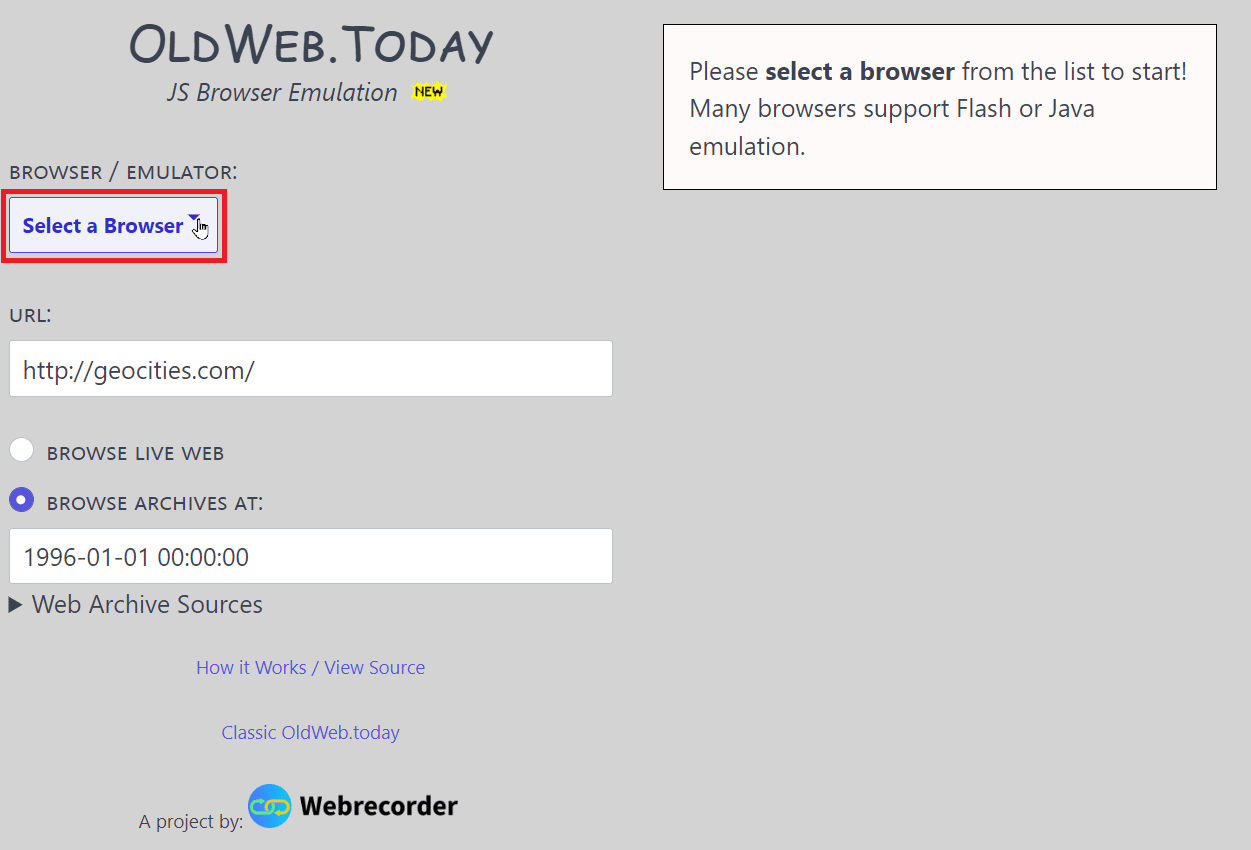
3. 在“URL:”框中输入URL或网站名称,开始搜索该网站。
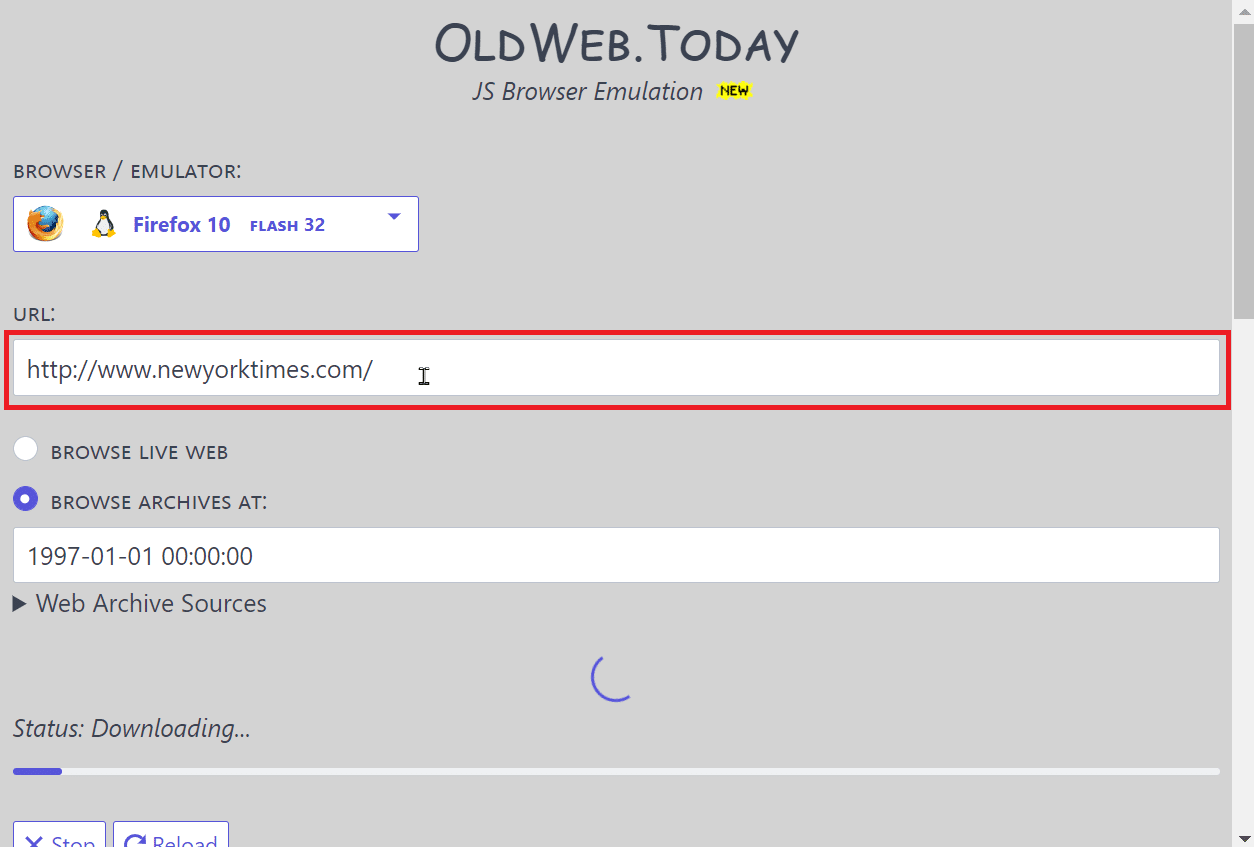
4. 在“BROWSE ARCHIVES AT:”框中输入你想要搜索的时间。
注:数字左边为日期,右边为时间。
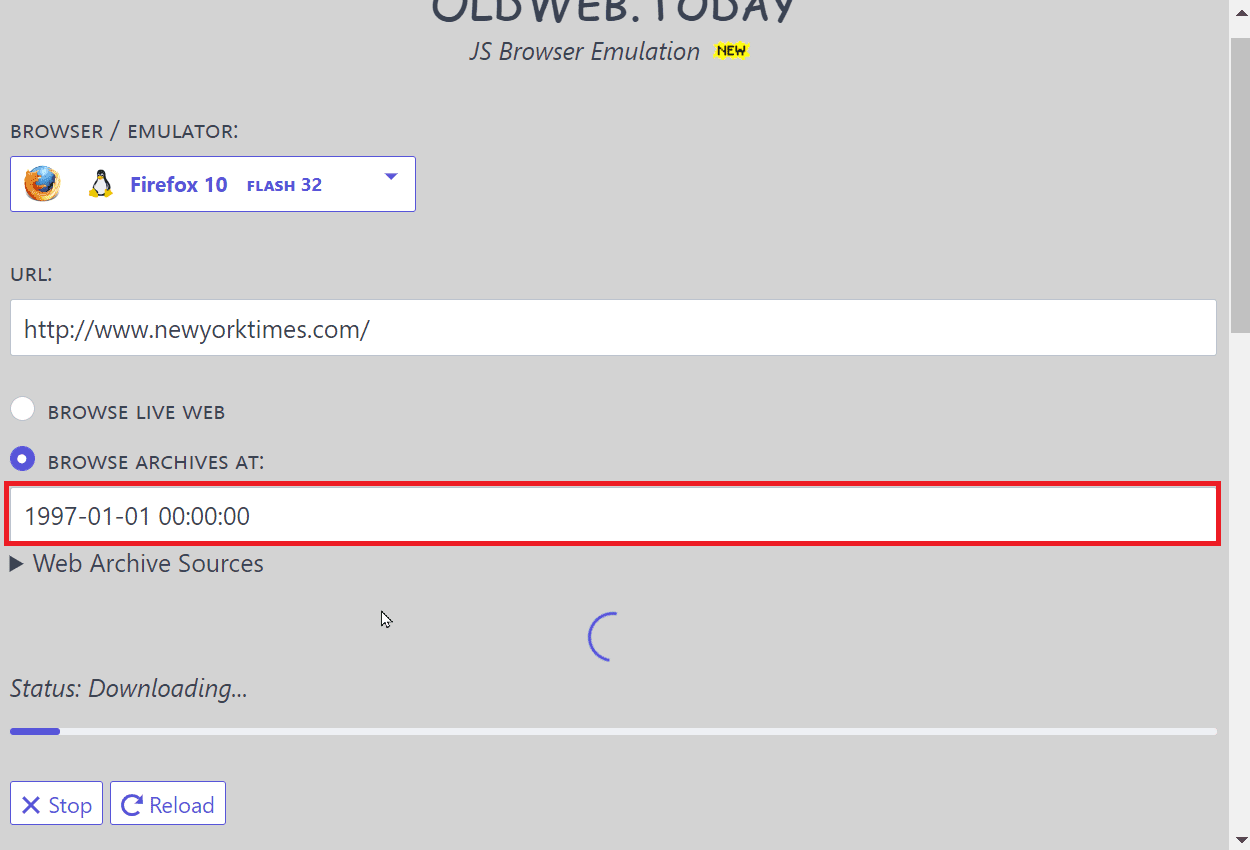
5. 现在,网站将根据你的输入自动搜索。 这可能需要一些时间,因为该服务正在模拟旧浏览器的感觉,并且还在搜索其数据库中存在的众多档案。
