认识合成数据:定义、优势及工具
在当今时代,数据对于构建先进的机器学习模型、严谨测试应用程序以及洞察商业趋势至关重要。然而,为了符合各种严格的数据法规,数据往往被小心保管并受到严格保护。
访问这些受到保护的数据,通常需要花费数月时间才能获得必要的批准。因此,企业正在探索一种有效的替代方案:合成数据。
何谓合成数据?

合成数据是人为创建的数据,其统计特性与现有真实数据集相似。这种数据既可与真实数据一同使用,以支持并优化人工智能模型,也可完全替代真实数据。
由于合成数据不属于任何数据主体,并且不包含个人身份信息或敏感数据,例如社会安全号码,因此它成为真实生产数据的隐私保护型替代品。
真实数据与合成数据的差异
- 最主要的差异在于数据的生成方式。真实数据源于实际受试者,在调查过程中或当他们使用应用程序时收集。而合成数据则是由人工生成,但仍然反映了原始数据集的统计特征。
- 第二个差异体现在数据保护法规上。对于真实数据,受试者有权了解哪些关于他们的数据被收集、收集的原因以及如何使用这些数据的限制。然而,这些法规不适用于合成数据,因为它不与任何个人相关联,并且不包含个人信息。
- 第三个差异是数据量。对于真实数据,您只能拥有用户提供的数据。而对于合成数据,您可以根据需要生成任意数量的数据。
为何应考虑使用合成数据
- 其生产成本相对较低,因为您可以生成更大的数据集,类似于已有的较小数据集。这意味着您的机器学习模型将有更多的数据进行训练。
- 生成的数据会自动标记和清理,无需花费大量时间来准备用于机器学习或分析的数据。
- 由于数据不属于个人身份,不存在隐私问题,可以自由使用和共享。
- 通过确保少数群体得到充分的代表,可以克服人工智能的偏见,从而构建公平且负责任的人工智能。
如何生成合成数据
虽然生成过程因所使用的工具而异,但通常情况下,该过程从将生成器连接到现有数据集开始。之后,您可以识别数据集中的个人识别字段,并将它们标记为排除或混淆。
然后生成器开始识别剩余列的数据类型和统计模式。由此,您可以根据需要生成大量的合成数据。
您通常可以将生成的数据与原始数据集进行比较,以评估合成数据与真实数据的相似程度。
接下来,我们将探索一些合成数据生成工具,用于训练机器学习模型。
Mostly AI

Mostly AI 提供一个基于人工智能的合成数据生成器,它可以学习原始数据集的统计模式。然后,人工智能会生成符合这些学习模式的虚拟数据。
通过 Mostly AI,您可以生成具有参照完整性的完整数据库,并可以整合各种数据,以帮助构建更优秀的人工智能模型。
Synthesized.io

Synthesized.io 被众多领先企业应用于他们的人工智能计划。要使用 synthesize.io,您需要在 YAML 配置文件中指定数据需求。
然后,您可以创建一个任务,并将其作为数据管道的一部分运行。此外,它还提供了一个非常慷慨的免费套餐,供您进行实验,并评估它是否满足您的数据需求。
YData

利用 YData,您可以生成表格、时间序列、事务、多表和关系数据,从而避免数据收集、共享和质量等问题。
它配备了人工智能和SDK,方便与平台交互。同时,他们还提供慷慨的免费套餐,供您试用产品。
Gretel AI

Gretel AI 提供 API 用于生成无限量的合成数据。Gretel 有一个开源数据生成器,可供安装和使用。
或者,您可以使用他们的 REST API 或 CLI,但需要付费。不过,他们的定价合理,并与业务规模成正比。
Copulas
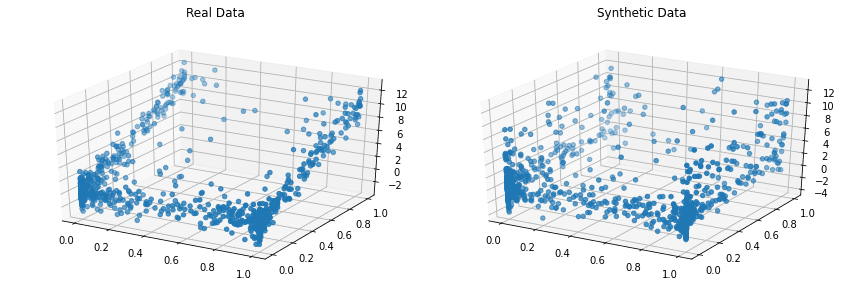
Copulas 是一个开源 Python 库,使用 copula 函数来建模多元分布并生成遵循相同统计属性的合成数据。
该项目于 2018 年在麻省理工学院启动,是合成数据仓库项目的一部分。
CTGAN
CTGAN 由一个生成器组成,该生成器能够从单表真实数据中学习,并从已识别的模式生成合成数据。
它以开源 Python 库的形式实现。CTGAN 和 Copulas 都是合成数据库项目的一部分。
DoppelGANger
DoppelGANger 是生成对抗网络的开源实现,用于生成合成数据。
DoppelGANger 可用于生成时间序列数据,并被 Gretel AI 等公司使用。该 Python 库免费提供,并且是开源的。
Synth

