根据《福布斯》的统计,全球约有 90% 的企业机构采用大数据分析技术来编制投资报告。
随着大数据应用的日益广泛,Hadoop 相关的工作机会也随之大幅增加。
为了帮助您成功应聘 Hadoop 专家职位,我们精心整理了本文中的面试题及答案,希望能助您顺利通过面试。
了解 Hadoop 和大数据领域的高薪待遇或许能激励您更加努力地准备面试,您觉得呢?🤔
- 根据 indeed.com 的数据显示,美国大数据 Hadoop 开发人员的平均年薪约为 14.4 万美元。
- 根据 itjobswatch.co.uk 的统计,英国大数据 Hadoop 开发人员的平均年薪约为 6.675 万英镑。
- 在印度,根据 indeed.com 的数据,他们的平均年薪约为 160 万卢比。
薪资待遇相当可观,不是吗? 接下来,让我们深入了解 Hadoop 的相关知识。
什么是 Hadoop?
Hadoop 是一个流行的 Java 编写的框架,它利用编程模型来处理、存储和分析海量数据集。
Hadoop 的设计允许其从单个服务器扩展到多台机器,从而提供本地计算和存储能力。此外,它具备检测和处理应用层故障的能力,确保了服务的高可用性,这使得 Hadoop 非常可靠。
接下来,我们将直接进入常见的 Hadoop 面试问题以及对应的解答。
Hadoop 的面试题及答案
Hadoop 中的存储单元是什么?
答:Hadoop 的存储单元被称为 Hadoop 分布式文件系统 (HDFS)。
网络附加存储 (NAS) 与 Hadoop 分布式文件系统 (HDFS) 有何区别?
答:HDFS 是 Hadoop 的核心存储系统,它是一种分布式文件系统,利用通用硬件来存储海量文件。而 NAS 是一种文件级计算机数据存储服务器,主要为异构客户端群组提供数据访问服务。
NAS 的数据存储在专用硬件上,而 HDFS 将数据块分散存储在 Hadoop 集群中的所有机器上。
NAS 通常采用高端存储设备,成本较高,而 HDFS 则采用经济高效的通用硬件。
NAS 将数据存储与计算分离开来,因此不适合 MapReduce。相反,HDFS 的设计使其能够与 MapReduce 框架协同工作。 在 MapReduce 框架中,计算会移动到数据所在的位置,而不是将数据移动到计算端。
解释 Hadoop 中的 MapReduce 和 Shuffling
答:MapReduce 指的是 Hadoop 程序执行的两个不同任务,它实现了在 Hadoop 集群中成百上千台服务器上的大规模可扩展性。另一方面,Shuffling 将 Mapper 的输出结果传输给 MapReduce 中必要的 Reducer。
简述 Apache Pig 架构
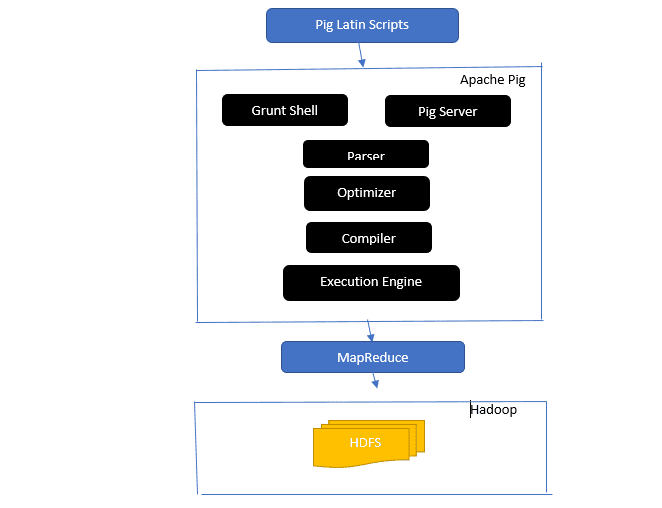
答:Apache Pig 架构包含一个 Pig Latin 解释器,该解释器使用 Pig Latin 脚本处理和分析大型数据集。
Apache Pig 还包含一组数据集,这些数据集用于执行诸如连接、加载、过滤、排序和分组等数据操作。
Pig Latin 语言使用 Grant shell、UDF 和嵌入式等执行机制来编写执行所需任务的 Pig 脚本。
Pig 通过将这些编写的脚本转换为 Map-Reduce 作业序列,简化了程序员的工作。
Apache Pig 架构组件包括:
- 解析器 (Parser) – 它通过检查脚本的语法和执行类型检查来处理 Pig 脚本。解析器的输出是一个被称为 DAG (有向无环图) 的 Pig Latin 语句和逻辑运算符的表示形式。
- 优化器 (Optimizer) – 优化器在 DAG 上执行逻辑优化,例如投影和下推。
- 编译器 (Compiler) – 将优化器优化后的逻辑计划编译成一系列 MapReduce 作业。
