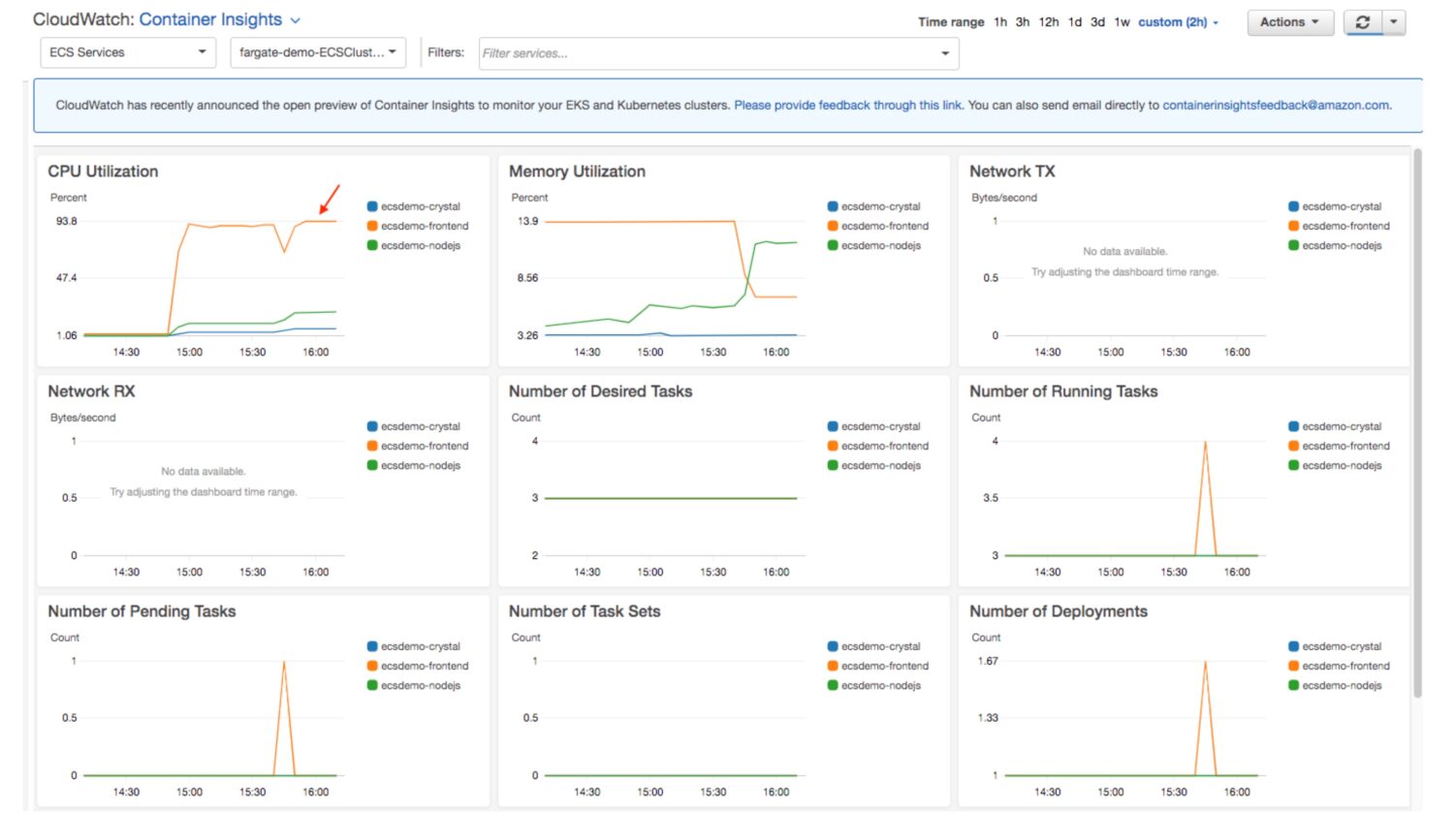
利用 AWS CloudWatch 日志洞察创建仪表板指标
每个 AWS 服务都会将其运行情况记录到 CloudWatch 日志组下的文件中。为了方便识别,日志组通常以服务本身命名。默认情况下,服务的系统消息或公开状态信息会被写入这些日志文件中。
然而,除了默认的日志消息外,你还可以添加自定义的日志消息信息。 如果明智地创建这些日志,它们可以用来创建实用的 CloudWatch 仪表板。
通过使用指标和结构化信息,可以提供关于作业处理的额外详细信息。它们不仅可以包含与服务相关的标准系统信息,你还可以扩展这些信息,并将它们聚合到自定义的小部件或指标中。
查询日志文件
资料来源:aws.amazon.com
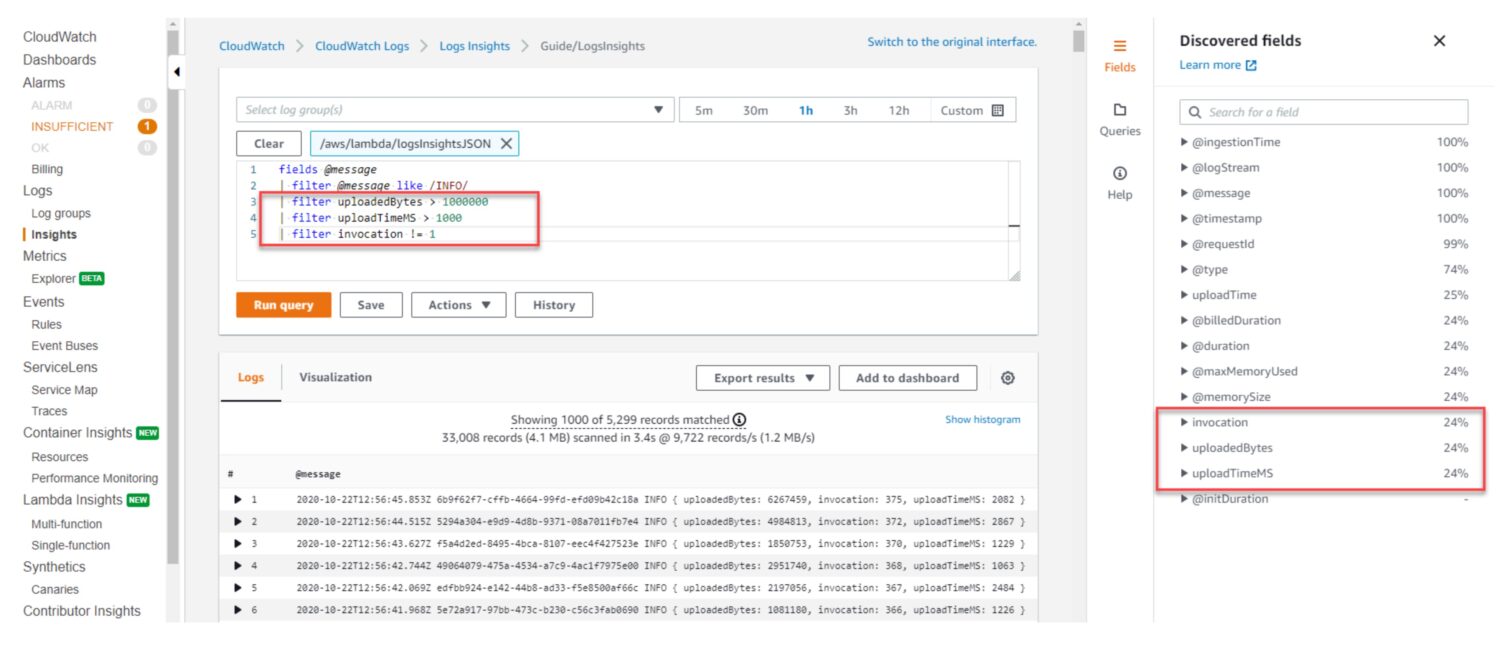
AWS CloudWatch 日志洞察允许你实时搜索和分析来自 AWS 资源的日志数据。你可以把它想象成一个数据库视图。你在仪表板上定义查询,仪表板会在你访问它时,或在过去指定的时间窗口内选择数据,就像你在仪表板视图中定义的那样。
它使用一种叫做 CloudWatch Logs Insights 的查询语言来搜索和分析日志数据。该查询语言基于 SQL 语言的一个子集。它允许你搜索和过滤日志数据。你可以搜索特定的日志事件、自定义的日志文本或关键词,并根据特定的字段来过滤日志数据。最重要的是,它可以聚合一个或多个日志文件中的日志数据,以生成汇总指标和可视化。
当你运行查询时,CloudWatch Log Insights 会搜索日志组中的日志数据。然后,它会返回符合你的查询条件的文件中生成的文本。
日志文件查询示例
让我们来看一些基本的查询,以便理解这个概念。
默认情况下,每个服务都会记录一些重要的服务错误。即使你没有为这类错误事件创建专用的自定义日志。通过一个简单的查询,你可以计算过去一小时内应用程序日志中的错误数量:
fields @timestamp, @message | filter @message like /ERROR/ | stats count() by bin(1h)
或者,这是如何监控你的 API 在过去一天的平均响应时间:
fields @timestamp, @message | filter @message like /API response time/ | stats avg(response_time) by bin(1d)
由于默认情况下,CPU 利用率是服务记录到 CloudWatch 中的信息,你也可以收集此类指标:
fields @timestamp, @message | filter @message like /CPUUtilization/ | stats avg(value) by bin(1h)
