摆脱传统:拥抱无服务器架构的优势
过去,构建自动化软件系统意味着需要配置多台服务器,每台服务器都有其专属的 CPU、内存、存储和其他资源。 为了管理这些复杂的系统,通常会组建专门的管理员团队。 随后,开发团队会接手基础设施,开始创建连接不同服务器的流程。
这个过程往往错综复杂,需要多个团队为了共同的目标协同工作。 这种多方协作有时会产生利益冲突,增加管理的难度。
而且,这种传统的模式往往成本高昂。 首先,您需要支付管理员的工资。 其次,即使服务器处于闲置状态,也需要持续消耗资源,这无疑是一笔不小的开销。
为了保持长期最佳性能,您需要一个能够自动扩展服务器资源的解决方案。 这就是自动伸缩解决方案发挥作用的地方。
云平台的出现带来了一种全新的选择。 它允许您创建端到端的架构,而无需复杂的服务器集群设置。 从管理的角度来看,几乎无需维护,大大减轻了管理负担。
对于初创公司和处于最小可行产品(MVP)阶段的项目来说,云平台是一个具有成本效益的选择。 如果难以预测未来的生产负载和用户活动,这是一个很好的起点。 尤其是在确定集群服务器配置时,其不确定性可能更具挑战性。
无服务器云服务的出现,使得流程自动化更加便捷,也正是无服务器架构的魅力所在。 它能够连接各种服务,并产生类似于传统集群服务器的效果,但成本更低、维护更少。
以下是一个仅使用 AWS 原生服务构建此类架构的示例,供您参考。
探索无服务器流程
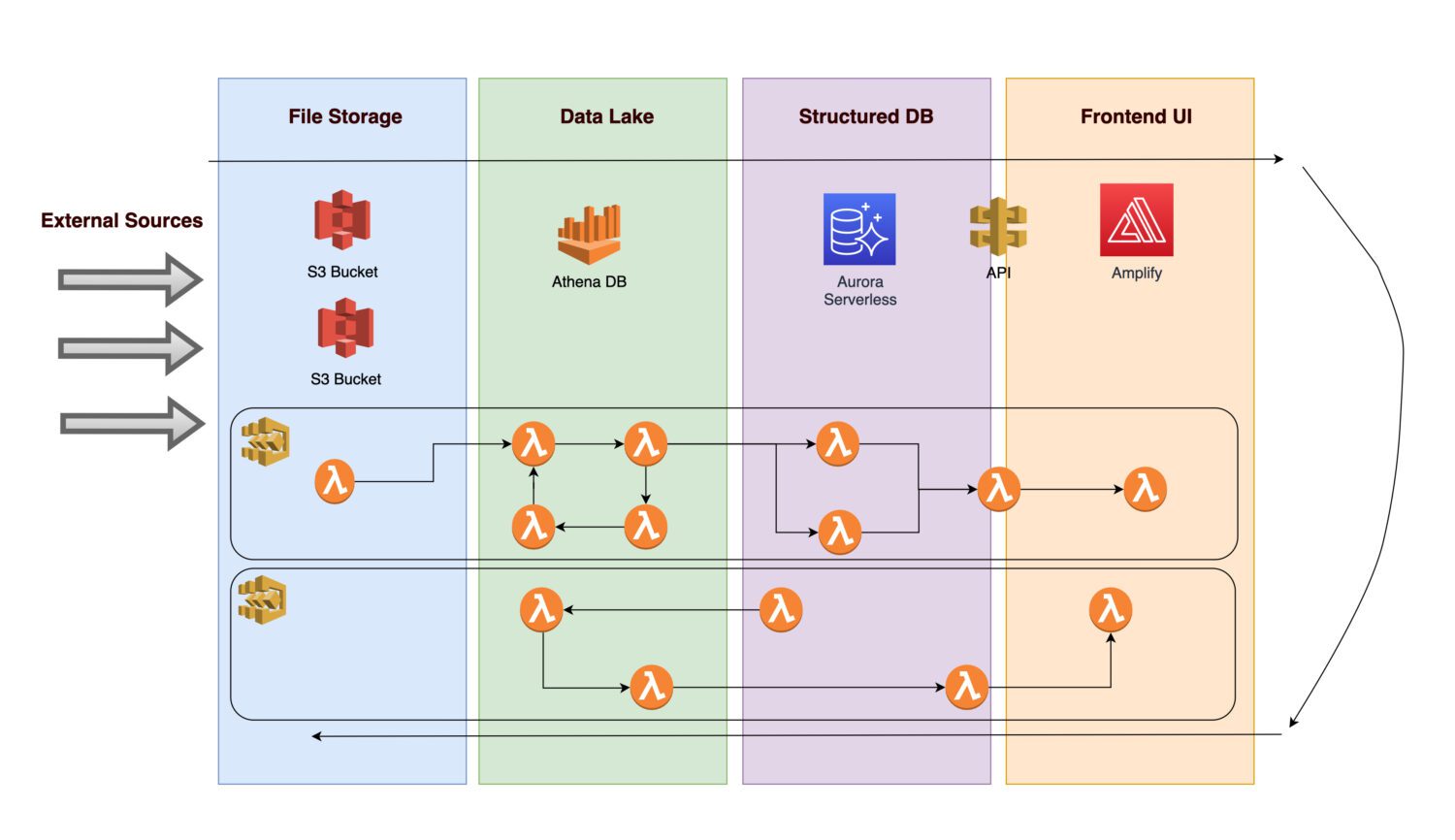