注意:由于搜索是由全世界许多人完成的,有时你会被置于等待区,因此你可能需要等待才能进行搜索。等待后,你可以搜索网址,网站会弹出你选择的网站,并带有模拟的旧浏览器。
3. 美国国会图书馆
美国国会图书馆是最大的档案馆之一,其中包括书籍、录音以及世界各地网站的各种版本。你可以使用搜索功能来搜索这个存档中的所有网站。对于你搜索的每个网站,存档中都会有关于每个网站的描述和其他有用的信息。存档系统的设置甚至允许你在不使用搜索功能的情况下搜索网站,这可以通过存档所使用的类别系统来实现。美国国会档案馆还拥有一个庞大的旧图片库,你可以免费使用这些图片。可以使用此工具查找不再存在的旧网站。
1. 导航至美国国会图书馆网站。
2. 进入“Everything”下拉框并选择“Web Pages”。
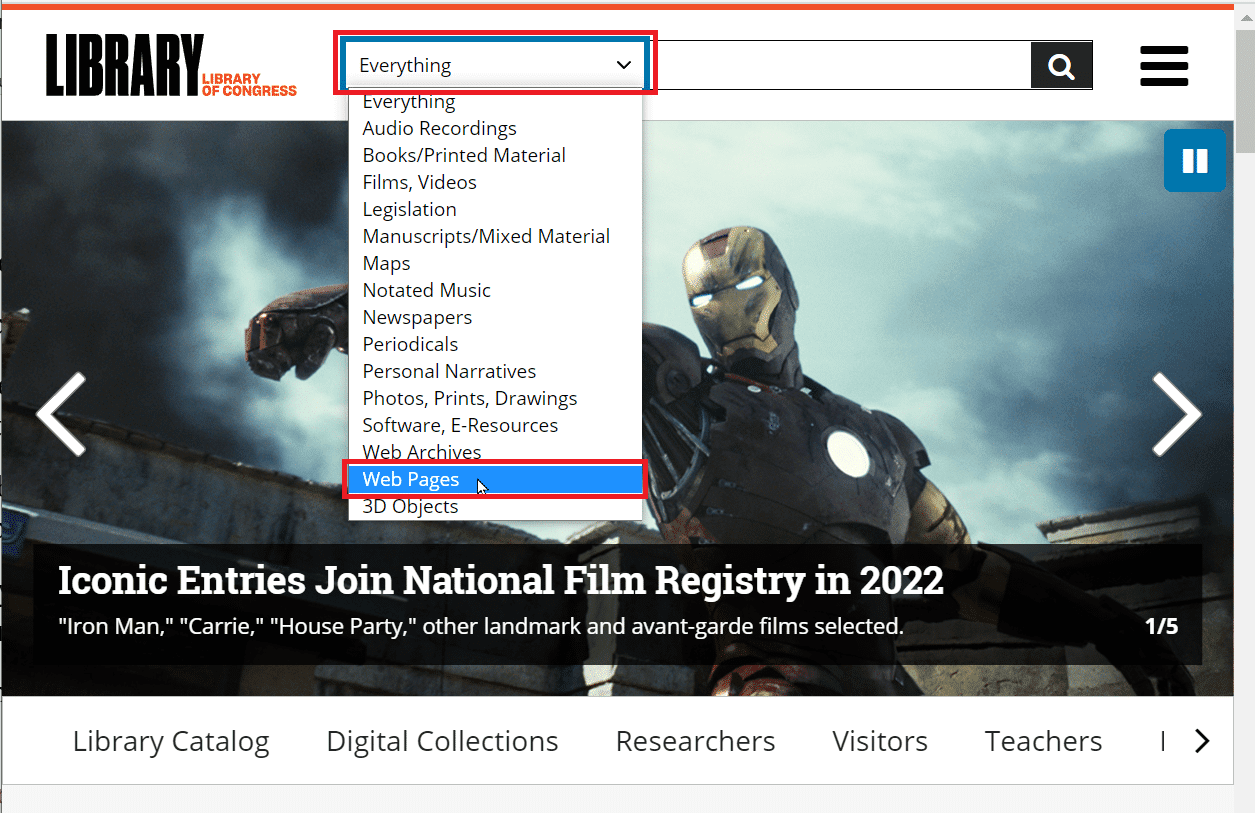
3. 输入需要搜索的网址,点击放大镜图标进行搜索。
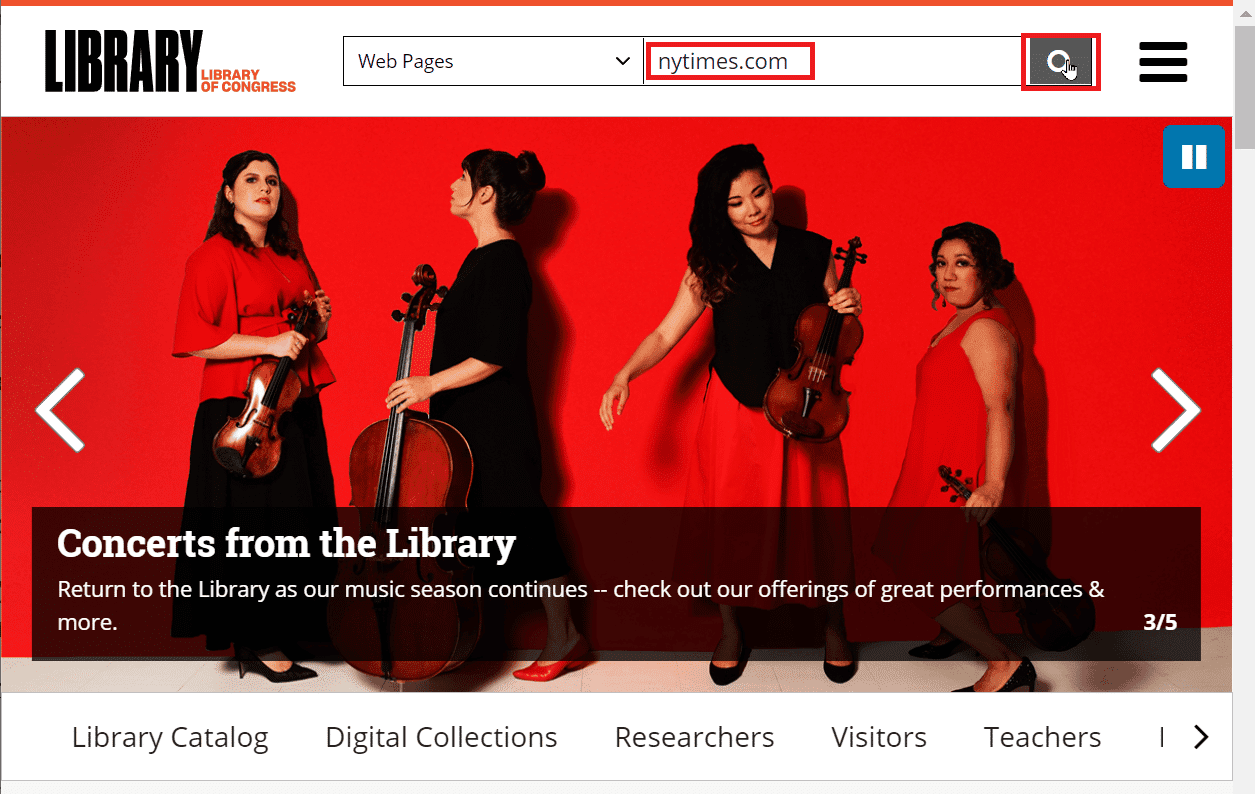
4. 你可以对你的选项进行排序,例如查看方式以及按时间、日期和位置排序。
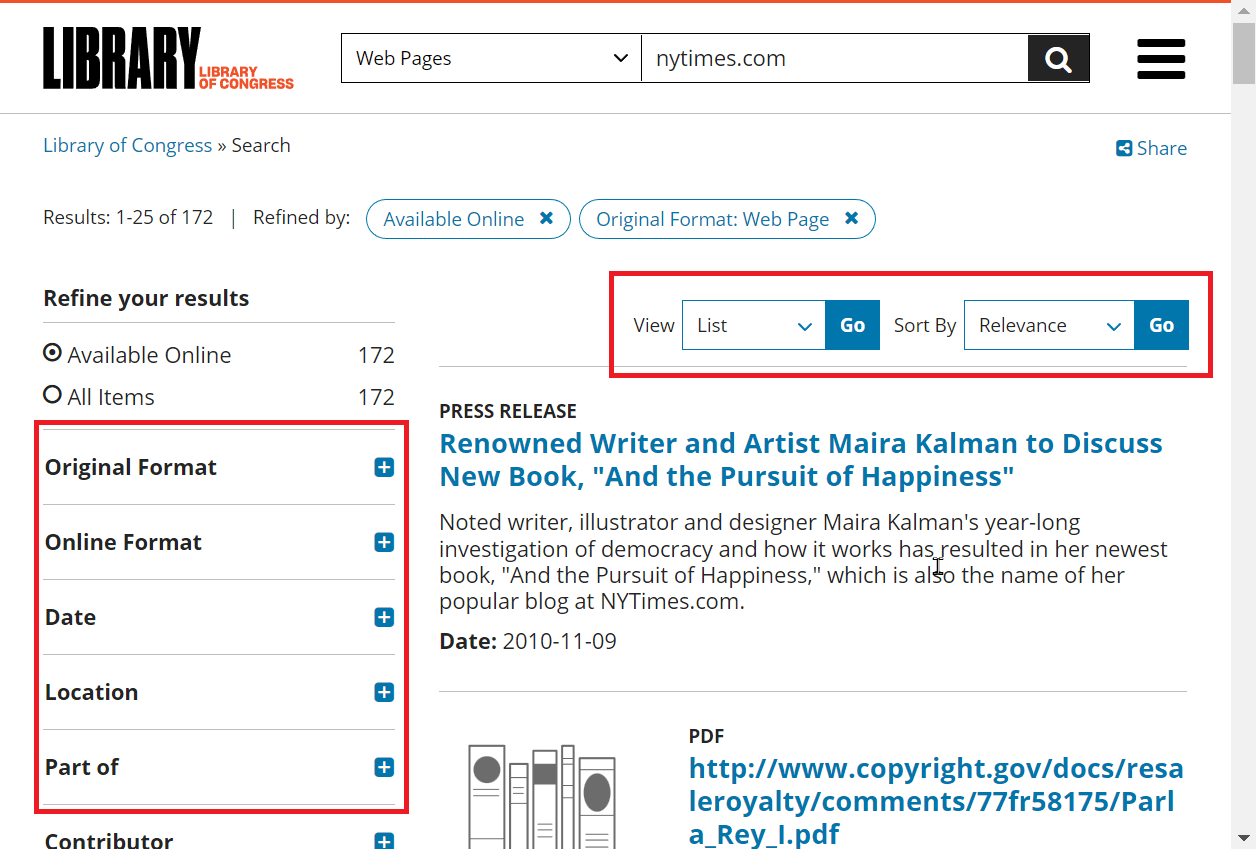
5. 当你打开一个特定的网站页面时,存档会允许你访问按时间排序的每个页面,这与Wayback Machine类似。
4. 今日存档
Archive.today是一个简单的存档网站,它由多年来存档的大型网站库组成。要查看网站的旧版本,你可以在搜索中使用URL进行搜索。它还有一个可以集成到谷歌浏览器中的Chrome扩展程序,方便随时搜索。
