图数据库擅长存储复杂且高度关联的数据,并能高效处理查询。 然而,你是否了解何时应该选择哪种图数据库? 继续阅读以获取更多信息。
“数据是新的石油”这一说法表明,任何组织的发展都依赖于其有效存储和利用数据的能力。 每天,全球产生的数据量高达2.5万亿字节。 因此,我们需要具备容错能力的数据仓库系统来有效存储和管理这些数据。 最初,关系数据库曾是主要选择。
然而,随着时间的推移,数据的数量和类型迅速变化。 存储视频、音频和图像等非结构化数据的需求应运而生。 这直接促成了SQL、NoSQL数据库、Hadoop以及图数据库等技术的发展。 每种技术都有其特定的应用场景,并处理不同的数据格式。 图数据库的开发旨在简化数据操作并提高存储效率。
图数据库
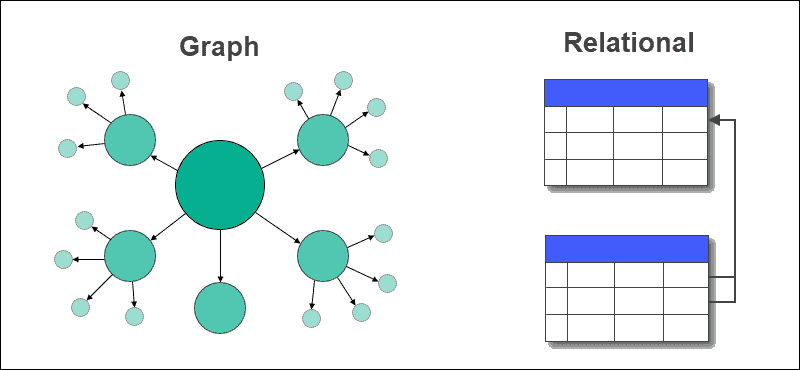
图是一种以节点和边的形式呈现的数据结构。 数据库则是存储数据以及数据之间关系的表的集合。 图数据库是将数据存储在节点中,并通过边来表示数据之间关系的数据库。 它可以高效地处理实时查询,并有效管理实体之间的多对多关系。
流行的图数据模型包括属性图和RDF图。 属性图主要用于数据分析和查询,而RDF图则主要用于数据集成。 两者的区别在于,RDF图以三元组的形式表示数据,即主语、谓语和宾语。
图数据库将数据存储在节点中,而数据之间的关系则以节点之间的边的形式存储。 图中的边可以是定向的(单向),也可以是非定向的(双向)。
查询处理通过遍历图来实现。 图遍历算法可以帮助找到从一个节点到另一个节点的路径、节点之间的距离、识别模式、检测环路以及发现集群的可能性。 这使得图数据库能够高效地响应各种查询。
图数据库的应用
图数据库广泛应用于欺诈检测。 节点(实体)可以是人名、地址、出生日期等信息,也可以是与欺诈行为相关的IP地址或设备号等。 当一个欺诈节点与一个非欺诈节点发生交互时,它们之间会形成连接,并被标记为可疑。
社交媒体平台利用图数据库来推荐用户可能感兴趣的人或内容。 这些推荐是通过对数据库中的图进行遍历来实现的。
