MongoDB 聚合管道:高级查询的强大工具
在 MongoDB 中执行复杂查询时,聚合管道是首选方法。如果您还在使用 MongoDB 的 MapReduce 功能,为了获得更高的计算效率,强烈建议切换到聚合管道。
MongoDB 中的聚合及其工作原理
聚合管道是一种多阶段处理过程,用于在 MongoDB 中执行复杂的数据查询。它通过一系列称为“管道”的不同阶段来处理数据。每个阶段的输出可以作为下一个阶段的输入,从而实现数据的逐步转换。
例如,您可以将筛选操作的结果传递给排序阶段,然后进一步进行处理,最终得到您期望的输出结果。
聚合管道的每个阶段都使用 MongoDB 运算符来生成一个或多个转换后的文档。根据您的查询需求,同一个阶段可能会在管道中出现多次。例如,您可能需要在聚合管道中多次使用 $count 或 $sort 等运算符。
聚合管道的阶段
聚合管道通过多个阶段处理数据。 MongoDB 提供了多种不同的阶段,您可以在 MongoDB 官方文档 中找到它们的详细描述。
下面我们介绍一些最常用的阶段:
$match 阶段
$match 阶段用于在聚合管道的起始阶段定义过滤条件。您可以利用它来选择符合特定条件的数据,从而减少后续阶段需要处理的数据量。
$group 阶段
$group 阶段根据指定的键值对,将数据划分为不同的组。每个组代表输出文档中的一个键值。
例如,假设有以下销售数据:
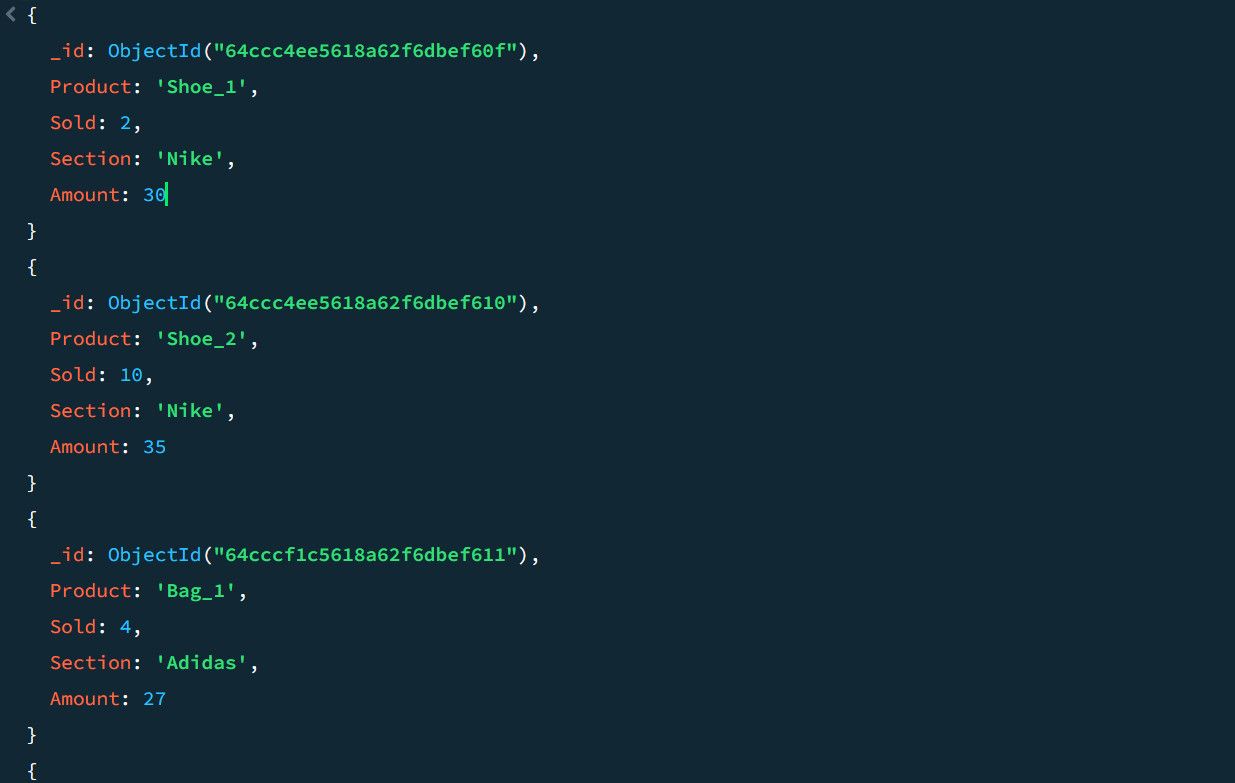
使用聚合管道,您可以计算每个产品类别的总销售量和最高单笔销售额:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
在这个例子中,_id: $Section 表示按产品类别对输出文档进行分组。通过指定 total_sales_count 和 top_sales 字段,MongoDB 将根据聚合器的定义(如 $sum, $min, $max 或 $avg)创建新的键值对。
$skip 阶段
$skip 阶段允许您在输出中跳过指定数量的文档。它通常在分组阶段之后使用。例如,如果您期望输出两个文档,但使用 $skip: 1,则只输出第二个文档。
要添加跳过阶段,请在聚合管道中插入 $skip 操作符:
...,
{
$skip: 1
},
$sort 阶段
$sort 阶段允许您按升序或降序对数据进行排序。例如,您可以对之前查询示例中的数据按销售额降序排序,以确定哪个类别的销售额最高。
将 $sort 操作符添加到之前的查询中:
...,
{
$sort: {top_sales: -1}
},
$limit 阶段
$limit 操作符可以限制聚合管道输出的文档数量。 例如,可以使用 $limit 操作符获取上一阶段返回的销售额最高的部分:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
上述操作只返回第一个文档,即销售额最高的部分,因为它在排序后的输出结果中位于顶部。