- 执行引擎 (Execution Engine) – 这是最终将 MapReduce 作业执行并输出所需结果的地方。
- 执行模式 (Execution Mode) – Apache Pig 中的执行模式主要有两种:本地模式和 MapReduce 模式。
答:本地元存储 (Local Metastore) 中的元存储服务与 Hive 在同一个 JVM 中运行,但连接到同一台计算机或远程计算机上单独进程中运行的数据库。另一方面,远程元存储 (Remote Metastore) 中的元存储服务运行在其独立的 JVM 中,与 Hive 服务 JVM 分开运行。
大数据的五个 V 是什么?
答:这五个 V 代表大数据的主要特征。 它们包括:
- 价值 (Value):大数据旨在通过高投资回报率 (ROI) 为在其数据运营中使用大数据的组织带来显著收益。大数据通过其洞察力发现和模式识别来实现这种价值,从而带来更牢固的客户关系和更有效的运营等好处。
- 多样性 (Variety):这表示所收集的数据类型的异构性。 各种格式包括 CSV、视频、音频等。
- 量 (Volume):这定义了组织管理和分析的数据的重要数量和大小。 此数据呈指数级增长。
- 速度 (Velocity):这是数据增长的指数速度。
- 真实性 (Veracity):真实性是指由于数据不完整或不一致而导致可用数据“不确定”或“不准确”的程度。
解释 Pig Latin 的不同数据类型。
答:Pig Latin 中的数据类型包括原子数据类型和复杂数据类型。
原子数据类型是所有其他语言中使用的基本数据类型。 它们包括:
- Int – 这种数据类型定义一个有符号的 32 位整数。 示例:13
- Long – Long 定义一个 64 位整数。 示例:10L
- Float – 定义一个有符号的 32 位浮点数。 示例:2.5F
- Double – 定义一个有符号的 64 位浮点数。 示例:23.4
- Boolean – 定义一个布尔值。 它包括:true/false
- Datetime – 定义一个日期时间值。 示例:1980-01-01T00:00.00.000+00:00
复杂数据类型包括:
- Map – Map 指的是键值对的集合。 示例:[‘color’#’yellow’, ‘number’#3]
- Bag – 它是一个元组集合,它使用“{}”符号。 示例:{(亨利,32 岁),(基蒂,47 岁)}
- Tuple – 元组定义一组有序的字段。 示例:(年龄,33 岁)
什么是 Apache Oozie 和 Apache ZooKeeper?
答:Apache Oozie 是一个 Hadoop 作业调度器,负责将 Hadoop 作业调度并绑定为一个单独的逻辑工作单元。
另一方面,Apache ZooKeeper 在分布式环境中协调各种服务。 它通过简单地公开诸如同步、分组、配置维护和命名等简单服务来节省开发人员的时间。Apache ZooKeeper 还为队列和领导选举提供即时支持。
Combiner、RecordReader 和 Partitioner 在 MapReduce 操作中的作用是什么?
答:Combiner 类似于一个迷你 Reducer。 它接收并处理来自 Map 任务的数据,然后将数据的输出传递给 Reducer 阶段。
RecordReader 与 InputSplit 通信,并将数据转换为键值对,以供 Mapper 正确读取。
Partitioner 负责决定汇总数据所需的 Reducer 任务数量,并确认 Combiner 的输出如何发送到 Reducer。 Partitioner 还控制中间 Map 输出的关键分区。
提及不同供应商特定的 Hadoop 发行版。
答:扩展 Hadoop 功能的各种供应商包括:
- IBM Open Platform.
