深入解析:机器学习与数据科学中的特征工程
是否渴望掌握机器学习和数据科学的关键技能——特征工程? 那么,您找对地方了!
特征工程是从原始数据中挖掘价值的强大工具。在这篇简明教程中,我们将深入浅出地解析其核心概念,助您开启特征提取的精通之旅!
什么是特征工程?

在构建机器学习模型以解决业务或实验问题时,您需要为模型提供学习数据,这些数据通常以行列的形式存在。 在数据科学和机器学习领域,列被称为属性或变量。
而这些列下的具体数据或行,则被视为观测值或实例。 原始数据集中的列或属性,就是所谓的特征。
然而,这些原始特征往往不足以训练出高效的机器学习模型,也无法达到理想的预测效果。 为了减少原始数据中可能存在的噪声,并最大化特征所蕴含的有效信号,我们需要通过特征工程,将原始数据列进行转换,提取出更具功能性的特征。
示例 1:金融建模
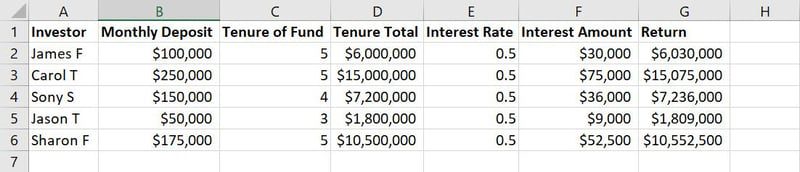
以上面的示例数据图像为例,A 到 G 列都属于特征。 而每一列下的值或文本字符串,如姓名、存款金额、存款年限、利率等,则构成观测值。
在机器学习建模中,为了创建更有意义的特征,并减小模型训练数据库的规模,我们必须对原始数据进行删除、添加、组合或转换。 这便是特征工程的核心所在。
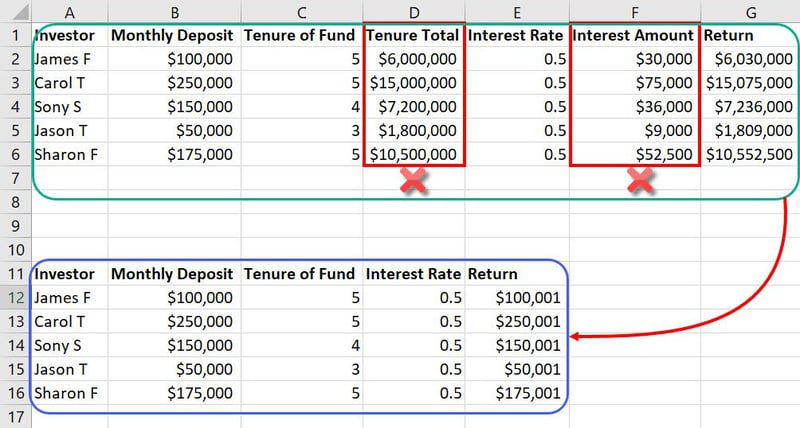
在上述示例数据集中,“总任期”和“利息金额”这两个特征可能并非必要的输入,它们可能会占用额外的空间,并对机器学习模型产生干扰。因此,我们可以将总共七个特征缩减为五个。
考虑到机器学习模型所处理的数据库可能包含数千列和数百万行数据,减少两个特征对项目的整体影响是十分显著的。
示例 2:AI 音乐播放列表生成器
有时,我们可以从多个现有特征中创建全新的特征。 假设您正在开发一个 AI 模型,该模型可以根据活动、偏好、模式等,自动生成音乐和歌曲的播放列表。
您从各个来源收集了歌曲和音乐的数据,并创建了以下数据库:
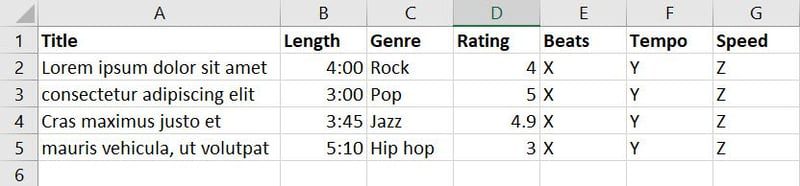
上述数据库中包含七个特征。 然而,考虑到您的目标是训练一个机器学习模型来判断哪首歌曲或音乐适合哪个活动,您可以将“流派”、“评分”、“节拍”、“节奏”和“速度”等特征组合成一个名为“适用性”的新特征。