设想一下,您需要创建一个平台来收集各种特定资产(例如,任何制造或公用事业资产)的数据和图片(或照片)。
- 为了便于未来进行分析,首先必须采集传入的数据。
- 在应用业务规则之后,后端程序会将计算结果作为规范化信息存储在关系数据库中。
- 前端应用程序用于展示规范化的清晰数据,让用户可以查看结果。
接下来,让我们分析一下这个架构可能包含哪些组件。
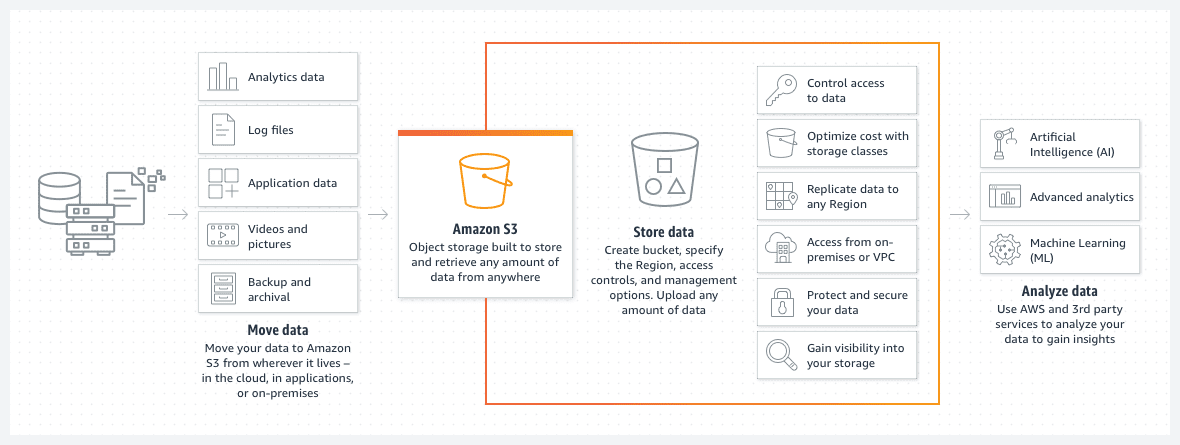
AWS S3 存储桶
 来源:aws.amazon.com
来源:aws.amazon.com
Amazon S3 存储桶是在 AWS 云中存储文件或图片的理想选择。S3 存储桶的存储成本非常低,尤其是在采用 S3 存储桶生命周期策略后,成本会进一步降低。
这种策略能够自动将旧文件移动到不同类别的 S3 存储桶,例如归档或深度归档访问。 这些类别的区别在于访问速度,但对于旧数据,访问速度通常不是主要考虑因素。 它们主要用于在紧急情况下访问存档数据,而不是日常操作所需。
- 您可以将数据组织在子文件夹中。
- 您需要设置适当的权限限制。
- 为存储桶添加标签,以便轻松识别并在动态 S3 存储桶策略中使用。
- 存储桶的设计是无服务器的。它仅仅是您数据的存储空间。
S3 存储桶本身就是无服务器的,它只是您数据的存储区域。
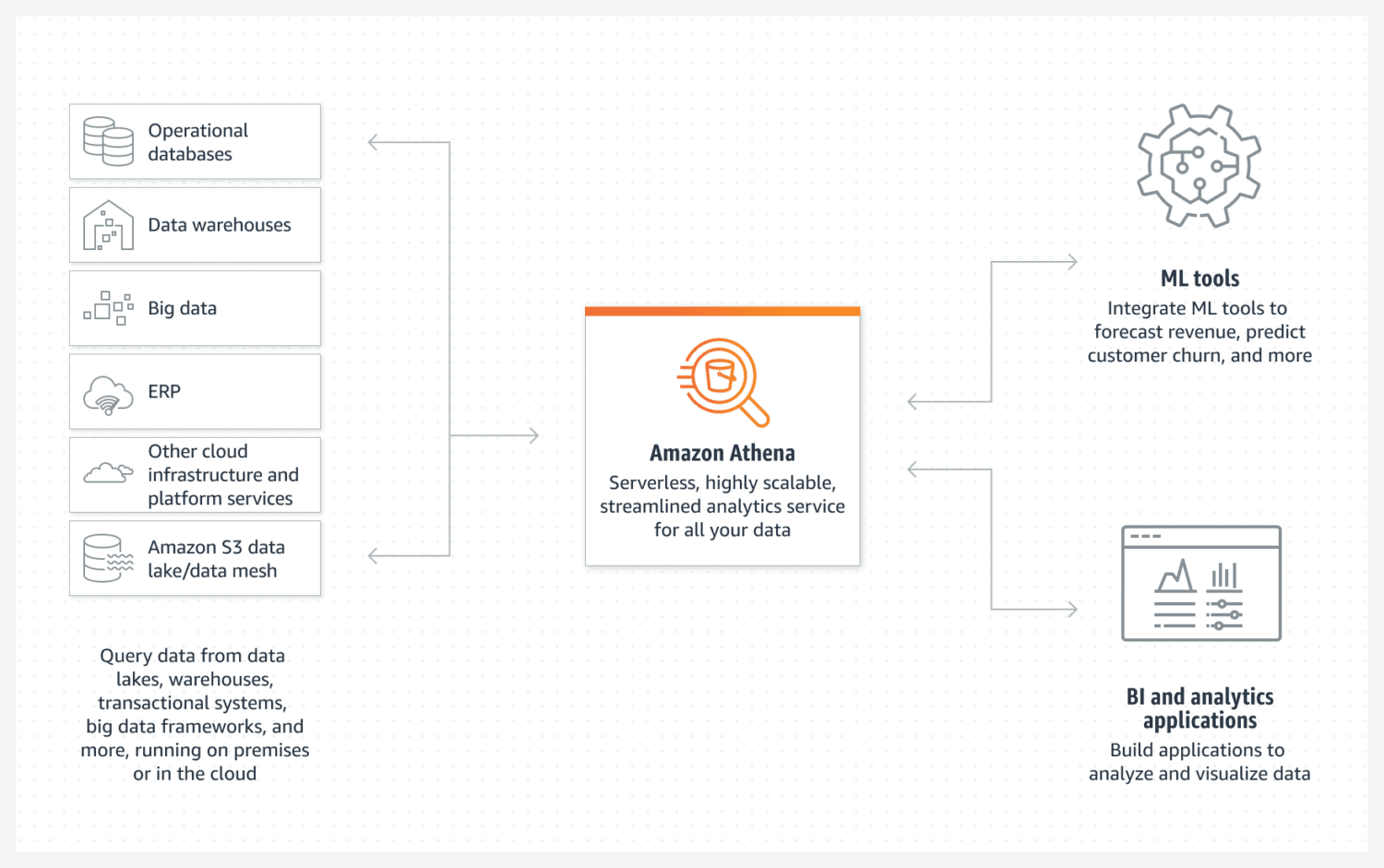