1. 访问今日存档官方网站。
2. 现在向下滚动,直到看到一个写着“我想在存档中搜索已保存的快照”的搜索引擎。

3. 在查询框中输入网址,点击搜索。
4. 搜索后,存档网站会按时间倒序显示所有可能的网站快照。
5. 点击文章进行查看。
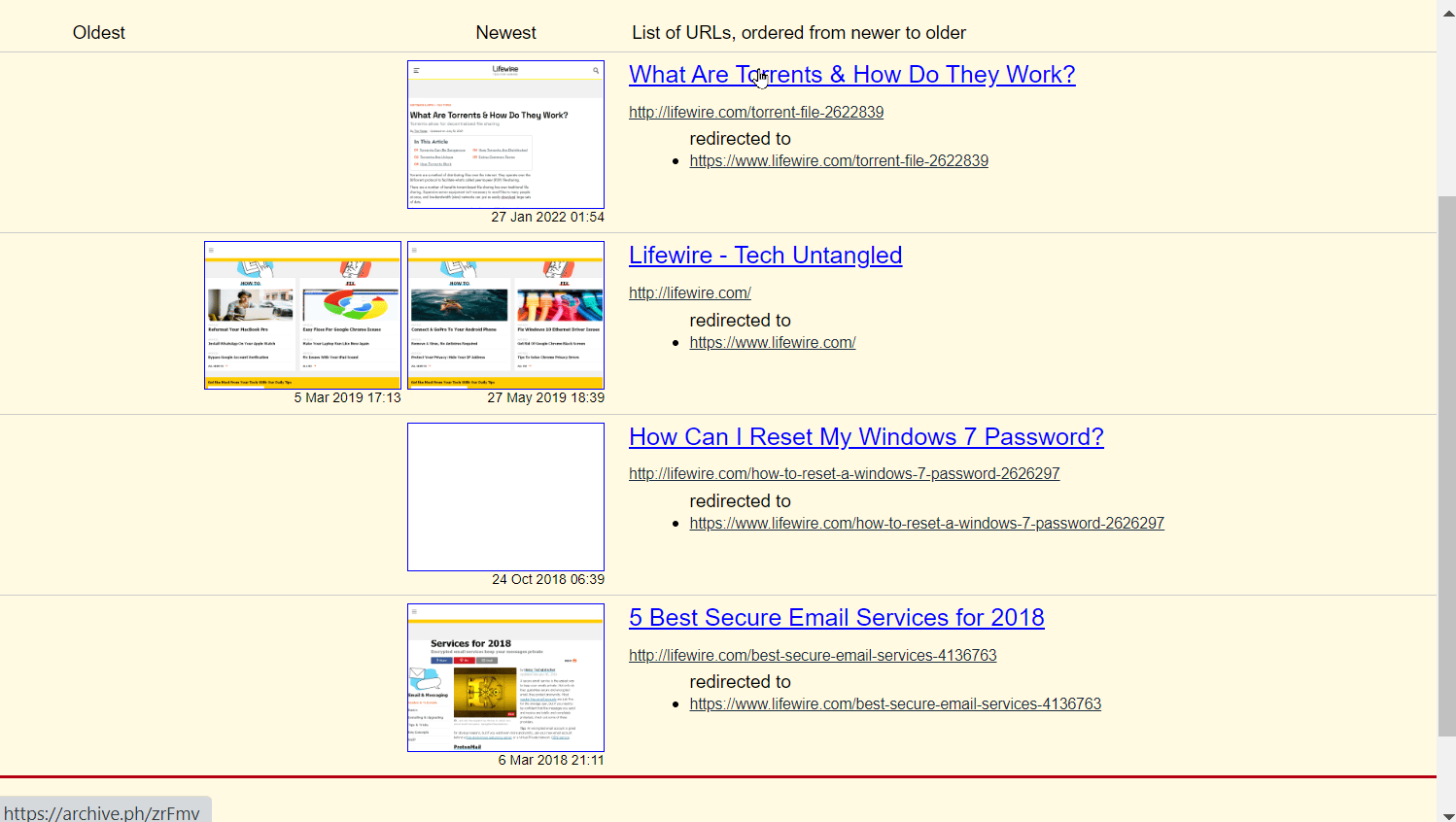
6. 点击“download.zip”以ZIP格式下载网页。
注意:存档网站的一项功能是将网页下载为ZIP文件,以便稍后查看或共享文件。
7. 它不像Wayback Machine那样庞大,但它的存档网站库可以帮助你发现大多数网站。