Synth 是一种开源数据生成器,可以帮助您根据规范创建真实数据,隐藏个人身份信息,并为您的应用程序开发测试数据。
您可以使用 Synth 生成实时序列和关系数据,以满足您的机器学习需求。Synth 与数据库无关,因此您可以将其与 SQL 和 NoSQL 数据库一起使用。
SDV.dev
SDV 代表综合数据库。SDV.dev 是一个软件项目,于 2016 年在麻省理工学院启动,并创建了用于生成合成数据的不同工具。
这些工具包括 Copulas、CTGAN、DeepEcho 和 RDT。这些工具以开源 Python 库的形式实现,您可以轻松使用它们。
Tofu
Tofu 是一个开源 Python 库,用于根据英国生物样本库的数据生成合成数据。与之前提到的可帮助您根据现有数据集生成任何类型数据的工具不同,Tofu 生成的数据仅类似于生物银行的数据。
英国生物银行是一项对来自英国的 50 万中年成年人的表型和基因型特征的研究。
Twinify
Twinify 是一个软件包,可以用作库或命令行工具,通过生成具有相同统计分布的合成数据来孪生敏感数据。
要使用 Twinify,您需要提供真实数据作为 CSV 文件,它会从数据中学习以生成可用于生成合成数据的模型。它是完全免费的。
Datanamic
Datanamic 可帮助您为数据驱动和机器学习应用程序制作测试数据。它基于电子邮件、姓名和电话号码等列特征生成数据。
Datanamic 数据生成器是可定制的,支持大多数数据库,例如 Oracle、MySQL、MySQL Server、MS Access 和 Postgres。它支持并确保生成数据中的引用完整性。
Benerator
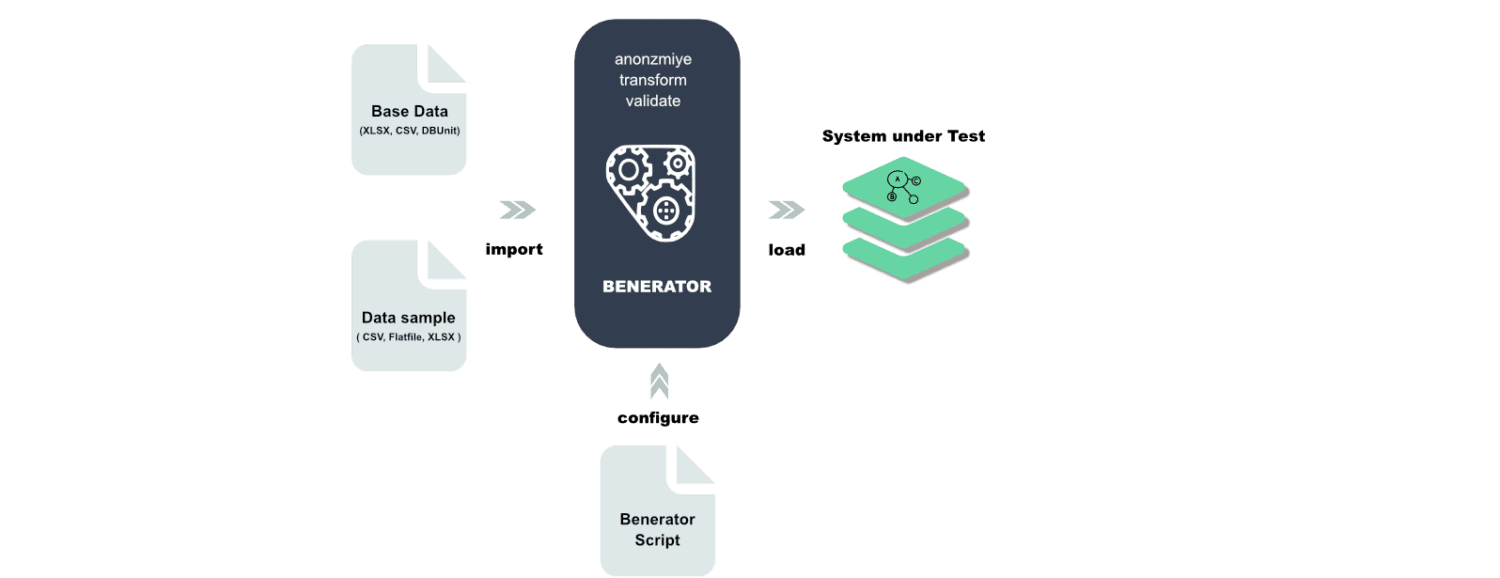
Benerator 是一款用于数据混淆、生成和迁移的软件,适用于测试和培训目的。借助 Benerator,您可以使用 XML(可扩展标记语言)描述数据,并使用命令行工具生成数据。
它旨在供非开发人员使用,您可以使用它生成数十亿行数据。Benerator 是免费且开源的。
总结
据 Gartner 估计,到 2030 年,用于机器学习的合成数据将超过真实数据。
考虑到使用真实数据的成本和隐私问题,不难理解原因。因此,企业有必要了解合成数据以及帮助他们生成合成数据的各种工具。
下一步,您可以查看适用于您在线业务的综合监控工具。