本文将为数据科学家和机器学习团队介绍并详细阐述一些最优秀的 Python 库。
Python 是一种理想的语言,这主要归功于它提供的丰富库,这些库在数据科学和机器学习领域发挥着至关重要的作用。
Python 库在数据输入/输出 (I/O)、数据分析以及数据处理和探索等数据操作方面表现出色,因此受到数据科学家和机器学习专家的广泛青睐。
Python 库:它们是什么?
Python 库是预编译代码(包括类和方法)的大型集合,这些预编译代码以模块的形式存在,使开发人员不必从头开始编写所有代码。
Python 在数据科学和机器学习领域的重要性
Python 拥有众多为机器学习和数据科学专家量身定制的顶级库。
其简洁的语法使得实现复杂的机器学习算法变得高效。此外,这种简单的语法还缩短了学习曲线,使理解更为容易。

Python 还支持快速原型开发和应用程序的流畅测试。
Python 的庞大社区为数据科学家提供了便利,他们可以在需要时随时寻求查询解决方案。
Python 库的实用性
Python 库在机器学习和数据科学领域中对于创建应用程序和模型至关重要。
这些库在帮助开发人员实现代码重用方面起着关键作用。 开发人员可以通过导入相关库来完成特定功能,而不是重新“发明轮子”。
机器学习和数据科学中常用的 Python 库
数据科学专家推荐了一系列对数据科学爱好者至关重要的 Python 库。根据它们在应用程序中的相关性,机器学习和数据科学专家会使用不同的 Python 库,这些库大致可以分为用于部署模型、挖掘和抓取数据、数据处理和数据可视化的库。
本文将重点介绍数据科学和机器学习领域中一些最常用的 Python 库。
现在,让我们来详细了解这些库。
NumPy
NumPy,全称为“Numerical Python”,是一个使用优化的 C 代码构建的 Python 库。 它因其强大的数学和科学计算能力而深受数据科学家喜爱。
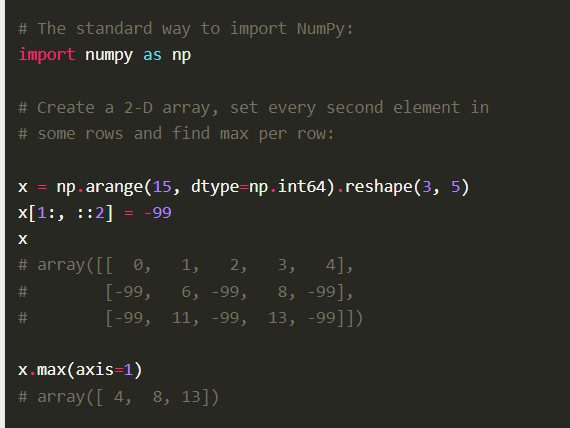
特点
- NumPy 采用高级语法,便于经验丰富的程序员使用。
- 由于其构成部分是经过优化的 C 代码,因此该库具有相对较高的性能。
- 它拥有数值计算工具,包括傅里叶变换、线性代数和随机数生成器等功能。
- 它是开源的,允许其他开发人员为其做出贡献。
NumPy 还具备其他综合功能,例如数学运算的向量化、索引以及实现数组和矩阵的关键概念。
Pandas