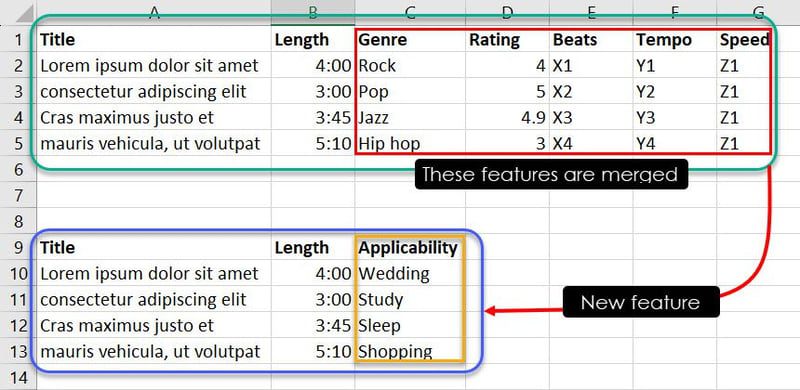
借助专业知识或模式识别,您可以结合某些特征实例来确定哪首歌曲适合哪个活动。 例如,“爵士乐”、“4.9”、“X3”、“Y3”和“Z1”等观测值可以告知机器学习模型,如果用户正在寻找适合睡眠的歌曲,那么“Cras maximus justo et”这首歌应该出现在用户的播放列表中。
机器学习中的特征类型
分类特征
分类特征是指代表不同类别或标签的数据属性,通常用于标记定性数据集。
#1. 序数分类特征
序数特征的类别之间具有明确的顺序关系,例如教育程度(高中、学士、硕士等)。 这些类别在等级上存在差异,但不存在数量上的差别。
#2. 名义分类特征
名义特征的类别之间没有任何固有的顺序关系,例如颜色、国家或动物类型。 这些类别之间只存在性质上的差异。
数组特征
数组特征是指以数组或列表形式组织的数据。 数据科学家和机器学习开发人员经常使用数组特征来处理序列数据或嵌入分类数据。
#1. 嵌入数组特征
嵌入数组将分类数据转换为密集的向量形式,常用于自然语言处理和推荐系统。
#2. 列表数组特征
列表数组存储数据的序列,例如订单中的项目列表或操作历史记录。
数值特征
数值特征代表定量数据,可以进行数学运算,常用于机器学习模型的训练。
#1. 区间数值特征
区间特征的值之间具有一致的间隔,但没有真正的零点,例如温度监测数据。 在这里,零度可能表示冰冻温度,但属性仍然存在。
#2. 比率数值特征
比率特征的值之间具有一致的间隔,并且具有真正的零点,例如年龄、身高和收入。
特征工程在机器学习和数据科学中的重要性
- 有效的特征提取可以提升模型的准确性,使预测结果更加可靠,为决策提供更有价值的依据。
- 精细的特征选择可以消除不相关或冗余的属性,简化模型结构,并节省计算资源。
- 精心设计的特征有助于揭示数据中的潜在模式,帮助数据科学家理解数据集中的复杂关系。
- 根据特定的算法定制特征可以优化各种机器学习方法的模型性能。
- 精心设计的特征可以加速模型训练过程,降低计算成本,从而简化机器学习工作流程。
接下来,我们将逐步探索特征工程的流程。
特征工程流程分步

- 数据收集: 第一步是从各种来源(例如数据库、文件或 API)收集原始数据。
- 数据清理: 获得数据后,必须通过识别和纠正错误、不一致或异常值来清理数据。