5. 英国网络档案馆
UK Web Archive拥有大量的网站。该站点的主要目的是将其存档中保存的所有英国站点,以便你可以访问其上的所有英国网站。这个存档站点的突出特点是你可以按词组、关键字和URL进行搜索。英国网络档案有一个名为“主题和主题页面”的类别,它会根据兴趣来展示所有档案。你也可以使用此网站来保存任何网站。UK Web Archive的缺点是它需要从特定的英国图书馆获得图书馆通行证才能查看某些网站。你还可以使用此工具查找不再存在的旧网站。
1. 前往英国网络档案馆网站。
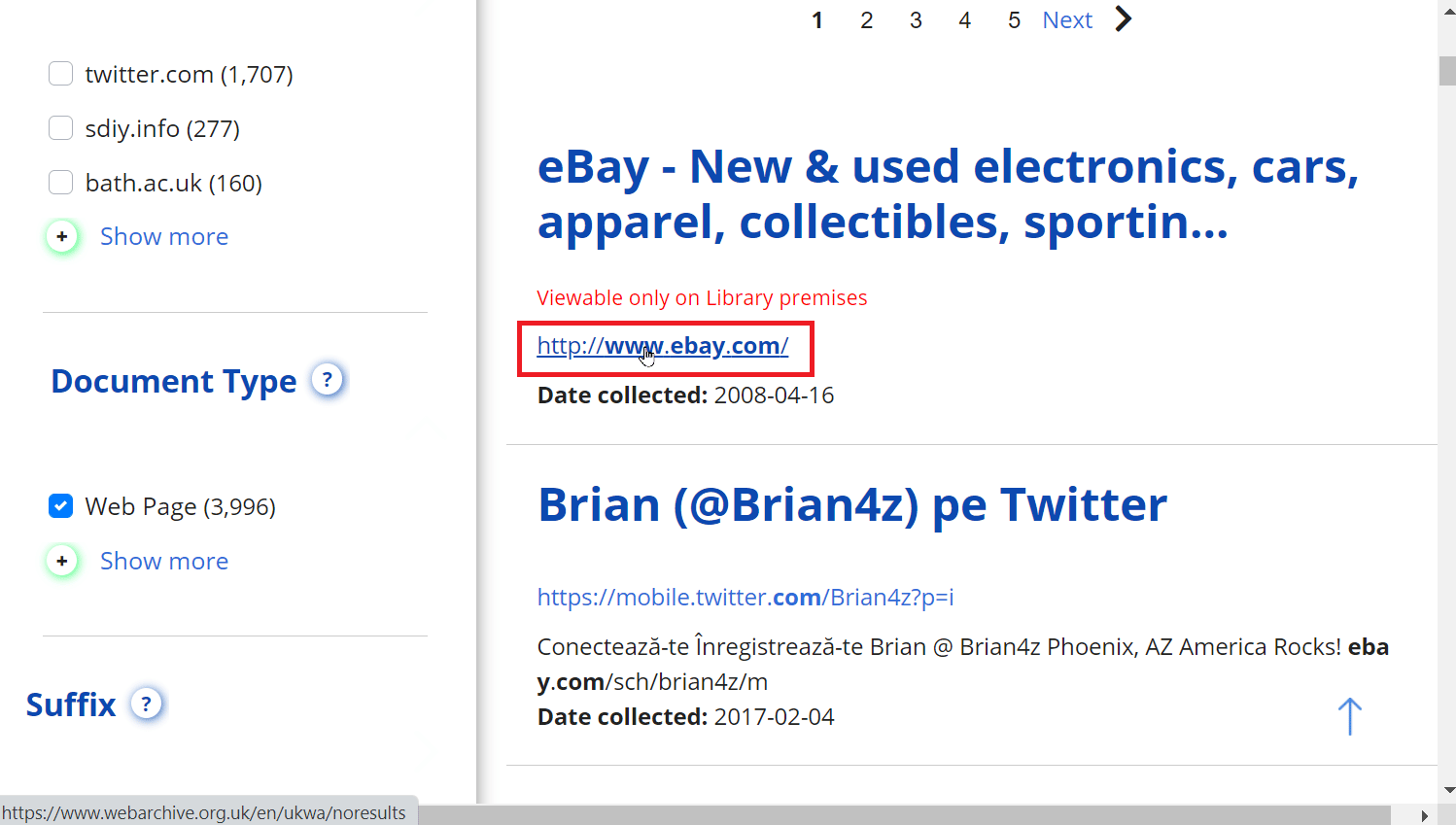
2. 在搜索栏中输入网站URL,然后点击搜索。