Pandas 是机器学习领域著名的库,它提供高级数据结构和工具,可以轻松高效地分析大量数据集。 该库仅需少量命令即可执行复杂的数据操作。
该库内置了许多方法,可以在将数据插入一维和多维表格之前,对数据进行分组、索引、检索、拆分、重组和筛选。
Pandas 库的主要功能
- Pandas 可以轻松地将数据标记到表格中,并自动对齐和索引数据。
- 它可以快速加载和保存 JSON 和 CSV 等数据格式。
它具有良好的数据分析功能和高度的灵活性,因此效率很高。
Matplotlib
Matplotlib 是一个 Python 2D 图形库,可以轻松处理来自众多来源的数据。 它生成的可视化效果可以是静态的、动画的和交互式的,用户可以放大它们,从而高效地进行可视化和创建图表。 它还允许自定义布局和视觉样式。
其开源文档提供了大量必要的工具。
Matplotlib 导入辅助类,用于处理年、月、日和周,从而高效地操作时间序列数据。
Scikit-learn
如果你正在考虑使用一个库来处理复杂的数据,那么 Scikit-learn 绝对是你的理想选择。 机器学习专家广泛使用 Scikit-learn。 该库与 NumPy、SciPy 和 Matplotlib 等其他库配合使用。 它提供可用于生产应用程序的监督和无监督学习算法。

Scikit-learn Python 库的特点
- 识别对象类别,例如在图像识别应用程序中使用 SVM 和随机森林等算法。
- 使用回归将对象与连续值属性预测相关联。
- 特征提取。
- 降维,从而减少需要考虑的随机变量数量。
- 将相似对象聚类为集合。
Scikit-learn 库在从文本和图像数据集中提取特征方面非常有效。 此外,还可以检查未见过数据的监督模型的准确性。 其众多可用算法使得数据挖掘和其他机器学习任务成为可能。
SciPy
SciPy (Scientific Python Code) 是一个机器学习库,提供适用于数学函数和算法的模块,应用范围广泛。 其算法可以解决代数方程、插值、优化、统计和积分等问题。
它的主要特点在于它是 NumPy 的扩展,它增加了求解数学函数的工具,并提供了稀疏矩阵等数据结构。
SciPy 使用高级命令和类来操作和可视化数据。 其数据处理和原型系统使其成为更有效的工具。
此外,SciPy 的高级语法使任何经验水平的程序员都可以轻松使用。
SciPy 唯一的缺点是它只关注数字对象和算法,因此不提供任何绘图功能。
PyTorch
