Scikit-LLM 是一个方便的 Python 库,它让大型语言模型(LLM)与 scikit-learn 框架的集成变得更加容易。 它尤其在文本分析任务中表现出色。 如果你熟悉 scikit-learn,那么你会发现使用 Scikit-LLM 非常简单。
需要明确的是,Scikit-LLM 并不是要取代 scikit-learn。 Scikit-learn 是一个通用的机器学习工具包,而 Scikit-LLM 则专注于文本分析任务。
Scikit-LLM 入门指南
要开始使用 Scikit-LLM,你首先需要安装这个库并配置你的 API 密钥。安装过程很简单:在你的 IDE 中创建一个新的虚拟环境,这样可以避免库版本冲突。 然后,在终端运行以下命令:
pip install scikit-llm
这个命令会安装 Scikit-LLM 及其必要的依赖项。
要配置 API 密钥,你需要从 LLM 提供商那里获取。 以 OpenAI 为例,请按照以下步骤操作:
首先,访问 OpenAI API 页面。 接着,点击页面右上角的个人资料图标,并选择“查看 API 密钥”。 这将带你进入 API 密钥管理页面。
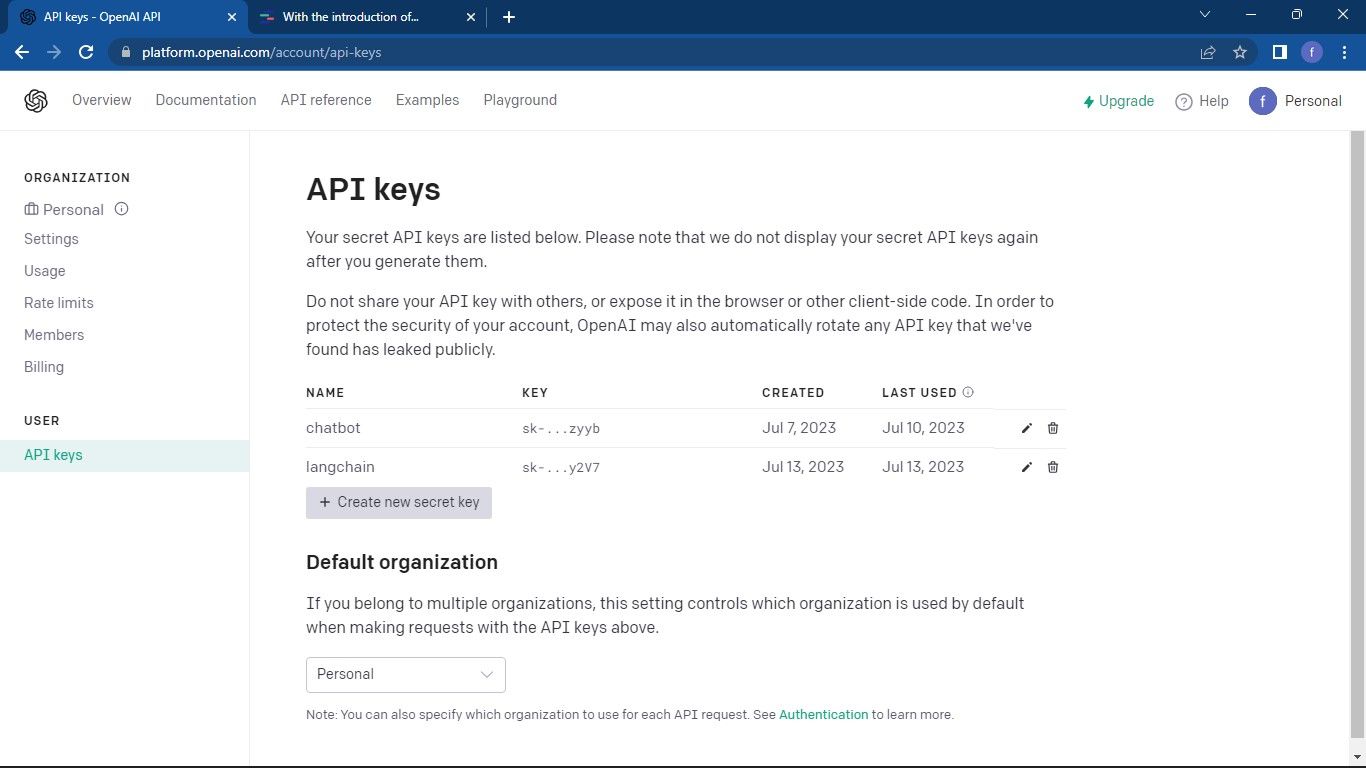
在 API 密钥页面,点击“创建新密钥”按钮。
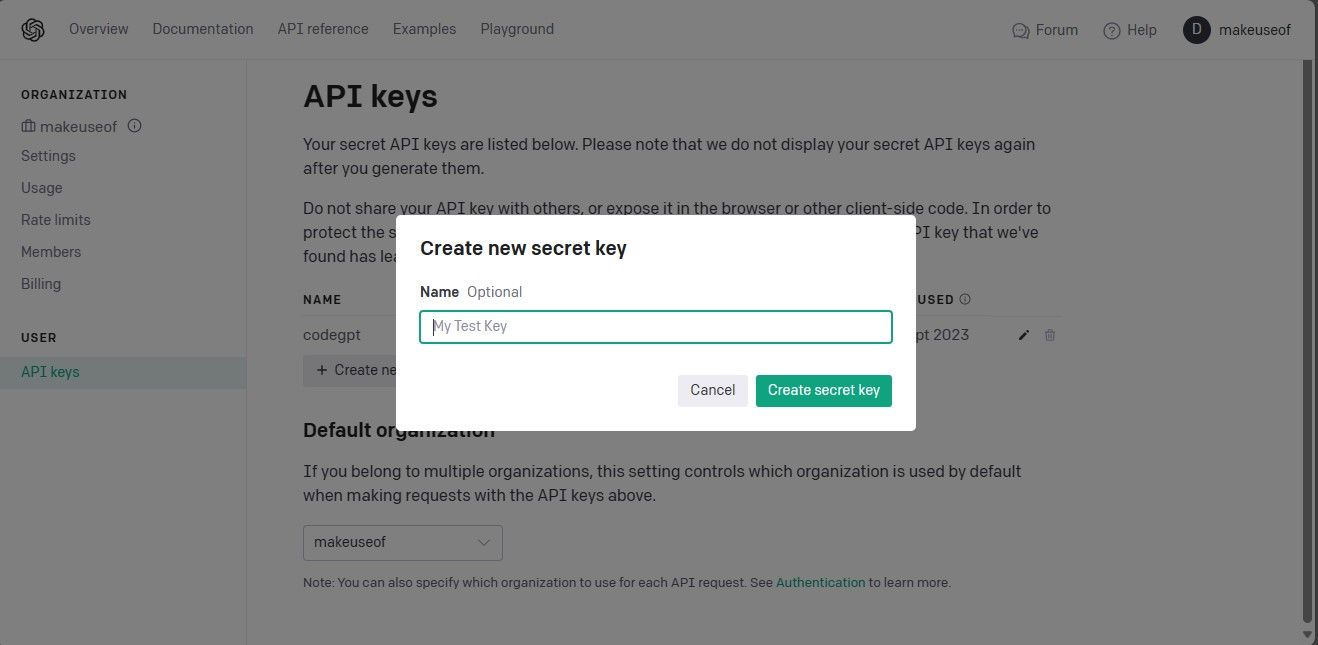
为你的 API 密钥命名,然后点击“创建密钥”生成它。 生成后,请务必复制并妥善保存密钥,因为 OpenAI 不会再次显示它。 如果丢失,你将需要生成新的密钥。
现在,你已经有了 API 密钥。打开你的 IDE,并从 Scikit-LLM 库中导入 `SKLLMConfig` 类。 这个类允许你设置与大型语言模型相关的配置选项。
from skllm.config import SKLLMConfig
你需要配置 OpenAI API 密钥和组织信息。
SKLLMConfig.set_openai_key("Your API key")
SKLLMConfig.set_openai_org("Your organization ID")
请注意,组织 ID 和组织名称并不相同。组织 ID 是你组织的唯一标识符。 要获取组织 ID,请访问 OpenAI 组织设置页面并复制它。 至此,你已经在 Scikit-LLM 和大型语言模型之间建立了连接。