3. 将会显示你的结果。现在,点击提供的链接来访问该网站。
6. 网页缓存查看器
Web Cache Viewer是一个你可以在浏览器上使用的扩展程序,它可以帮助你搜索旧网站。它只从互联网档案和谷歌缓存中获取信息,没有自己的记录,因此这个工具比这里提到的其他选项工作得更快。
1. 访问Web Cache Viewer的扩展页面,将扩展程序添加到你的Chrome浏览器。
注意:在上面的示例中,使用了Brave浏览器,因为它是一个基于谷歌浏览器的浏览器。
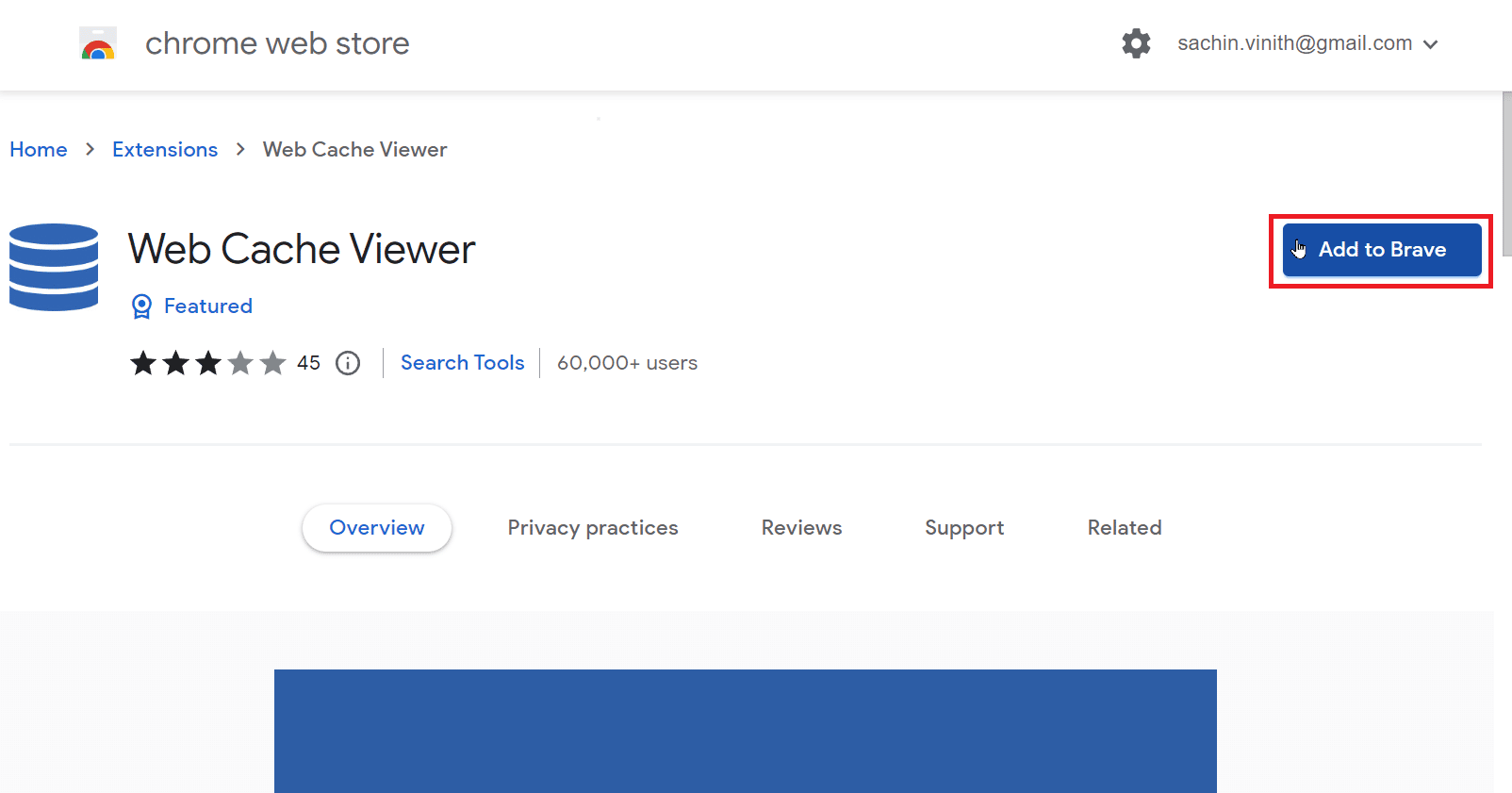
2. 前往你想要查看旧版本的网站。
3. 右键点击页面,然后点击“Web Cache Viewer”。