这个多功能的机器学习库通过 GPU 加速高效地实现张量计算,创建动态计算图和自动梯度计算。 Torch 库是一个基于 C 开发的开源机器学习库,它构建了 PyTorch 库。

主要特点包括:
- 由于其对主要云平台的良好支持,提供了无障碍开发和顺畅扩展。
- 强大的工具和库生态系统支持计算机视觉开发和自然语言处理 (NLP) 等其他领域。
- 它使用 Torch 脚本在急切模式和图形模式之间提供平滑过渡,同时使用 TorchServe 加速其生产路径。
- Torch 分布式后端允许在研究和生产中进行分布式训练和性能优化。
在开发 NLP 应用程序时,可以使用 PyTorch。
Keras
Keras 是一个开源机器学习 Python 库,用于试验深度神经网络。
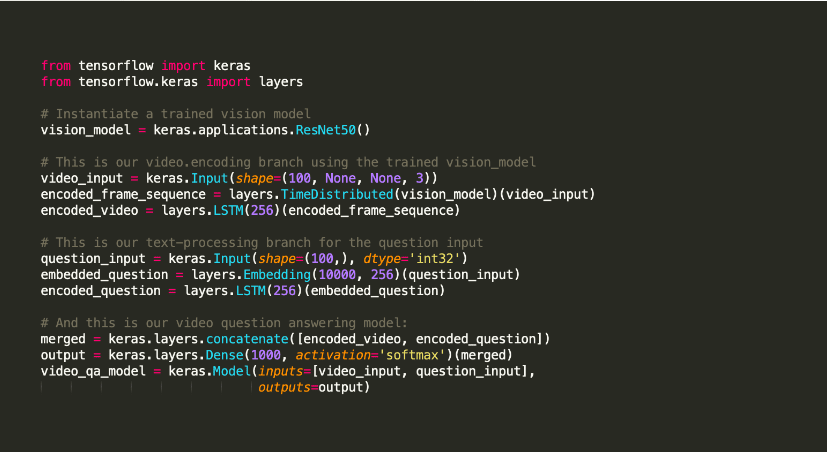
它以提供支持模型编译和图形可视化等任务的实用程序而闻名。 它将 TensorFlow 应用于其后端。 或者,你可以在后端使用 Theano 或 CNTK 等神经网络。 这种后端基础结构帮助它创建用于实现操作的计算图。
库的主要特点
- 它可以在中央处理器和图形处理器上高效运行。
- 使用 Keras 进行调试更容易,因为它基于 Python。
- Keras 是模块化的,因此具有表现力和适应性。
- 你可以通过直接将 Keras 模块导出到 JavaScript,从而在浏览器上运行 Keras,并将它部署到任何地方。
Keras 的应用包括神经网络构建块,如层和目标,以及其他有助于处理图像和文本数据的工具。
Seaborn
Seaborn 是一个用于统计数据可视化的有价值工具。
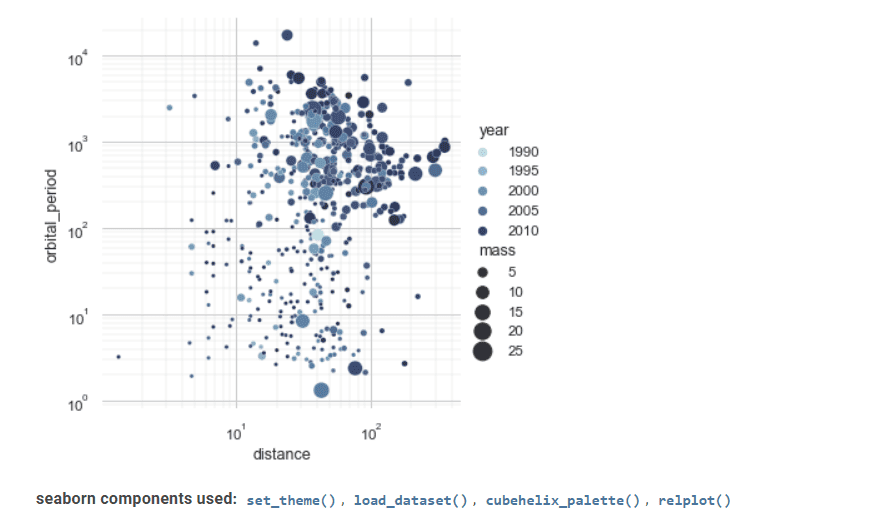
其先进的界面可以实现引人入胜且内容丰富的统计图形绘制。
Plotly
Plotly 是一个基于 Web 的 3D 可视化工具,它基于 Plotly JS 库构建。 它广泛支持各种图表类型,如折线图、散点图和箱线图。
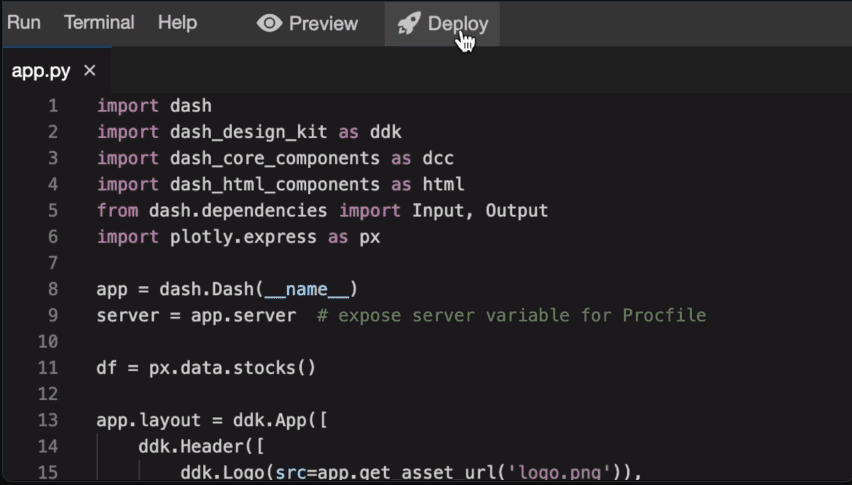
其应用包括在 Jupyter 笔记本中创建基于 Web 的数据可视化。
Plotly 非常适合可视化,因为它可以使用悬停工具指出图表中的异常值或异常。 你还可以自定义图表以满足你的偏好。
Plotly 的缺点是其文档已过时。 因此,用户可能会发现将其作为指南存在困难。 此外,它具有许多用户应该学习的工具。 跟踪所有这些工具可能具有挑战性。
