試想一下,您擁有一套龐大的基礎設施,其中包含各式各樣的設備。這些設備需要定期維護,或者至少要確保它們不會對周遭環境造成潛在的危險。
一種實現此目標的方式是定期派遣人員到每個地點進行檢查,確認一切運作正常。這個方法在某種程度上可行,但相當耗時且耗費資源。如果基礎設施的規模過於龐大,您可能根本無法在一年內完成所有地點的巡檢。
另一種更有效率的方法是將此過程自動化,讓雲端上的任務為您執行驗證。若要實現此目標,您需要執行以下步驟:
👉 首先,您需要一個快速獲取設備圖片的流程。雖然這仍然可以由人來完成,但相較於人工執行所有設備驗證流程,拍攝單張圖片仍是快速許多。這個過程也可以透過汽車甚至無人機拍攝的照片來完成,進一步加快圖片收集的速度並使其更自動化。
👉 接著,您需要將所有取得的圖片傳送到雲端上的特定位置。
👉 在雲端,您需要設定一個自動化的任務,從雲端位置提取圖片,並使用經過訓練的機器學習模型進行處理,以識別設備的損壞或異常情況。
👉 最後,結果必須對相關使用者可見,以便安排有問題設備的維修。
接下來,讓我們看看如何利用 AWS 雲端中的圖片實現異常檢測。亞馬遜提供了一些預先構建的機器學習模型,我們可以將其應用於此目的。
如何建立視覺異常檢測模型
建立用於視覺異常檢測的模型需要執行以下幾個步驟:
第一步:清楚定義要解決的問題以及要檢測的異常類型。這將幫助您確定訓練模型所需的適當測試數據集。
第二步:收集代表正常和異常情況的大量圖像數據集。標記圖像,以指示哪些圖像屬於正常,哪些包含異常。
第三步:選擇適合任務的模型架構。這可能包括選擇預先訓練的模型並針對您的特定用例進行微調,或者從頭開始建立客製化模型。