- Cloudera CDH Hadoop 发行版
- MapR Hadoop 分布
- Amazon Elastic MapReduce
- Hortonworks Data Platform (HDP)
- Pivotal Big Data Suite
- DataStax Enterprise Analytics
- Microsoft Azure 的 HDInsight – 基于云的 Hadoop 发行版。
为什么 HDFS 具有容错性?
答:HDFS 通过将数据复制到不同的 DataNode 上来实现容错。 将数据存储在不同的节点中,允许在某个节点崩溃时从其他节点检索数据。
区分 Federation 和高可用性。
答:HDFS Federation 提供容错能力,允许在某个节点崩溃时在一个节点中连续传输数据。 另一方面,高可用性需要两台独立的机器,分别在第一台和第二台机器上配置活动 NameNode 和备用 NameNode。
Federation 可以拥有无限数量的不相关的 NameNode,而在高可用性中,只有两个相关的 NameNode,一个活跃和一个备用,它们持续运行。
Federation 中的 NameNode 共享一个元数据池,每个 NameNode 都有自己的专用池。 然而,在高可用性中,活跃 NameNode 一次运行一个,而备用 NameNode 保持空闲状态,只是偶尔更新其元数据。
如何查找块状态和文件系统健康状况?
答:您可以使用 hdfs fsck / 命令在根用户级别和单个目录下检查 HDFS 文件系统的健康状态。
使用中的 HDFS fsck 命令:
hdfs fsck / -files --blocks –locations > dfs-fsck.log命令说明:
-files:打印正在检查的文件。–locations:检查时打印所有块的位置。
检查块状态的命令:
hdfs fsck <path> -files -blocks<path>:从此处传递的路径开始检查。– blocks:它在检查期间打印文件块。
什么时候使用 rmadmin-refreshNodes 和 dfsadmin-refreshNodes 命令?
答:这两个命令有助于在调试过程中或节点调试完成后刷新节点信息。
dfsadmin-refreshNodes 命令运行 HDFS 客户端并刷新 NameNode 的节点配置。 另一方面,rmadmin-refreshNodes 命令执行 ResourceManager 的管理任务。
什么是检查点 (Checkpoint)?
答:检查点是将文件系统的最后更改与最近的 FSImage 合并的操作,以便编辑日志文件保持足够小,以加快启动 NameNode 的过程。 检查点发生在 Secondary NameNode 中。
为什么我们将 HDFS 用于具有大数据集的应用程序?
答:HDFS 提供了 DataNode 和 NameNode 架构,实现了分布式文件系统。
这两种架构通过高度可扩展的 Hadoop 集群提供对数据的高性能访问。 它的 NameNode 将文件系统的元数据存储在 RAM 中,这导致内存量限制了 HDFS 文件系统文件的数量。
“jps” 命令有什么作用?
答:Java 虚拟机进程状态 (JPS) 命令检查特定的 Hadoop 守护进程是否正在运行,包括 NodeManager、DataNode、NameNode 和 ResourceManager。需要从 root 运行该命令才能查看主机中正在运行的节点。
Hadoop 中的“推测执行”是什么?
答:这是一个过程,在 Hadoop 中,主节点不是修复检测到的慢速任务,而是在另一个节点上启动同一任务的不同实例作为备份任务(推测任务)。 推测执行可以节省大量时间,尤其是在密集的工作负载环境中。
说出 Hadoop 可以运行的三种模式。
答:Hadoop 运行的三种主要节点包括:
- 独立节点是使用本地文件系统和单个 Java 进程运行 Hadoop 服务的默认模式。
- 伪分布式节点使用单节点 Hadoop 部署执行所有 Hadoop 服务。
- 全分布式节点使用单独的节点运行 Hadoop 主从服务。
什么是 UDF?
答:UDF(用户定义函数)允许您编写自定义函数,可以使用这些函数在 Impala 查询期间处理列值。
什么是 DistCp?