网络映射、基础设施管理以及配置项等领域也使用图数据库进行高效的数据存储和管理。
图数据库与关系数据库
在图数据库中,传统的行和列的表被节点和边所取代。 数据之间的关系直接存储在图数据库的边上。
关系数据库则使用外键来表示表与其他表之间的关系。 在关系数据库中,提取数据或执行查询可能很复杂,需要进行复杂的连接。 而图数据库则相对简单。
关系数据库更适用于涉及事务的场景,而图数据库则更适合于关系密集型和数据密集型应用。
图数据库可以支持结构化、半结构化和非结构化数据,而关系数据库则需要预定义的模式。
图数据库可以灵活地应对动态需求,而关系数据库通常用于已知和静态的问题。
 图与关系数据库
图与关系数据库
接下来,我们将探讨一些优秀的图数据库解决方案。
凯莱(Cayley)
Cayley 是一款基于 Apache 2.0 许可的开源图数据库,采用 Go 语言构建,专注于处理链接数据。 Cayley 曾被用于构建谷歌的 Freebase 和知识图谱。 它支持多种查询语言,如 MQL 和 Javascript,并通过基于 Gremlin 的图对象进行查询。
Cayley 易于使用、速度快,并且采用模块化设计。 它可以与各种后端存储(如 LevelDB、MongoDB 和 Bolt)集成和交互。 此外,它还支持多种第三方 API,可以使用 Java、.NET、Rust、Haskell、Ruby、PHP、Javascript 和 Clojure 等多种语言编写。 Cayley 可以部署在 Docker 和 Kubernetes 中。 其主要应用领域包括信息技术、计算机软件和金融服务。
亚马逊海王星(Amazon Neptune)
Amazon Neptune 以其在高度连接的数据集上的出色表现而闻名。 它是一款可靠、安全、完全托管的图数据库服务,支持开放图API。 它可以以极低的毫秒级延迟存储和查询数十亿的关系数据。
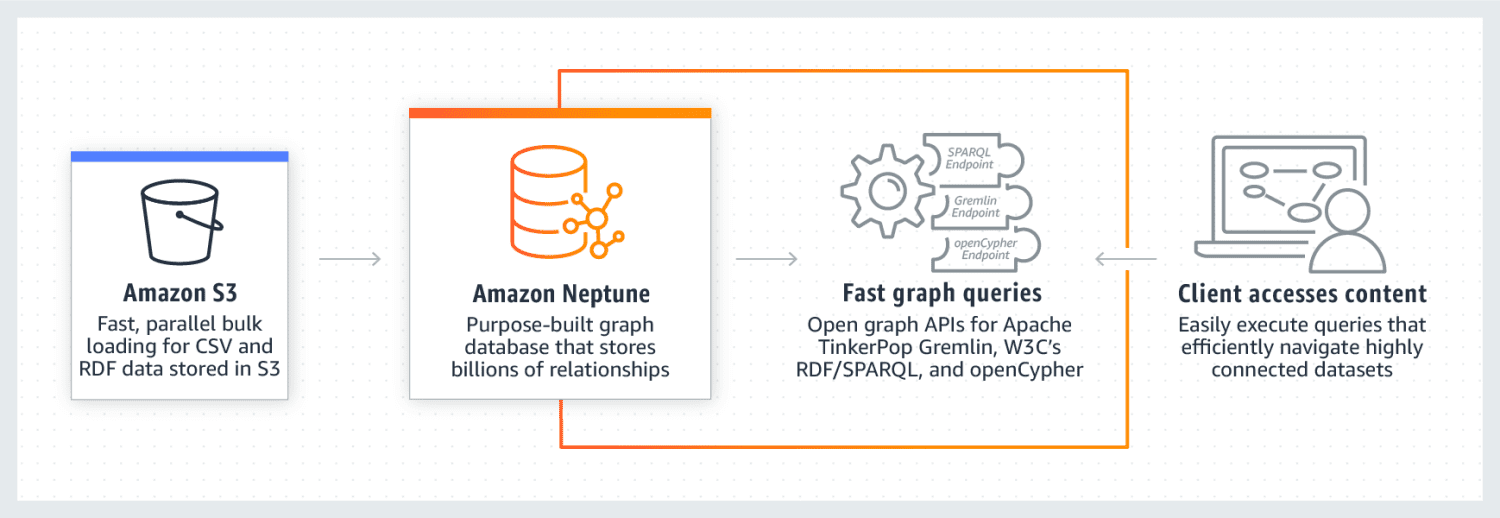