第四步:使用準備好的數據集和選定的演算法訓練模型。這表示可以利用遷移學習來使用預先訓練的模型,或者使用卷積神經網路 (CNN) 等技術從頭開始訓練模型。
如何訓練機器學習模型
資料來源:aws.amazon.com
在 AWS 上訓練用於視覺異常檢測的機器學習模型通常涉及幾個重要的步驟。
#1. 收集數據
首先,您需要收集並標記代表正常和異常情況的大型圖像數據集。數據集越大,模型的訓練效果越好,準確性也越高。但同時,訓練模型所需的時間也較長。
通常,您會希望測試集中至少有 1000 張圖片,以便取得良好的開端。
#2. 準備數據
必須先對圖像數據進行預處理,以便機器學習模型能夠順利提取所需資訊。預處理可能包含各種不同的步驟,例如:
- 將輸入圖像清理到個別的子資料夾中,更正元數據等。
- 調整圖像大小以符合模型的分辨率要求。
- 將圖像分散成更小的圖像塊,以進行更有效率的並行處理。
#3. 選擇模型
接著選擇合適的模型以執行對應的工作。您可以選擇預先訓練的模型,或者建立適合視覺異常檢測的客製化模型。
#4. 評估結果
模型處理完您的數據集後,您應該驗證其效能。此外,您需要檢查結果是否滿足您的需求。例如,可能需要超過 99% 的輸入數據都能產生正確的結果。
#5. 部署模型
如果您對結果和效能感到滿意,請將特定版本的模型部署到 AWS 帳戶環境中,以便流程和服務可以開始使用。
#6. 監控和改進
讓模型在各種測試任務和圖像數據集上運行,持續評估所需的參數是否仍能維持檢測的準確性。
如果準確性下降,請使用包含模型產生錯誤結果的新數據集,重新訓練模型。
AWS 機器學習模型
現在,讓我們看看您可以在亞馬遜雲端中利用的一些具體模型。
AWS Rekognition
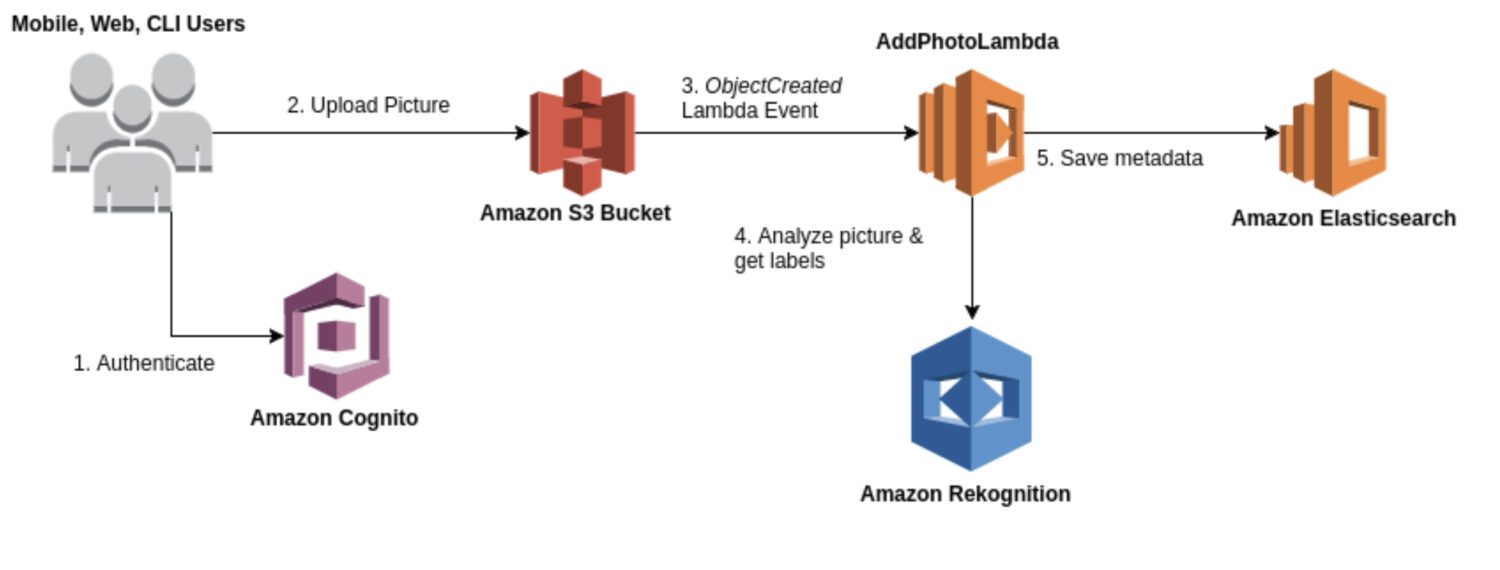