你可以自定义这些查询,以适应你的特定用例,并可以用于在 CloudWatch 控制面板中创建自定义指标和可视化。方法是将小部件放在仪表板上,然后在小部件内放置代码,以定义要选择的内容。
以下是一些可在 CloudWatch 控制面板中使用,并由 Log Insights 中的内容填充的小部件:
- 文本小部件 – 显示基于文本的信息,例如 CloudWatch Insights 查询的输出。
- 日志查询小部件 – 显示 CloudWatch Insights 日志查询的结果,例如应用程序日志中的错误数。
如何为仪表板创建有用的日志信息
资料来源:aws.amazon.com
为了在 CloudWatch 控制面板中有效地使用 CloudWatch Insights 查询,最好在为你在系统中使用的每个服务创建 CloudWatch 日志时,遵循一些最佳实践。以下是一些提示:
#1. 使用结构化日志记录
你应该坚持使用预定义的模式,以结构化的格式记录数据的日志格式。这使得使用 CloudWatch Insights 查询搜索和筛选日志数据变得更加容易。
这基本上意味着在你的架构平台中,跨不同的服务标准化你的日志。在开发标准中定义它会很有帮助。
例如,你可以定义,与特定数据库表相关的每个问题,都将以如下起始消息记录:“[TABLE_NAME] 警告/错误:<消息>”。
或者,你可以通过前缀将完整的数据作业与增量的数据作业分开,例如“[FULL/DELTA]”,以仅选择与具体数据处理相关的消息。
你可以定义,在处理来自特定源系统的数据时,系统名称将作为每个相关日志条目的前缀。之后,从日志文件中过滤此类消息,并在其上构建指标,就会容易得多。
资料来源:aws.amazon.com
#2. 使用一致的日志格式
在所有 AWS 资源中使用一致的日志格式,以便使用 CloudWatch Insights 查询更容易地搜索和筛选日志数据。
这一点和前一点颇有关系,但事实是,日志格式越规范,日志数据就越容易被使用。然后,开发人员可以依赖该格式,甚至可以直观地使用它。
残酷的事实是,大多数项目都不会为日志记录的任何标准而烦恼。更重要的是,许多项目甚至根本不创建任何自定义日志。这令人震惊,但同时也很普遍。
我甚至说不清有多少次,我发现自己想知道人们如何在没有任何错误处理方法的情况下生活在这里。如果有人努力将某种错误处理作为异常处理,那他们就错了。
因此,一致的日志格式是一项强大的资产。拥有它们的人并不多。
#3. 包括相关元数据
在日志数据中包含元数据,例如时间戳、资源 ID 和错误代码,以便使用 CloudWatch Insights 查询更容易地搜索和筛选日志数据。
#4. 启用日志轮换
启用日志轮换,以防止你的日志数据变得太大,并使使用 CloudWatch Insights 查询搜索和筛选日志数据变得更加容易。