答:简而言之,DistCp 或分布式复制 (Distributed Copy) 是用于大型集群间或集群内数据复制的有效工具。 DistCp 利用 MapReduce 有效实现大量数据的分布式副本,并提供其他功能,例如错误处理、恢复和报告。
答:Hive 元存储是一项服务,用于将 Hive 表的 Apache Hive 元数据存储在诸如 MySQL 等关系数据库中。 它提供了允许对元数据进行分权访问的元存储服务 API。
定义 RDD。
答:RDD(弹性分布式数据集)是 Spark 的数据结构,是跨不同集群节点计算的数据元素的不可变分布式集合。
如何将原生库包含在 YARN 作业中?
答:您可以使用 -Djava.library.path 命令上的路径选项来实现,或者通过使用以下格式在 .bashrc 文件中设置 LD_LIBRARY_PATH:
<property>
<name>mapreduce.map.env</name>
<value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value>
</property>
解释 HBase 中的“WAL”。
答:预写日志 (Write Ahead Log, WAL) 是一种恢复协议,它将 HBase 中 MemStore 的数据变化记录到基于文件的存储中。 如果 RegionalServer 崩溃或在刷新 MemStore 之前,WAL 会恢复此数据。
YARN 是 Hadoop MapReduce 的替代品吗?
答:不,YARN 不是 Hadoop MapReduce 的替代品。 相反,YARN 为 MapReduce 提供了一种强大的底层支持,即所谓的 Hadoop 2.0 或 MapReduce 2。
HIVE 中的 ORDER BY 和 SORT BY 有什么区别?
答:尽管这两个命令都用于在 Hive 中以排序方式获取数据,但使用 SORT BY 的结果可能只是部分排序。
此外,SORT BY 需要一个 Reducer 对行进行排序。 最终输出所需的 Reducer 数量也可能是多个。 在这种情况下,最终输出可能是部分排序的。
另一方面,ORDER BY 只需要一个 Reducer 来输出总排序。 您还可以使用 LIMIT 关键字来缩短总排序时间。
Spark 和 Hadoop 有什么区别?
答:虽然 Hadoop 和 Spark 都是分布式处理框架,但它们的主要区别在于其处理方式。 Hadoop 对于批处理非常高效,而 Spark 对于实时数据处理非常高效。
此外,Hadoop 主要将文件读写到 HDFS,而 Spark 则使用弹性分布式数据集 (Resilient Distributed Dataset) 的概念在 RAM 中处理数据。
从延迟角度来看,Hadoop 是一个高延迟的计算框架,没有交互式处理数据的方式,而 Spark 则是一个低延迟的计算框架,可以以交互方式处理数据。
比较 Sqoop 和 Flume。
答:Sqoop 和 Flume 都是 Hadoop 工具,用于从各种源收集数据,并将其加载到 HDFS 中。
- Sqoop (SQL-to-Hadoop) 从 Teradata、MySQL、Oracle 等数据库中提取结构化数据,而 Flume 用于从数据库源中提取非结构化数据并将其加载到 HDFS。
- 在事件驱动方面,Flume 是事件驱动的,而 Sqoop 则不是。
- Sqoop 使用基于连接器的架构,其中连接器知道如何连接到不同的数据源。 Flume 使用基于代理的架构,负责获取数据的代码即是代理。
- 由于 Flume 具有分布式特性,因此可以轻松地收集和聚合数据。 Sqoop 对于并行数据传输非常有用,这会导致输出分布在多个文件中。
解释 BloomMapFile。
答:BloomMapFile 是一个扩展 MapFile 类的类,并使用动态布隆过滤器为键提供快速成员资格测试。
列出 HiveQL 和 PigLatin 之间的区别。
答:HiveQL 是一种类似于 SQL 的声明性语言,而 PigLatin 是一种高级过程式数据流语言。
什么是数据清理?
答:数据清理是一个关键过程,用于消除或修复已识别的数据错误,这些错误包括数据集中不正确、不完整、损坏、重复和格式错误的数据。
此过程旨在提高数据质量,并提供组织内有效决策所需的更准确、一致和可靠的信息。
结语💃
随着当前大数据和 Hadoop 工作机会的激增,您可能希望提高自己成功的机会。本文的 Hadoop 面试问题和答案将有助于您在即将到来的面试中脱颖而出。
接下来,您可以查看学习大数据和 Hadoop 的一些优秀资源。
祝您好运!👍