資料來源:aws.amazon.com
Rekognition 是一種通用的圖像和影片分析服務,可用於各種應用情境,例如人臉辨識、物件偵測和文字辨識。大多數情況下,您會使用 Rekognition 模型產生初始的原始偵測結果,以形成已識別異常的數據湖。
它提供了一系列無需額外訓練即可使用的預先建置模型。Rekognition 還提供高精度和低延遲的圖像和影片即時分析。
以下是一些典型的應用情境,其中 Rekognition 是異常檢測的理想選擇:
- 您有一個用於異常檢測的通用案例,例如檢測圖像或影片中的異常。
- 您需要執行即時異常檢測。
- 您需要將異常檢測模型與 Amazon S3、Amazon Kinesis 或 AWS Lambda 等 AWS 服務整合。
以下是一些可以使用 Rekognition 檢測到的異常具體範例:
- 臉部異常,例如偵測到超出正常範圍的臉部表情或情緒。
- 場景中遺失或錯放的物件。
- 拼寫錯誤的單字或不尋常的文字模式。
- 場景中異常的照明條件或意想不到的物體。
- 圖片或影片中不當或冒犯性的內容。
- 動作的突然變化或意想不到的動作模式。
AWS Lookout for Vision
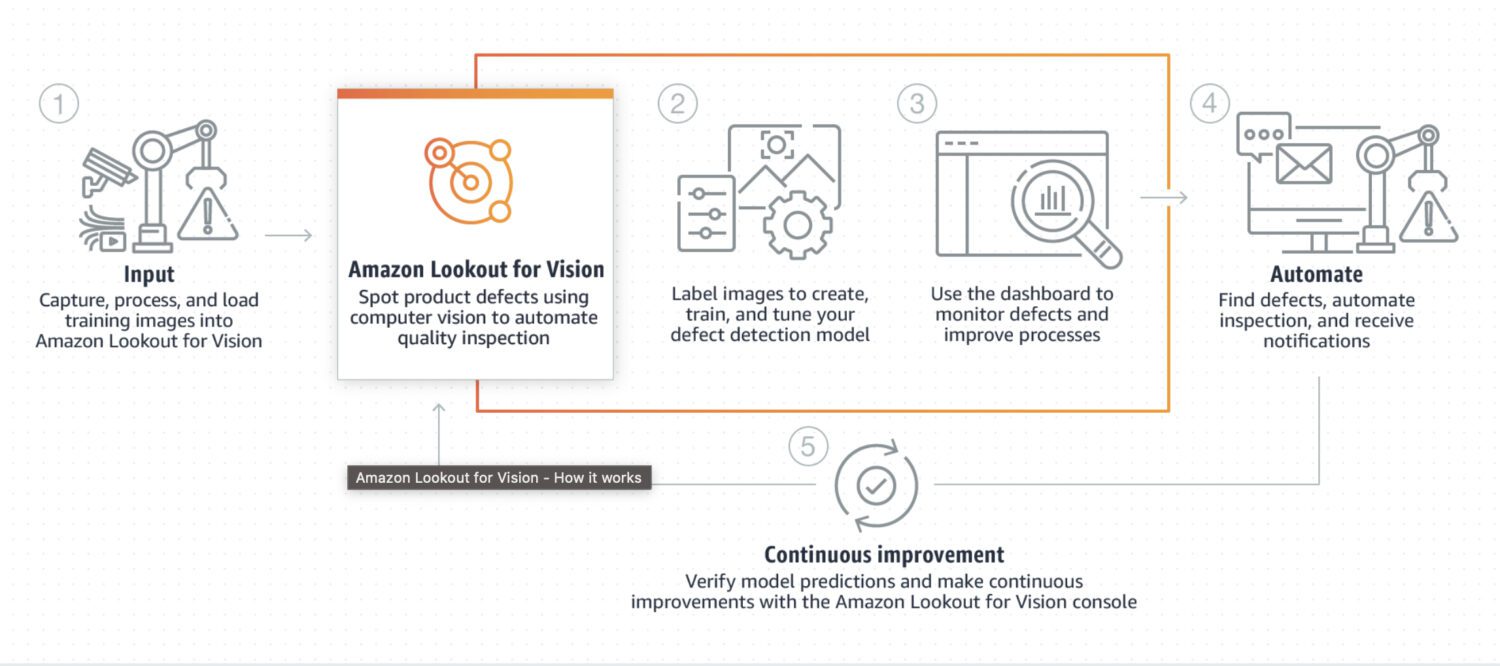
資料來源:aws.amazon.com
Lookout for Vision 是一個專為工業流程(例如製造和生產線)中的異常檢測而設計的模型。通常需要一些客製化程式碼,使用 Python 程式語言對圖像進行特定預處理和後處理。大多數情況下,它會專注於圖片中非常特定的問題。