AWS Athena 数据库
 来源:aws.amazon.com
来源:aws.amazon.com
Athena 可以轻松创建 AWS 基本数据湖。它是一个无服务器的数据库,使用 S3 存储桶来存储其数据。 数据组织由结构化文件格式维护,例如 Parquet 或 CSV 文件。S3 存储桶保存文件,每当进程从数据库中查询数据时,Athena 都会引用这些文件。
需要注意的是,Athena 不支持某些被视为标准的功能,例如更新语句。 因此,您需要将 Athena 视为一个相对简单的选择。
但是,它支持索引和分区。 它还能够轻松地进行水平扩展,因为这只需要添加新的存储桶即可实现。对于简单而实用的数据湖创建,这在大多数情况下已经足够。
为了获得理想的性能,选择最佳的数据设计并预先考虑未来的使用至关重要。 您必须清楚地了解您希望如何查询数据。一旦创建表格并填充了大量数据,之后重新创建表格将会非常困难。
如果您希望创建一个简单、不可变且易于水平扩展的数据池,那么 Athena 数据库将是一个不错的选择,可以很好地满足您的需求。
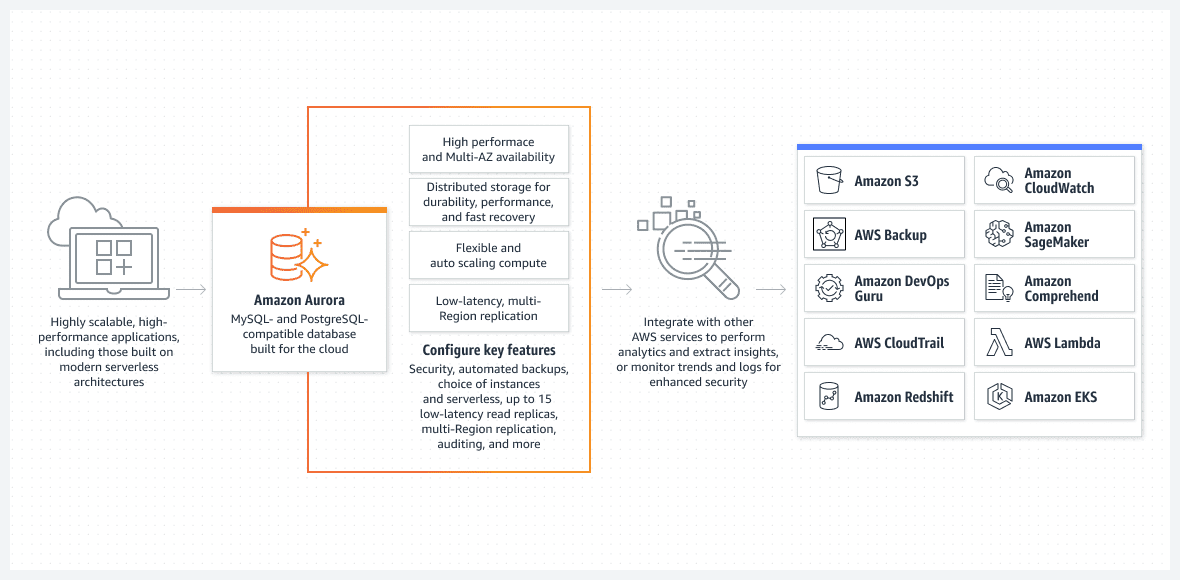
AWS Aurora 数据库
 来源:aws.amazon.com
来源:aws.amazon.com
Athena 数据库擅长存储未经整理的数据。 毕竟,您希望以原始格式存储原始数据,以便最大限度地提高其未来的复用率。但是,将查询结果提供给前端应用程序的速度可能比较慢。