Neptune 的图数据模型由四个位置组成:主语(S)、谓语(P)、宾语(O)和图(G)。 这些位置分别用于存储源节点、目标节点的位置,它们之间的关系以及它们的属性。
为了加速读取查询的执行,Neptune 还使用了缓存机制。 数据以数据库集群的形式存储。 每个集群包含一个主数据库实例和数据库实例的只读副本。 Neptune 提供了强大的安全性,采用了IAM身份验证、SSL认证和日志监控等措施。 从其他来源迁移数据到Amazon Neptune也非常容易。 它还通过创建副本和定期备份来确保高弹性。 一些使用Neptune的公司包括 Herren、Onedot、Juncture 和 Hi Platform。
Neo4j
Neo4j 是一款可扩展、安全、按需且可靠的图数据库。 它使用 Java 构建,并使用 Cypher 作为其查询语言。 它使用 Bolt 协议,所有事务都通过 HTTP 端点进行。 与其他关系数据库相比,Neo4j 在响应查询方面速度更快。 它避免了复杂连接的开销,并且当数据集庞大且高度连接时,其优化效果更佳。 Neo4j 既提供了图存储的优势,又保留了关系数据库的 ACID 属性。

Neo4j 通过驱动程序支持多种语言,如 Java、.NET、Node.js、Ruby 和 Python 等。 它还被广泛用于图数据科学、分析和机器学习工作流中。 Neo4j Aura DB 是一款容错且完全托管的云图数据库。 微软、思科、Adobe、eBay、IBM 和三星等公司都在使用 Neo4j。
ArangoDB
ArangoDB 是一款开源的多模型数据库。 这种多模型方法允许用户使用他们选择的任何查询语言来查询数据。 ArangoDB 的节点和边都是 JSON 文档。 每个文档都有一个唯一的 ID。 两个节点之间的关系以边的形式表示,并存储了它们的唯一 ID。 其良好的性能得益于哈希索引的应用。

数据库中的遍历、连接和搜索功能得到了增强。 ArangoDB 有助于设计、扩展和适应各种架构。 它在特征提取和高级搜索等复杂的数据科学任务中发挥着重要作用。