它需要使用正常和異常圖像的數據集進行客製化訓練,以建立用於異常檢測的客製化模型。它並非以即時性為重點,而是專為圖像的批次處理而設計,著重於準確性和精確度。
以下是一些典型的應用情境,如果您需要檢測,Lookout for Vision 會是不錯的選擇:
- 檢測製產品中的缺陷或識別生產線上的設備故障。
- 您需要處理大型的圖像或其他數據集。
- 您需要檢測工業流程中的即時異常。
- 您需要將異常檢測與其他 AWS 服務整合,例如 Amazon S3 或 AWS IoT。
以下是一些可以使用 Lookout for Vision 檢測到的異常具體範例:
- 檢測製產品中的缺陷,例如刮痕、凹痕或其他瑕疵,這些瑕疵可能會影響產品品質。
- 檢測生產線上的設備故障,例如偵測到損壞或故障的機器,這可能會導致延誤或安全隱患。
- 檢測生產線上的品質控制問題,例如偵測到不符合規格或公差的產品。
- 檢測生產線上的安全隱患,例如偵測到可能對工人或設備構成風險的物體或材料。
- 檢測生產過程中的異常,例如偵測到生產線上材料或產品流的意外變化。
AWS Sagemaker
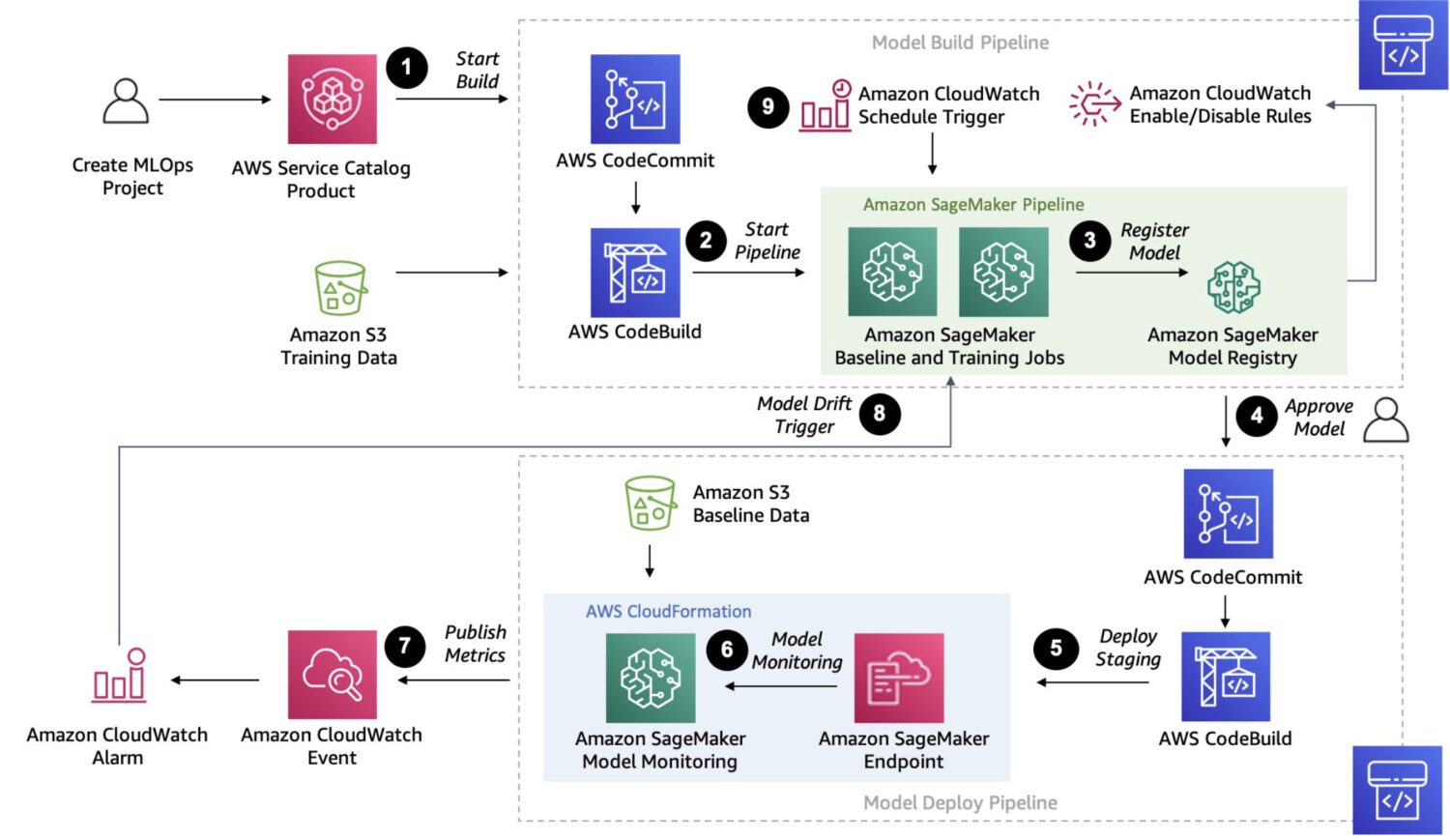
資料來源:aws.amazon.com
Sagemaker 是一個完全託管的平台,用於建立、訓練和部署客製化的機器學習模型。
這是一個更強大的解決方案。事實上,它提供了一種將多個多步驟流程連接並執行到一個接一個任務鏈的方法,就像 AWS Step Functions 可以做的那樣。
但由於 Sagemaker 使用臨時的 EC2 執行個體進行處理,因此與 AWS Step Functions 中的 AWS lambda 函數不同,單個任務處理沒有 15 分鐘的限制。