Plotly Python 库的特点
- 它提供的 3D 图表允许多点交互。
- 它具有简化的语法。
- 你可以在分享积分的同时维护代码的隐私。
SimpleITK
SimpleITK 是一个图像分析库,它为 Insight Toolkit (ITK) 提供接口。 它基于 C++ 并且是开源的。
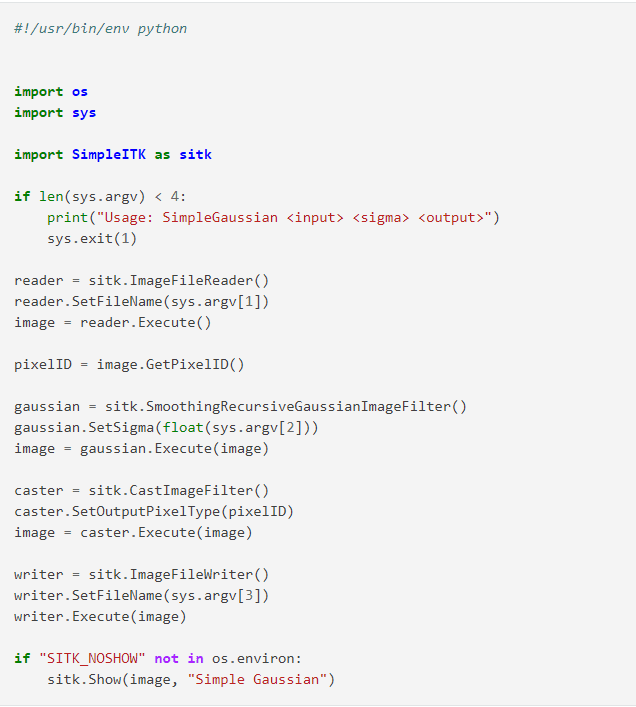
SimpleITK 库的特点
- 其图像文件 I/O 支持并可以转换多达 20 种图像文件格式,如 JPG、PNG 和 DICOM。
- 它提供了许多图像分割工作流过滤器,包括 Otsu、水平集和分水岭。
- 它将图像解释为空间对象而不是像素阵列。
其简化的界面可用于各种编程语言,如 R、C#、C++、Java 和 Python。
Statsmodels
Statsmodels 用于估计统计模型、执行统计检验并使用类和函数探索统计数据。
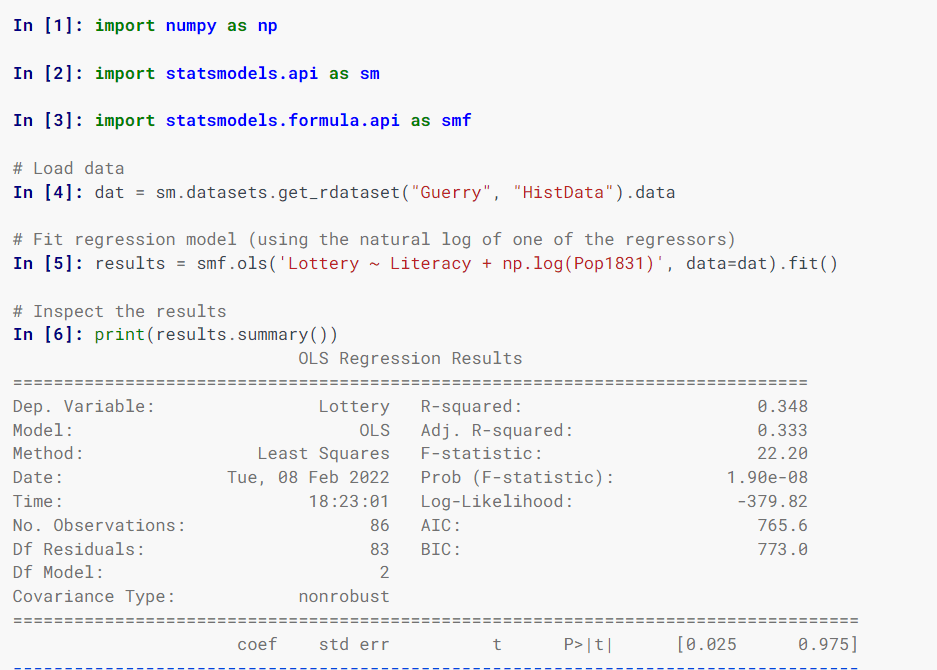
它使用 R 风格的公式、NumPy 数组和 Pandas 数据框来指定模型。
Scrapy
这个开源包是从网站检索(抓取)和抓取数据的首选工具。 它是异步的,因此速度相对较快。 Scrapy 具有使其高效的架构和功能。
另一方面,其安装因不同的操作系统而异。 此外,它不适用于基于 JS 构建的网站。 此外,它只能与 Python 2.7 或更高版本一起使用。
数据科学专家将其应用于数据挖掘和自动化测试。
特点
- 它可以以 JSON、CSV 和 XML 格式导出提要,并将它们存储在多个后端。
- 它具有从 HTML/XML 源收集和提取数据的内置功能。
- 你可以使用定义明确的 API 来扩展 Scrapy。
Pillow
Pillow 是一个用于操作和处理图像的 Python 图像处理库。
它增加了 Python 解释器的图像处理功能,支持各种文件格式,并提供了出色的内部表示。
借助 Pillow,可以轻松访问以基本文件格式存储的数据。
总结
本文总结了我们对数据科学家和机器学习专家使用的一些最出色 Python 库的探讨。
正如本文所展示的,Python 提供了更多有用的机器学习和数据科学包。 你还可以在其他领域中使用 Python 的其他库。
你可能还想了解一些最优秀的数据科学笔记本。
祝你学习愉快!