从易于设置的角度来看,最好的选择之一是以无服务器模式运行的 Aurora 数据库。
Aurora 绝不仅仅是一个基本的数据库。 它是 AWS 中最先进的本地关系数据库解决方案之一。它也是一个高度复杂的原生关系数据库解决方案,每个版本都在不断改进。
Aurora 的独特之处在于它可以在无服务器模式下运行,这使其与其他关系型服务区分开来。以下是此模式的工作原理:
- 要配置 Aurora 集群,请使用 AWS 控制台。您需要指定标准的 CPU 和 RAM 水平,以及自动伸缩功能的最大间隔。这将影响 Aurora 集群动态添加或删除资源的性能。AWS 会根据数据库的当前利用率决定是向上还是向下扩展。
- 除非用户或进程发起真正的请求,否则 Aurora 集群不会启动。 例如,计划的批处理开始时,或者应用程序执行后端 API 调用以从数据库中检索数据时。 请求过程完成后,数据库将自动打开并在预定时间内保持活动状态。
- 如果数据库中没有更多工作,Aurora 集群将自动关闭。
再次强调,无服务器 Aurora 数据库仅在必须执行实际工作时才运行。如果没有处理任何工作,自动启动的集群将会再次关闭。您实际支付的费用是用于执行工作,而不是用于空闲时间。
无服务器 Aurora 完全由 AWS 管理,无需管理员。
AWS Amplify