您還可以利用 Sagemaker 進行自動模型調整,這絕對是一個使其脫穎而出的功能。最後,Sagemaker 可以輕鬆地將模型部署到生產環境中。
以下是一些典型的應用情境,其中 SageMaker 是異常檢測的理想選擇:
- 預先建置的模型或 API 無法涵蓋的特定應用情境,以及您是否需要建立客製化模型來滿足您的特定需求。
- 如果您有大量的圖像或其他數據。在這種情況下,預先建置的模型可能需要進行一些預處理,但 Sagemaker 無需這些處理即可完成。
- 如果您需要執行即時異常檢測。
- 如果您需要將您的模型與其他 AWS 服務整合,例如 Amazon S3、Amazon Kinesis 或 AWS Lambda。
以下是一些 Sagemaker 能夠執行的典型異常檢測:
- 金融交易中的欺詐檢測,例如異常的消費模式或超出正常範圍的交易。
- 網路流量中的網路安全,例如異常的數據傳輸模式或與外部伺服器的意外連線。
- 醫學影像中的醫學診斷,例如檢測腫瘤。
- 設備效能異常,例如檢測到振動或溫度的變化。
- 製造過程中的品質控制,例如檢測產品缺陷或識別與預期品質標準的偏差。
- 不尋常的能源使用模式。
如何將模型整合到無伺服器架構中
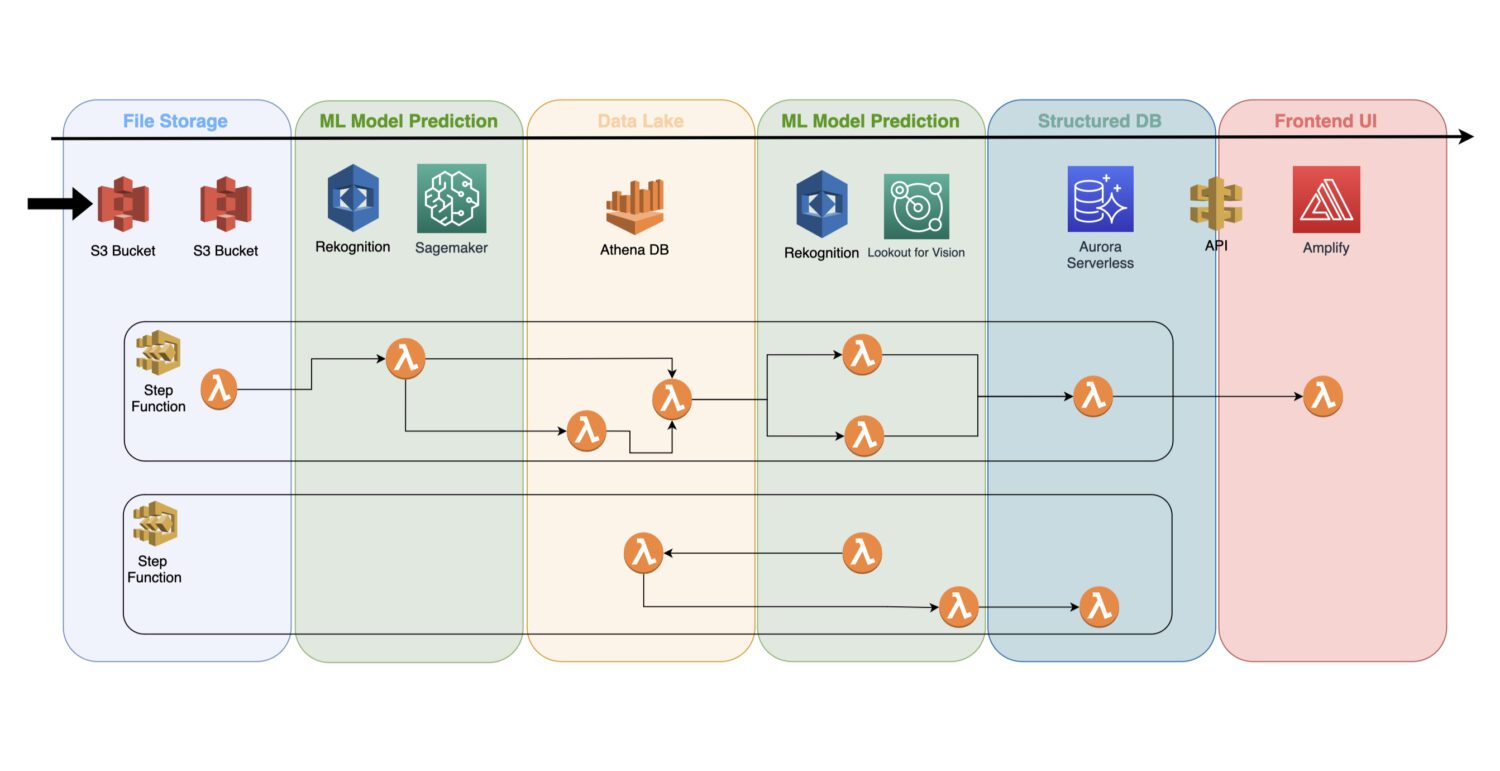
經過訓練的機器學習模型是一種雲服務,它不需要在後台使用任何叢集伺服器;因此,它可以很容易地整合到現有的無伺服器架構中。
自動化是透過 AWS lambda 函數完成的,該函數會連結到 AWS Step Functions 服務中的多個步驟任務。