- 处理缺失值: 缺失值可能会干扰机器学习模型的特征存储。 如果忽略它们,模型可能会产生偏差。 因此,必须进行更深入的研究,以适当填充缺失值或小心地省略它们,而不会对模型产生负面影响。
- 编码分类变量: 必须将分类变量转换为机器学习算法可识别的数字格式。
- 缩放和标准化: 缩放可以确保数值特征处于一致的尺度,避免数值较大的特征主导机器学习模型。
- 特征选择: 此步骤旨在识别并保留最相关的特征,降低数据维度并提高模型效率。
- 特征创建: 有时,可以基于现有特征设计新的特征,以捕获更深层次的信息。
- 特征转换: 诸如对数或幂转换之类的转换技术,可以使数据更适合建模。
接下来,我们将探讨一些常用的特征工程方法。
特征工程方法
#1. 主成分分析 (PCA)
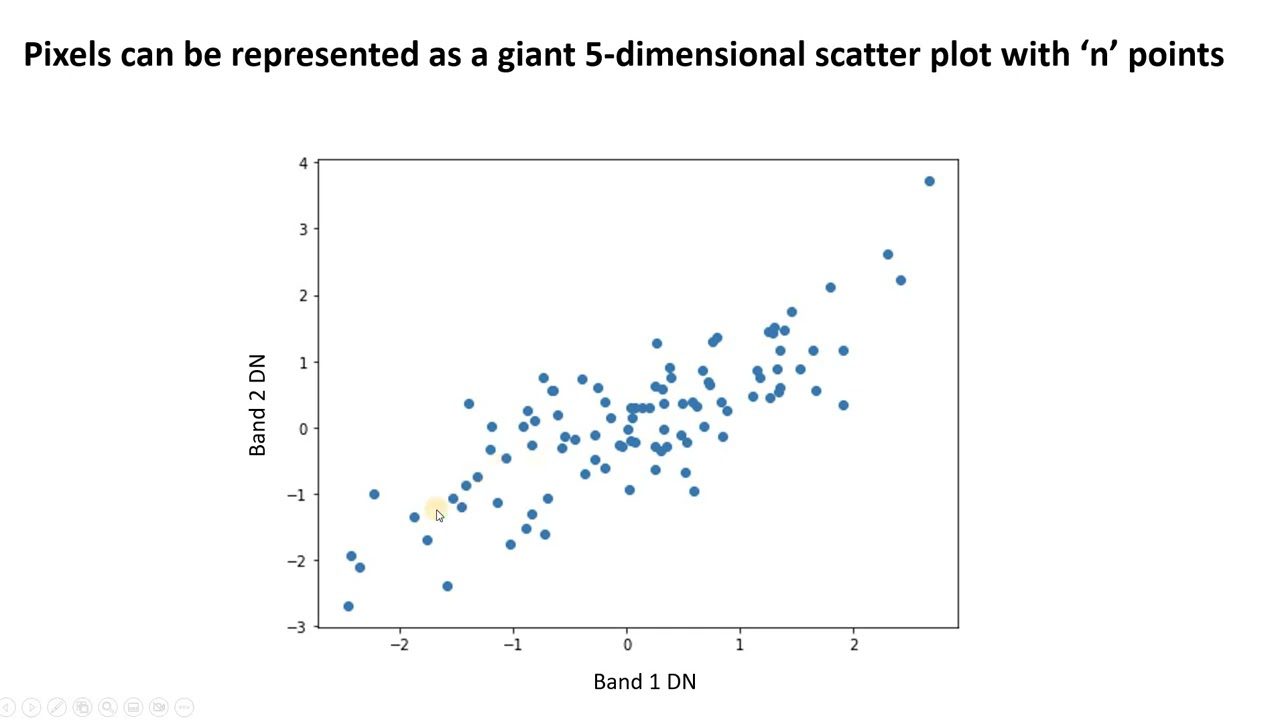
PCA 通过寻找新的不相关特征来简化复杂数据,这些特征被称为主成分。 您可以使用 PCA 来降低数据维度,并提升模型性能。
#2. 多项式特征
创建多项式特征意味着添加现有特征的幂次项,以捕获数据中更复杂的非线性关系。 这有助于模型理解数据中潜在的非线性模式。
#3. 处理异常值
异常值是可能影响模型性能的不寻常的数据点。 必须识别并处理异常值,以防止它们对模型结果产生偏差。
#4. 对数变换
对数变换可以帮助我们标准化偏态分布的数据,减少极端值的影响,使数据更适合建模。
#5. t-分布式随机邻域嵌入 (t-SNE)
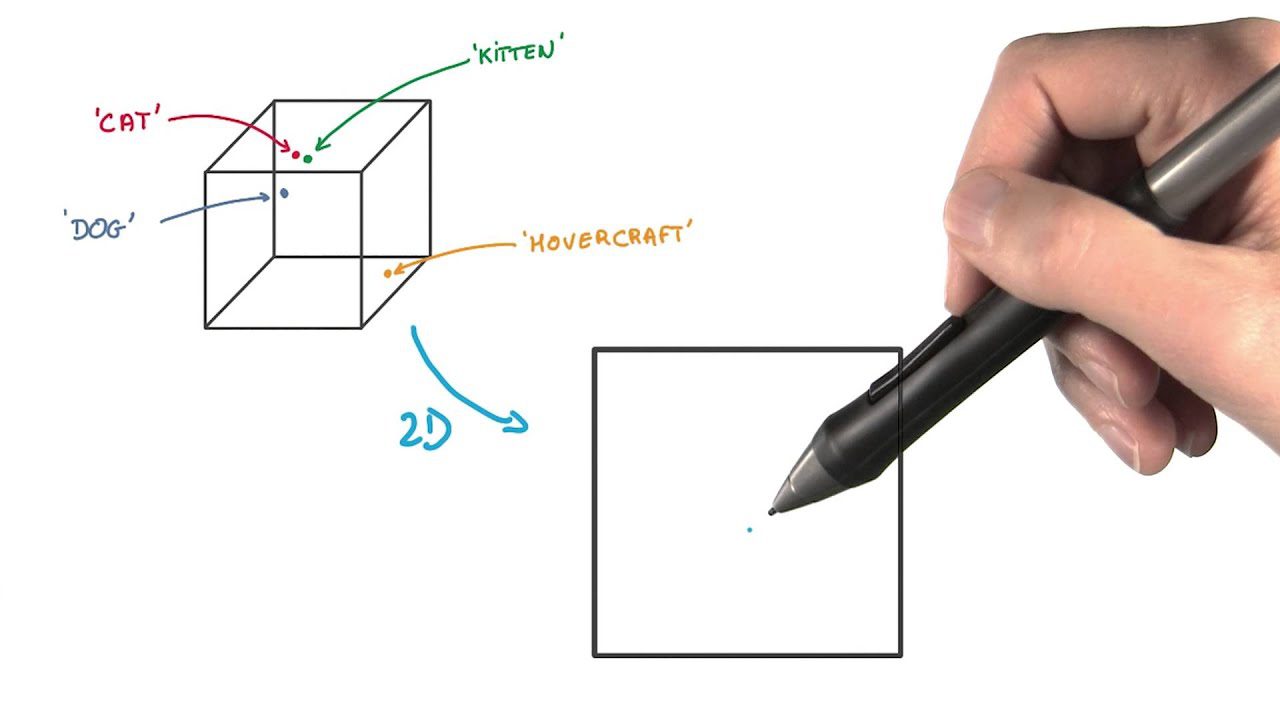
t-SNE 适用于高维数据的可视化。 它可以降低数据维度,并使数据中的集群更加明显,同时保留数据的整体结构。
在此方法中,数据点被表示为低维空间中的点,相似的数据点在原始高维空间和低维表示中都相互接近。
与其他降维方法不同,t-SNE 保留了数据点之间的结构和距离。
#6. 独热编码
独热编码将分类变量转换为二进制格式(0 或 1),为每个类别创建一个新的二进制列,使分类数据适合机器学习算法。
#7. 计数编码
计数编码将分类值替换为它们在数据集中出现的次数。 它可以通过分类变量捕获有效信息。 在这种方法中,我们使用每个类别的频率或计数作为新的数值特征,而不是使用原始的类别标签。