Amplify 提供了一个无服务器平台,用于快速部署使用 JavaScript 和 React 库构建的前端应用程序。 无需设置集群服务器。 您可以使用 AWS 控制台直接部署代码,或使用自动化 DevOps 管道。
您可以调用后端 API 来访问存储在数据库中的数据。 这些调用允许您在前端应用程序中访问实际数据。 后端的主要性能优化应由团队完成。 如果在 API 调用中设计有效的选择语句,您甚至可以进一步降低 UI 中响应缓慢的可能性。
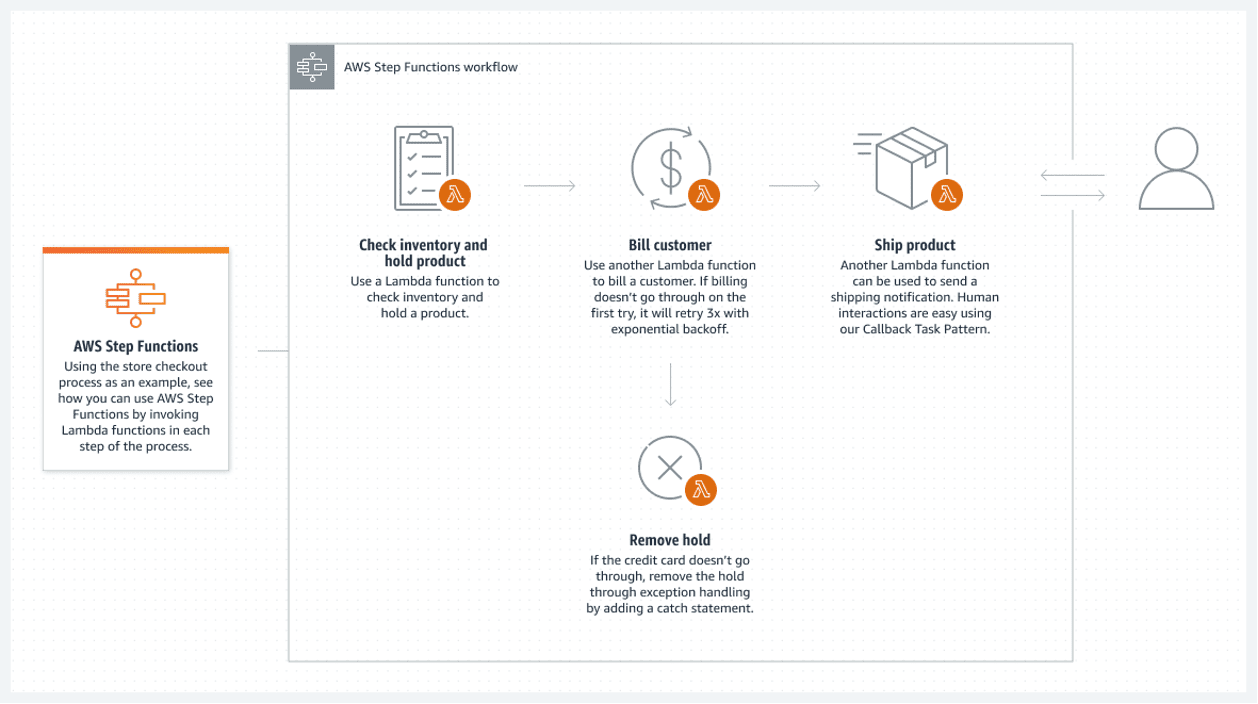
AWS Step Functions
 来源:aws.amazon.com
来源:aws.amazon.com
尽管系统的所有主要组件都是无服务器的,但这并不能保证整个架构完全无服务器。 只有在组件之间的所有批处理也是无服务器的情况下,才能实现这一点。
AWS Step Functions 提供了 AWS 云上的最佳解决方案。 AWS Lambda 函数的连接列表构成了步骤函数。这些函数创建了一个流程图,其中包含了清晰的开始和结束状态。 通常用 Python 或 Node JS 编写的 lambda 函数是一段可执行代码,可以处理所需的任何内容。
以下是如何执行步骤函数的示例:
- 每当新文件进入 S3 文件夹时,AWS 都会触发自动 lambda 函数。 解析文件后,lambda 将其加载到 Athena 中。 lambda 在关闭之前以 CSV 格式将其结果存储在 S3 存储桶(或数据库跟踪表)中。