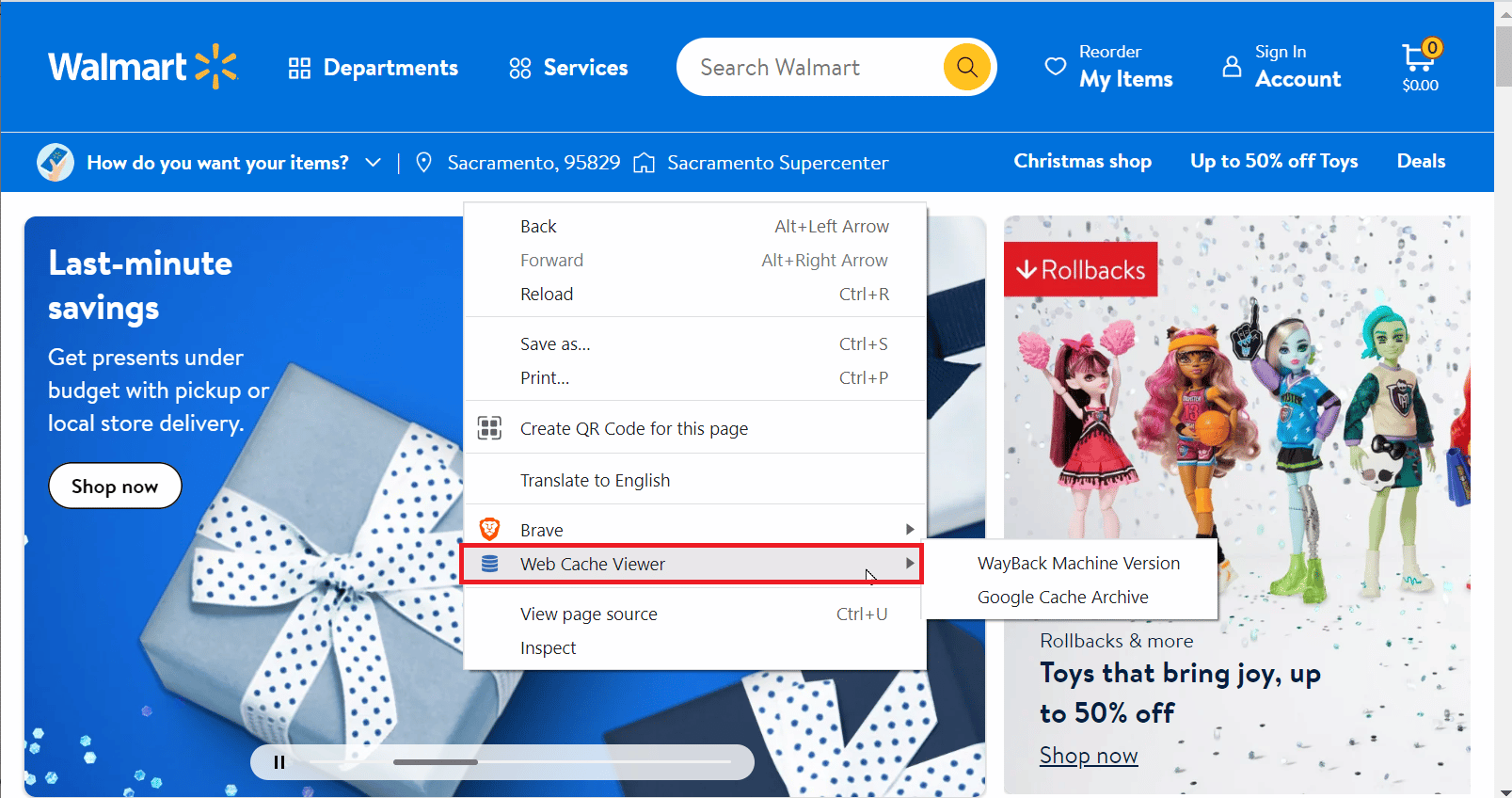
4. 有两个选项可供选择,分别是“Wayback Machine Archive”和“Google Cache Archive”。
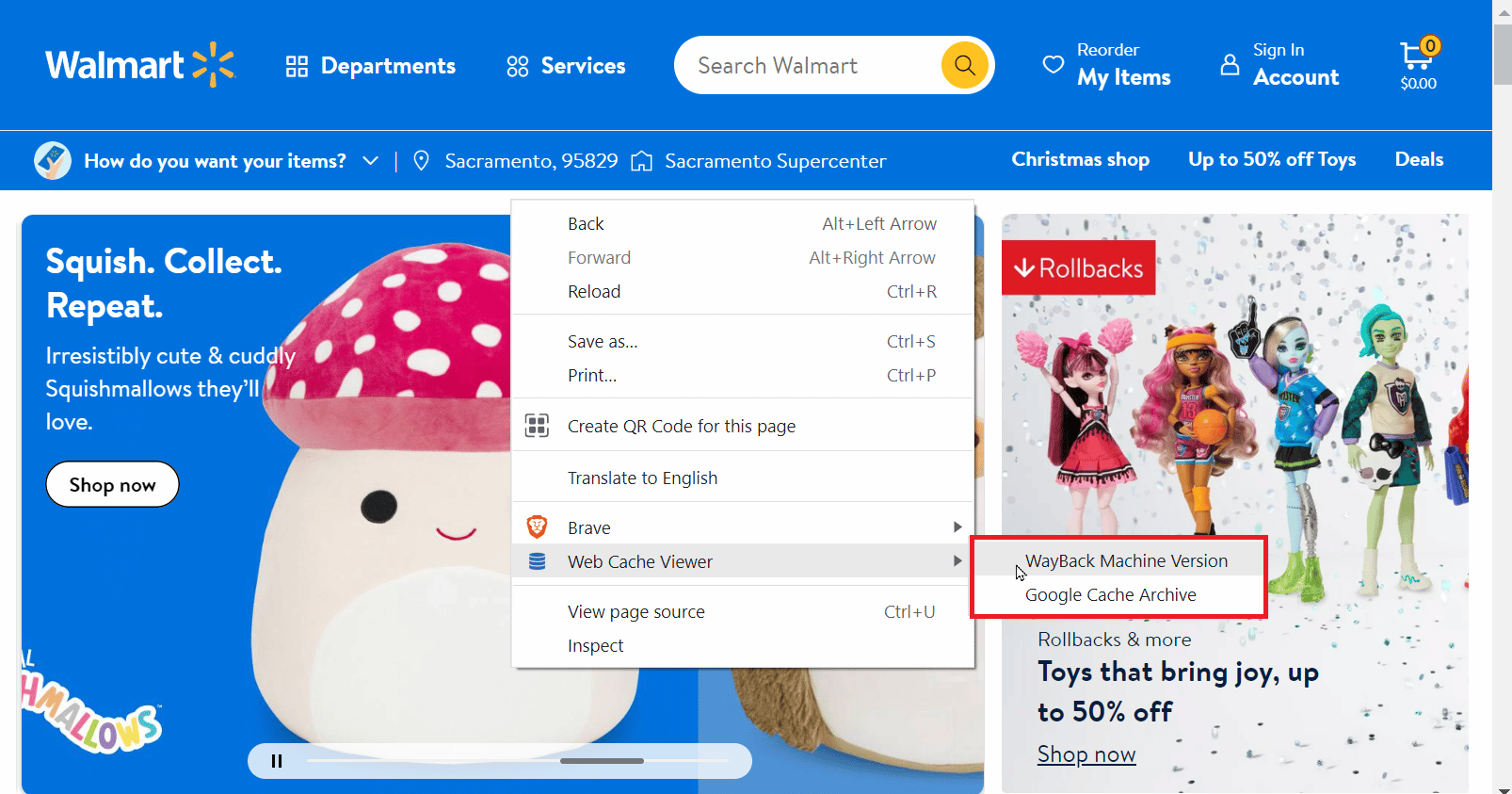
5. 点击任何选项,即可打开相应网站的版本。
6. Web Cache Viewer将打开一个新的标签页,以立即查看网站的所有缓存副本。
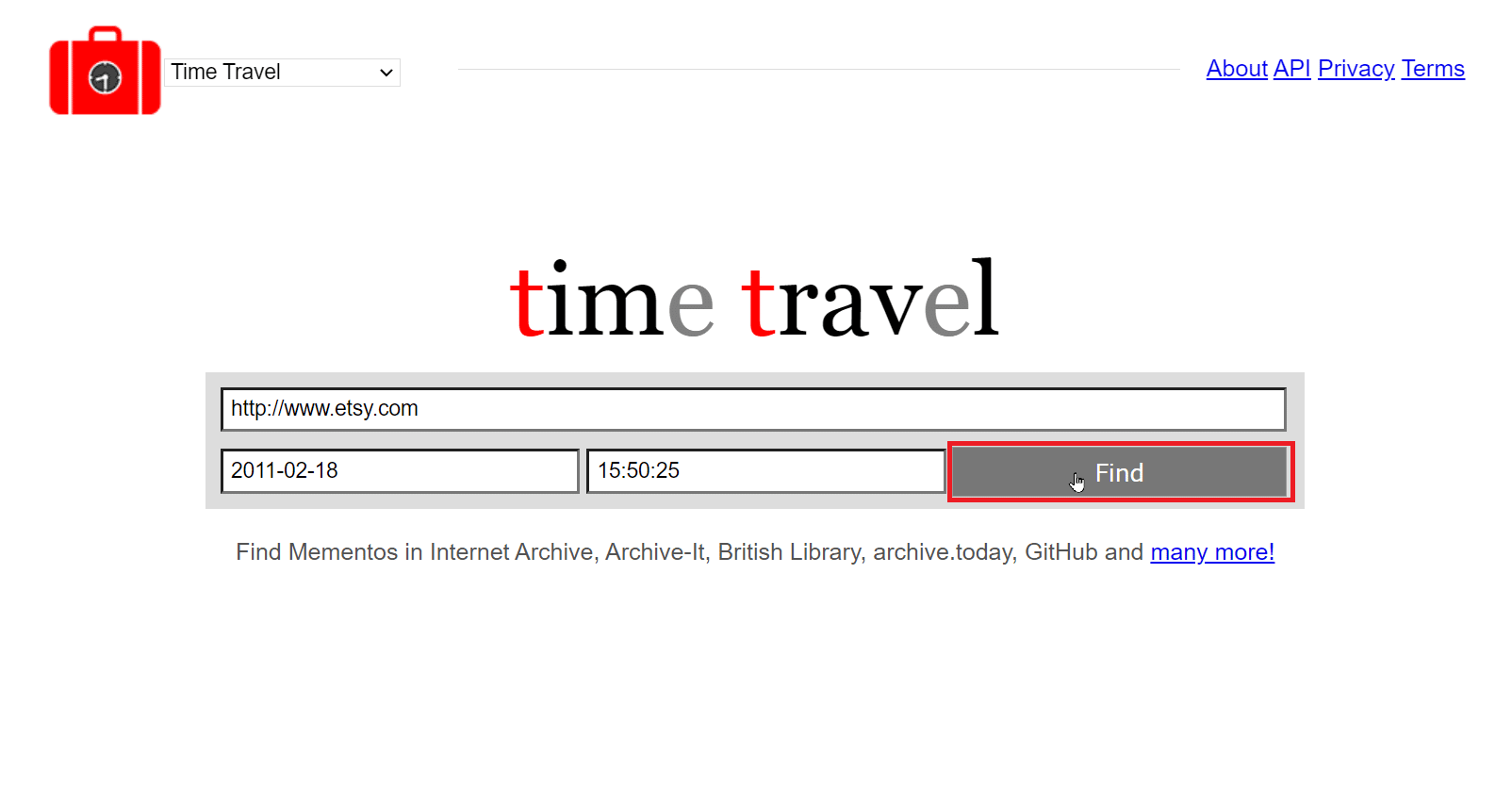
7. 纪念时光旅行