ArangoDB 可以在基于云的环境中运行,并且与 Mac OS、Linux 和 Windows 兼容。 LDAP 身份验证、数据屏蔽和加密算法确保了数据库的安全性。 它被广泛应用于风险管理、身份与访问管理 (IAM)、欺诈检测、网络基础设施和推荐引擎等领域。埃森哲、思科、Dish 和 VMware 是一些使用 ArangoDB 的组织。
DataStax
DataStax 是基于 Apache Cassandra 构建的 NoSQL 云数据库即服务。 它具有高度的可扩展性,并采用云原生架构。 它可靠且安全。 存储在 DataStax 中的每个文档都有一个索引,有助于轻松搜索和快速检索数据。 分片在索引数据上创建。 使用 Datastax Enterprise 工具、Kafka 和 Docker 可以构建各种数据源的应用程序。
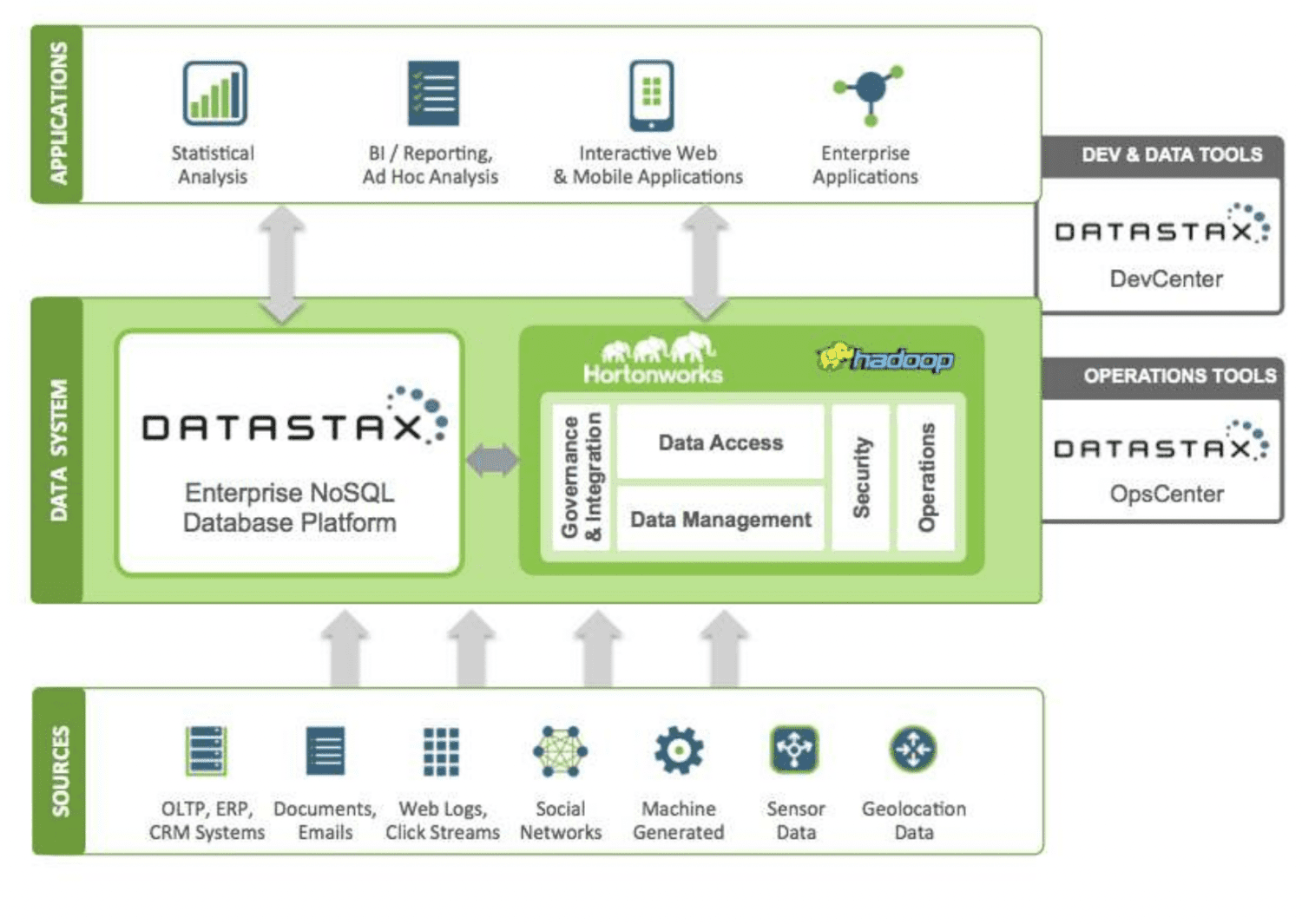
从各种数据源收集的数据被发送到 Hadoop 生态系统和 DataStax。 Hadoop 通过与 DataStax 交互来管理安全、操作、数据访问和管理。 数据通过 DataStax 的开发和运营工具进行细化。
然后将分析得到的信息用于统计分析、企业应用程序和报告等。由于它是基于云的,因此客户只需为其使用的资源付费,定价也相对合理。 Verizon、Capital One、T-Mobile 和 Overstock 等公司都在使用 DataStax。
东方数据库(OrientDB)
OrientDB 是一款图数据库,可以高效地管理数据,并帮助创建用于展示数据的可视化表示。 它是一款基于 Java 构建的多模型图数据库。 它以键值对、文档和对象模型等多种形式存储数据。 OrientDB 由三个重要组件组成:图形编辑器、工作室查询和命令行控制台。