- 然后,下一个 lambda 使用此结果来执行后续步骤。 这可能包括调用机器学习模型,并将新数据的子集转换为规范化表。 最后一步可以是将数据加载到 Aurora 数据库。
- 步骤函数将这些 lambda 链接在一起,以形成批处理流。 甚至可以执行另一个步进函数来代替另一个根步进函数的一个步骤。 这样,就可以覆盖很多场景。
这种无服务器流程的一个主要缺点是:每个 lambda 函数最多只能运行 15 分钟。 因此,将流程拆分为更小的 lambda 函数可以减少问题。
可以在一个步骤中同时调用多个 lambda 函数,这意味着可以并行执行多个 lambda。在继续之前,只需等待所有并行 lambda 处理完成即可。然后,继续执行下一个 lambda 函数。
总结
无服务器架构为构建覆盖整个系统环境的云平台提供了独特的机会。 该平台具有可扩展性,同时运营成本低。
它是预算有限项目的理想解决方案。 这也是一个非常值得探索的选项,特别是在无法预测实际生产负载的情况下。在您成功让所有用户上线后,这一点尤为重要。项目团队仍然可以全面了解系统的工作原理。您可以获得所有这些好处,而无需做出任何妥协。
这种覆盖范围并非适用于所有情况,特别是涉及高 CPU 使用率的场景。 然而,AWS 云在无服务器应用方面正在不断发展。 在为下一个 AWS 云项目选择无服务器选项之前,进行深入的研究通常是一个明智之举。
接下来,您可以了解适用于现代应用程序的最佳无服务器数据库。