$project 阶段
$project 阶段允许您根据需要自定义输出文档。通过 $project 操作符,您可以指定要包含在输出中的字段,并自定义它们的键名。
例如,没有 $project 阶段的输出可能如下所示:
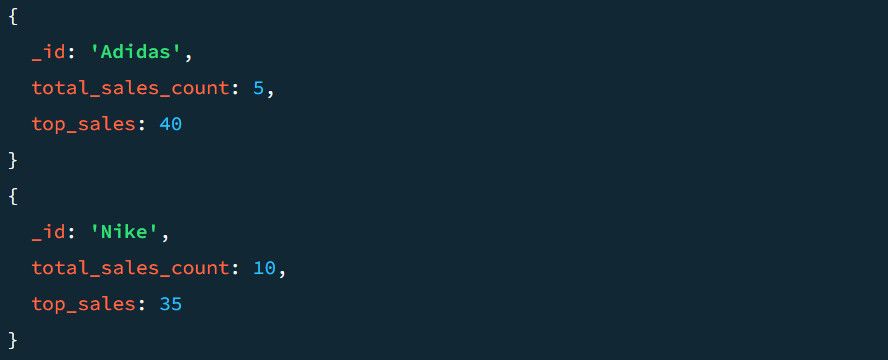
让我们看看 $project 阶段如何使用。 要将 $project 添加到管道中:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
由于之前的数据是按照产品类别分组的,因此上面的操作将输出文档中每个产品类别的信息。它还确保输出中的汇总销售数量和最高销售量分别显示为 TotalSold 和 TopSale。
与之前的输出相比,最终的输出更清晰:

$unwind 阶段
$unwind 阶段将文档中的数组分解为单独的文档。例如,假设有以下订单数据:
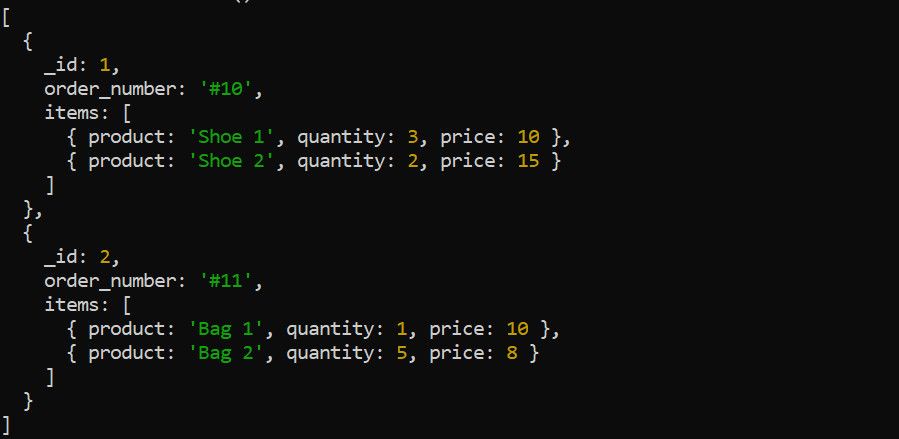
在使用其他聚合阶段之前,可以使用 $unwind 阶段展开 items 数组。例如,如果您想计算每个产品的总收入,则展开 items 数组是必要的:
db.Orders.aggregate([
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
以下是上述聚合查询的结果:

如何在 MongoDB 中创建聚合管道
聚合管道虽然包含多个操作,但前面介绍的阶段让您了解如何在管道中应用它们,包括每个操作的基本查询。
使用之前的销售数据示例,让我们将上面讨论的一些阶段放在一起,以便更广泛地了解聚合管道:
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
最终输出看起来像您之前看到的那样:
聚合管道与 MapReduce
在 MongoDB 5.0 版本开始被弃用之前,MapReduce 是在 MongoDB 中聚合数据的常用方法。尽管 MapReduce 在 MongoDB 之外有更广泛的应用,但它的效率低于聚合管道,并且需要单独编写 map 和 reduce 函数的第三方脚本。
而聚合管道是 MongoDB 特有的功能。它为执行复杂的查询提供了一种更清晰、更有效的方式。除了简单易用和查询可扩展性之外,管道阶段的特点也使输出更具可定制性。
聚合管道和 MapReduce 之间还有更多差异。当您从 MapReduce 切换到聚合管道时,您将体会到这些差异。
在 MongoDB 中提高大数据查询效率
如果您需要对 MongoDB 中的复杂数据进行深入计算,您的查询必须尽可能高效。聚合管道非常适合处理高级查询。通过聚合,您可以将多个操作打包到单个高性能管道中并一次性执行,而不是在单独的操作中处理数据,这通常会降低性能。
虽然聚合管道比 MapReduce 更高效,但您还可以通过对数据建立索引来进一步提升聚合的速度和效率。索引可以限制 MongoDB 在每个聚合阶段需要扫描的数据量。