没有日志数据是一回事,但拥有太多没有结构的日志数据同样令人绝望。如果你不能使用你的数据,就好像根本没有数据一样。
#5. 使用 CloudWatch Logs 代理
如果你情不自禁而拒绝构建你自己的自定义日志系统,那么至少使用 CloudWatch Logs 代理。它们会自动将日志数据从你的 AWS 资源发送到 CloudWatch Logs。这使得使用 CloudWatch Insights 查询搜索和筛选日志数据变得更加容易。
更复杂的见解查询示例
CloudWatch Insights 查询可能比两行语句更复杂。
fields @timestamp, @message
| filter @message like /ERROR/
| filter @message not like /404/
| parse @message /.*[(?<timestamp>[^]]+)].*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/
| stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status
| sort count desc
| limit 20
此查询执行以下操作:
- 选择包含字符串“ERROR”但不包含“404”的日志事件。
- 解析日志消息,以提取时间戳、HTTP 方法、路径、状态代码和响应时间。
- 计算每个 HTTP 方法、路径、状态代码和小时的组合的平均响应时间和日志事件计数。
- 按降序计数对结果进行排序。
- 将输出限制为前 20 个结果。
此查询识别应用程序中最常见的错误,并跟踪 HTTP 方法、路径和状态代码的每种组合的平均响应时间。你可以使用结果在 CloudWatch 控制面板中创建自定义指标和可视化效果,以监控 Web 应用程序的性能,并解决问题。
另一个查询 Amazon S3 服务消息的例子:
fields @timestamp, @message
| filter @message like /REST.API.REQUEST/
| parse @message /.*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/
| stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status
| sort count desc
| limit 20
- 该查询选择包含字符串“REST.API.REQUEST”的日志事件。
- 然后解析日志消息,以提取 HTTP 方法、路径、状态代码和响应时间。
- 它计算每个 HTTP 方法、路径和状态代码组合的平均响应时间和日志事件计数,并按计数降序对结果进行排序。
- 将输出限制为前 20 个结果。