#8. 特征标准化

数值较大的特征往往会主导数值较小的特征,这可能导致机器学习模型产生偏差。 标准化有助于防止此类偏差。
标准化过程通常涉及以下两种常用技术:
- Z 分数标准化: 此方法对每个特征进行转换,使其平均值为 0,标准差为 1。 具体做法是从每个数据点中减去特征的平均值,然后将结果除以标准差。
- 最小-最大缩放: 最小-最大缩放将数据转换为特定范围,通常在 0 到 1 之间。通过从每个数据点减去特征的最小值,然后除以该范围实现此目的。
#9. 归一化
通过归一化,数值特征被缩放到一个共同的范围,通常在 0 和 1 之间。归一化保留了值之间的相对差异,并确保所有特征都处于公平的竞争环境中。

#1. Featuretools
Featuretools 是一个开源的 Python 框架,可以自动从时序和关系数据集中创建特征。 它可以与您已用于开发机器学习管道的工具一起使用。
该解决方案使用深度特征合成技术来实现特征工程的自动化。 它提供了一个用于创建特征的底层函数库。 Featuretools 还提供了一个 API,这在处理时间相关数据时非常理想。
#2. CatBoost
如果您正在寻找一个开源库,该库将多个决策树组合在一起以创建强大的预测模型,那么 CatBoost 是一个不错的选择。 该解决方案使用默认参数提供准确的结果,从而避免了花费数小时调整参数的麻烦。
CatBoost 还允许您使用非数字因素来提高训练结果。 借助此库,您还可以获得更准确的结果和更快的预测速度。
#3. Feature Engine
Feature Engine 是一个 Python 库,它提供了多个转换器,以及可用于机器学习模型的精选功能。 它包含了变量转换、变量创建、日期时间特征、预处理、分类编码、异常值处理以及缺失数据插补等转换器。 该库能够自动识别数值、分类和日期时间变量。
特征工程学习资源
在线课程和虚拟课程

#1. Python 机器学习的特征工程:Datacamp
这个 Datacamp 的 Python 机器学习特征工程课程 可以帮助您创建能够提高机器学习模型性能的新特征。 它将教您如何执行特征工程和数据处理,以开发复杂的机器学习应用程序。
#2. 机器学习的特征工程:Udemy