图形编辑器用于可视化数据并与之交互。 工作室查询界面用于执行查询,并以图形和表格两种格式即时提供输出。 命令行控制台则用于从 OrientDB 查询数据。 OrientDB 具有分布式架构,允许多个服务器执行读写操作。 副本服务器则用于执行读取和查询操作。 它支持索引,并符合 ACID 原则。 Comcast Corporation 和 Blackfriars Group 是一些使用 OrientDB 的公司。
Dgraph
Dgraph 是一款支持 GraphQL 的云图数据库,使用 Go 语言构建。 它通过最大化并发查询处理来最小化网络调用,从而减少延迟。 Dgraph 与 GraphQL 的无缝集成有助于轻松开发 GraphQL 后端应用程序。

GraphQL 突变通过 Lambda 函数传递,Lambda 函数可以与数据库和数据管道进行交互。 这简化了查询处理过程。 Dgraph 具有水平可扩展性,这意味着资源的数量会随着查询和数据的增加而增加。 它提供了各种功能,例如基于 JWT 的授权、数据可视化、云身份验证和数据备份等。Intuit、Intel 和 Factset 等组织都在使用 Dgraph。
TigerGraph
TigerGraph 是一款使用 C++ 开发的属性图数据库。 它具有高度的可扩展性,并可以对高度连接的数据执行高级分析。 它使用原生图结构来存储数据,并使用图处理引擎来处理数据。 数据库数据存储在磁盘和内存中,同时还利用 CPU 缓存进行快速检索。 它使用 MapReduce 功能进行并行数据处理。
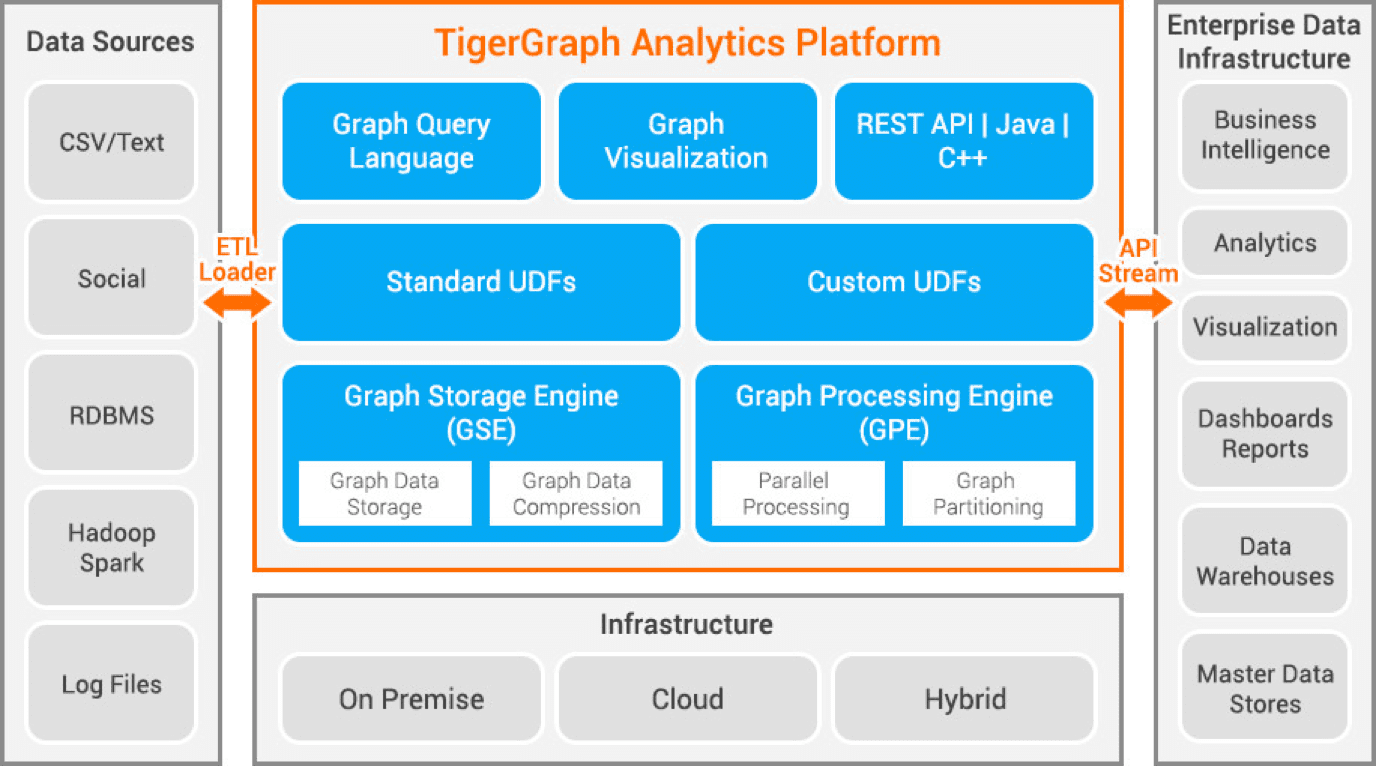
TigerGraph 非常快速且可扩展。 它支持并行计算并提供实时更新。 它使用数据压缩技术,可以将数据压缩 10 倍。 它会自动跨服务器对数据进行分区,从而节省用户手动分片数据所需的时间和精力。 TigerGraph 被广泛应用于家庭欺诈检测、供应链管理和改善医疗保健等领域。 JPMorgan Chase、Intuit 和 United Health Group 是一些使用 TigerGraph 的组织。
AllegroGraph