你可以使用此查询的输出,在 CloudWatch 控制面板中创建一个折线图,显示一段时间内 HTTP 方法、路径和状态代码的每个组合的平均响应时间。
构建仪表板
要从 CloudWatch Insights 日志查询的输出中,填写 CloudWatch 仪表板中的指标和可视化,你可以导航到 CloudWatch 控制台,并按照仪表板向导构建你的内容。
之后,这是 CloudWatch 仪表板的代码外观,包含由 CloudWatch Insights 查询数据填充的指标:
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 12,
"height": 6,
"properties": {
"metrics": [
[
"AWS/EC2",
"CPUUtilization",
"InstanceId",
"i-0123456789abcdef0",
{
"label": "CPU Utilization",
"stat": "Average",
"period": 300
}
]
],
"view": "timeSeries",
"stacked": false,
"region": "us-east-1",
"title": "EC2 CPU Utilization"
}
},
{
"type": "log",
"x": 0,
"y": 6,
"width": 12,
"height": 6,
"properties": {
"query": "fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
",
"region": "us-east-1",
"title": "Application Errors"
}
}
]
}
此 CloudWatch 控制面板包含两个小部件:
- 一个指标小部件,显示 EC2 实例随时间变化的平均 CPU 使用率。 CloudWatch Insights 查询填充小部件。它选择特定 EC2 实例的 CPU 利用率数据,并以 5 分钟为间隔进行聚合。
- 一个日志小部件,显示一段时间内应用程序错误的数量。它选择包含字符串“ERROR”的日志事件,并按小时聚合它们。
它是一个 JSON 格式的文件,其中包含仪表板和指标的定义。它包含(作为属性)洞察力查询本身。
你可以获取代码,并将其部署到你需要使用的任何 AWS 账户。假设服务和日志消息在你的所有 AWS 账户和阶段上都是一致的,则仪表板将适用于所有账户,而无需更改仪表板的源代码。
最后的话
建立可靠的日志记录结构始终是对系统可靠性未来的良好投资。现在,它可以服务于更大的目的。你可以拥有带有指标和可视化效果的有用仪表板,作为其副作用。
开发团队、测试团队和生产用户只需要完成一次,只需做一点额外的工作,就可以从同一个解决方案中受益。
接下来,查看最好的 AWS 监控工具。