通常,您需要在收集圖片並在 S3 儲存貯體上對其進行預處理後,執行初始檢測。這就是您將在輸入圖片上產生原子異常檢測並將結果儲存到數據湖的地方,例如由 Athena 資料庫表示。
在某些情況下,這種初始檢測可能不足以滿足您的特定應用情境。您可能需要進行另一個更詳細的檢測。例如,初始模型(例如,Rekognition)可以檢測到設備上的某些問題,但無法可靠地識別問題的類型。
為此,您可能需要另一個具有不同功能的模型。在這種情況下,您可以在初始模型識別出問題的圖像子集上執行另一個模型(例如,Lookout for Vision)。
這也是節省成本的好方法,因為您不需要在整套圖像上執行第二個模型。相反地,您只需要在有意義的子集上執行即可。
AWS Lambda 函數將涵蓋所有使用內部 Python 或 Javascript 程式碼的處理。這完全取決於流程的性質以及您需要在流程中包含多少個 AWS lambda 函數。AWS lambda 呼叫最長持續時間 15 分鐘的限制將決定此類過程需要包含多少步驟。
結語
使用雲端機器學習模型是一項非常有趣的工作。如果您從技能和技術的角度來看,會發現您需要一個擁有多種技能的團隊。
團隊需要了解如何訓練模型,無論是預先建置的還是從頭開始建立的。這意味著需要大量的數學或代數知識,來平衡結果的可靠性和效能。
您還需要具備一些進階的 Python 或 Javascript 編碼技能、資料庫和 SQL 技能。完成所有內容工作後,您需要 DevOps 技能將其插入管道,使其成為準備部署和執行的自動化任務。
定義異常和訓練模型是一回事。但將所有這些整合到一個功能團隊中是一個挑戰,該團隊可以處理模型產生的結果,並以有效和自動化的方式儲存數據,以便為最終使用者提供服務。
接下來,您可以查看有關企業面部辨識的相關資訊。