AllegroGraph 使用实体事件知识图谱技术对高度连接、复杂和密集的数据执行分析和决策。 数据以 JSON 和 JSON-LD 格式存储在图的节点中。 它采用 REST 协议架构。 此外,它还可以通过根据特定标准对数据进行分片并将其分布在多个知识库存储库中来处理超大型数据集。
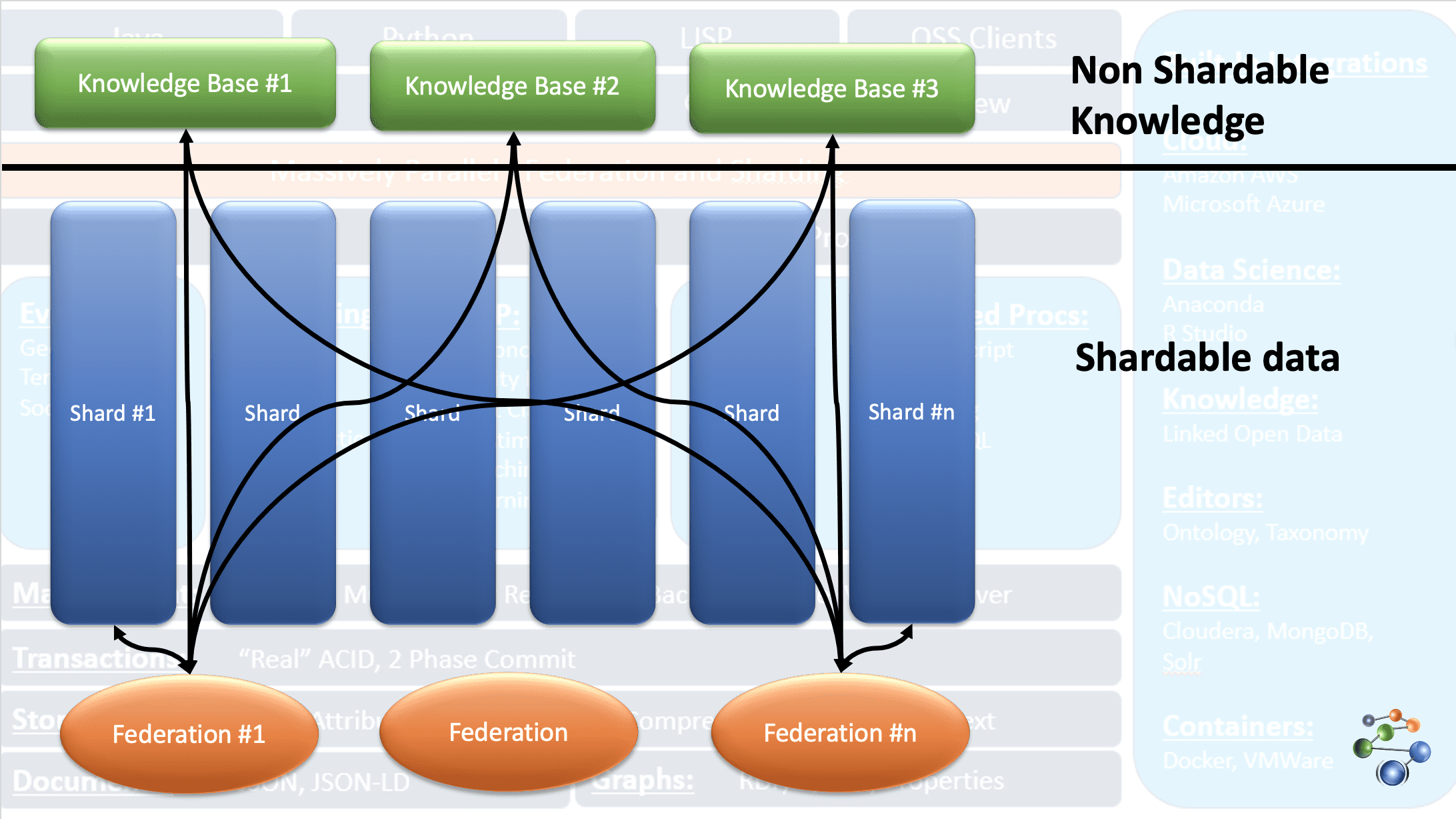
这得益于 AllegroGraph 数据库的 FedShard 功能。 通过将联合与知识库存储库相结合,可以执行查询。 它支持 XML 模式类型并使用三重索引。 AllegroGraph 还可以存储诸如纬度和经度之类的地理空间数据,以及日期和时间戳等时间数据。 它还与 Windows、Mac 和 Linux 兼容。 AllegroGraph 被广泛用于欺诈检测、医疗保健、实体识别和风险预测等领域。
Stardog
Stardog 是一款图数据库,可以执行图数据虚拟化,并链接来自数据仓库和数据湖的数据,而无需将数据物理复制到新的存储位置。 Stardog 基于 RDF 开放标准构建。 它支持结构化、半结构化和非结构化数据。 Stardog 的这种数据物化提供了极大的灵活性。 它是唯一结合了知识图谱和虚拟化的图数据库。
Stardog 使用 AI 驱动的推理引擎来高效地处理和提供查询结果。 它是一款符合 ACID 原则的图数据库,支持并发读写。 凭借其“最先进”的架构,它可以轻松处理复杂的查询。 Stardog 被广泛用于 IT 资产管理、数据管理和分析,并提供高可用性。 思科、eBay、NASA 和 Finra 等公司都在使用 Stardog。
结语
图数据库有助于轻松查询多对多关系并高效存储数据。 它们具有可扩展性、安全性,并且可以与多种第三方工具、API 和语言集成。 近年来,它们已经与云集成,并提供了最佳性能。
图数据库将复杂的连接简化为简单的查询,这使得开发人员更容易完成任务。 物联网和大数据等数据密集型任务非常适合使用图数据库。 这些技术将持续发展,并在未来扩展到更多的应用场景。