这个存档网站允许你搜索网站的存档。输入你想要缓存副本的URL后,它会搜索其他12个互联网存档网站。该服务的一个特点是,你还可以选择以HTML格式嵌入网页。Memento time travel也有一个Chrome扩展程序。你可以使用此网站来查找不再存在的旧网站。
1. 访问纪念时光旅行官方网站。
2. 在出现的框中输入网站的URL和日期。你还可以在日期框附近的框中输入时间。
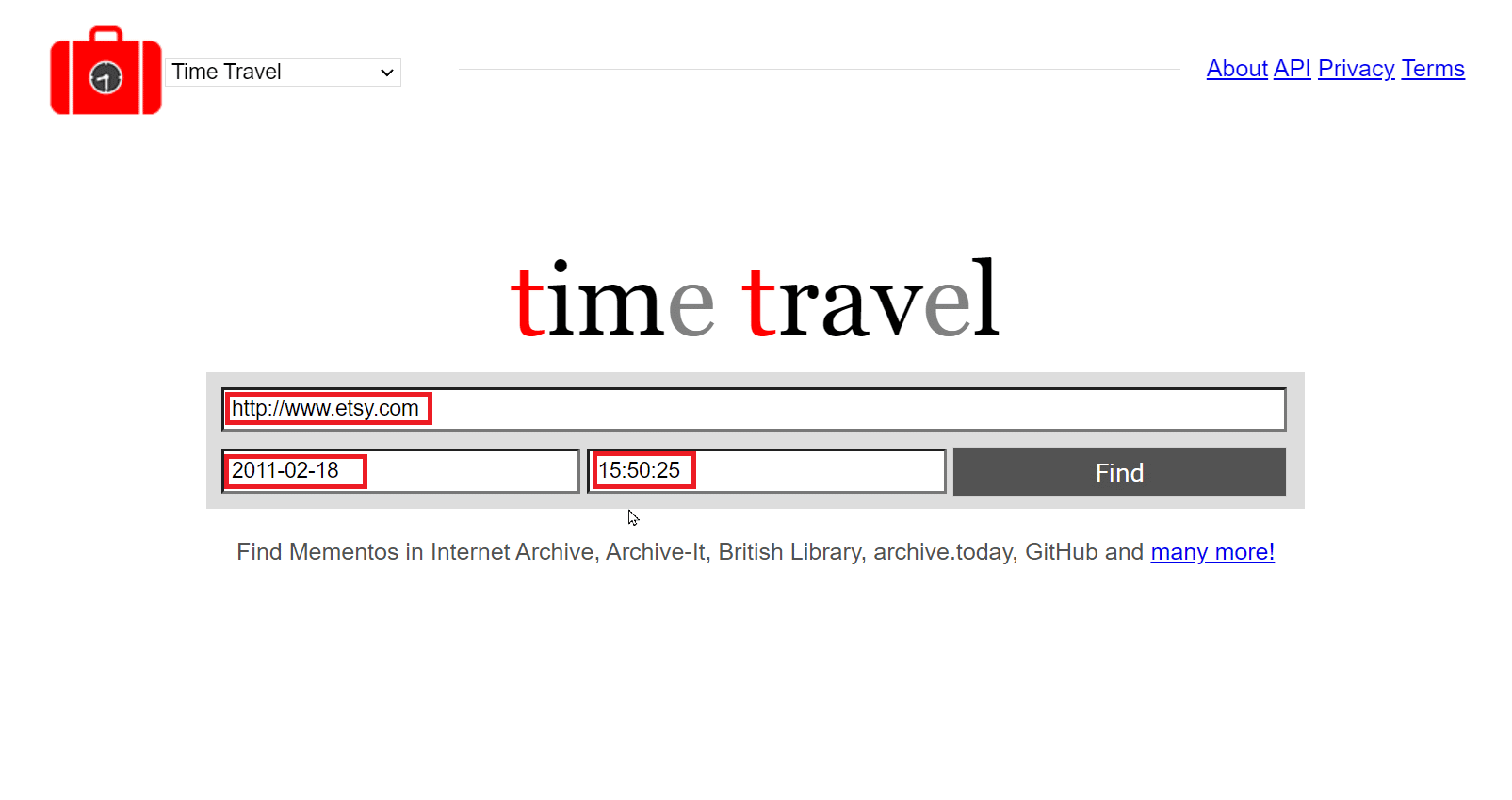
3. 点击“查找”以使用给定的详细信息开始搜索。
***
希望以上这篇关于如何查找不再存在的旧网站的文章能对你有所帮助,并且你能轻松地找到旧网站。请告诉我们哪种方法最适合你。如果你对本文有任何疑问或建议,请随时在下方的评论区提出,谢谢!