在 这个 Udemy 的机器学习特征工程课程 中,您将学习插补、变量编码、特征提取、离散化、日期时间特征、异常值等主题。 参与者还将学习如何处理倾斜变量,以及处理不常见、不可见和罕见的类别。
#3. 特征工程:Pluralsight
这个 Pluralsight 的学习路径 共包含六门课程。 这些课程将帮助您了解特征工程在机器学习工作流程中的重要性、应用其技术的方法,以及如何从文本和图像中提取特征。
#4. 机器学习的特征选择:Udemy
通过 这个 Udemy 的课程,参与者可以学习特征洗牌、过滤器、包装器和嵌入方法,以及递归特征消除和穷举搜索。 本课程还讨论了特征选择技术,包括使用 Python、Lasso 和决策树的特征选择技术。 该课程包含 5.5 小时的点播视频和 22 篇文章。
#5. 机器学习的特征工程:Great Learning
这个来自 Great Learning 的课程 将向您介绍特征工程,并教您有关过采样和欠采样的知识。 此外,它还提供模型调整的实践练习。
#6. 特征工程:Coursera
加入 Coursera 的课程,学习如何使用 BigQuery ML、Keras 和 TensorFlow 执行特征工程。 这门中级课程还涵盖了高级的特征工程实践。
数字或精装书籍

#1. 机器学习的特征工程
本书介绍了如何将特征转换为机器学习模型可用的格式。
它还通过实践练习,教授特征工程的原理和实际应用。
#2. 特征工程和选择
通过阅读这本书,您将了解在开发预测模型的不同阶段中可以采用的方法。
从中,您将学习如何寻找建模的最佳预测变量表示。
#3. 特征工程变得简单
本书是一本指南,旨在增强机器学习算法的预测能力。
它通过提供深入的数据洞察,教您如何为基于机器学习的应用程序设计和创建有效的功能。
#4. 特征工程训练营
本书通过实际案例研究,教授特征工程技术,以获得更好的机器学习效果并升级数据整理能力。
通过阅读本书,您可以确保在不花费大量时间调整机器学习参数的情况下,获得改进的模型结果。
#5. 特征工程的艺术
本书是所有数据科学家或机器学习工程师必不可少的资源。
它采用了跨领域的方法,讨论了图、文本、时间序列、图像和案例研究。
结论
至此,您已了解如何执行特征工程。 掌握了定义、逐步过程、方法和学习资源之后,您可以将它们应用于机器学习项目,并收获成功!
接下来,请查看有关强化学习的文章。