Scikit-LLM 要求你使用按需付费的计划。 这是因为 OpenAI 免费试用帐户的速率限制为每分钟 3 个请求,这对 Scikit-LLM 来说是不够的。
如果尝试使用免费试用帐户进行文本分析,你可能会遇到类似以下内容的错误:

想了解更多关于速率限制的信息,请访问 OpenAI 速率限制页面。
请注意,LLM 提供商不仅仅限于 OpenAI。 你也可以使用其他的 LLM 提供商。
导入必要的库并加载数据集
首先,导入 `pandas` 库来加载数据集。 此外,从 Scikit-LLM 和 scikit-learn 中导入需要的类。
import pandas as pd from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier from skllm.preprocessing import GPTSummarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.preprocessing import MultiLabelBinarizer
接下来,加载用于文本分析的数据集。 这段代码使用了 IMDB 电影数据集,但你可以根据自己的需求调整代码使用你自己的数据集。
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
这里不强制要求只使用数据集的前 100 行,你可以使用整个数据集。
然后,提取特征和标签列,并将数据集拆分为训练集和测试集。
X = data['Description'] y = data['Genre'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
“Genre” 列包含你需要预测的标签。
使用 Scikit-LLM 进行零样本分类
零样本分类是大型语言模型的一项强大功能。 它可以在没有明确标记数据训练的情况下,将文本分类为预定义的类别。 这个功能在你需要将文本分类到模型训练期间未预料到的类别时特别有用。
为了使用 Scikit-LLM 执行零样本分类,你需要使用 `ZeroShotGPTClassifier` 类。
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
输出结果如下:
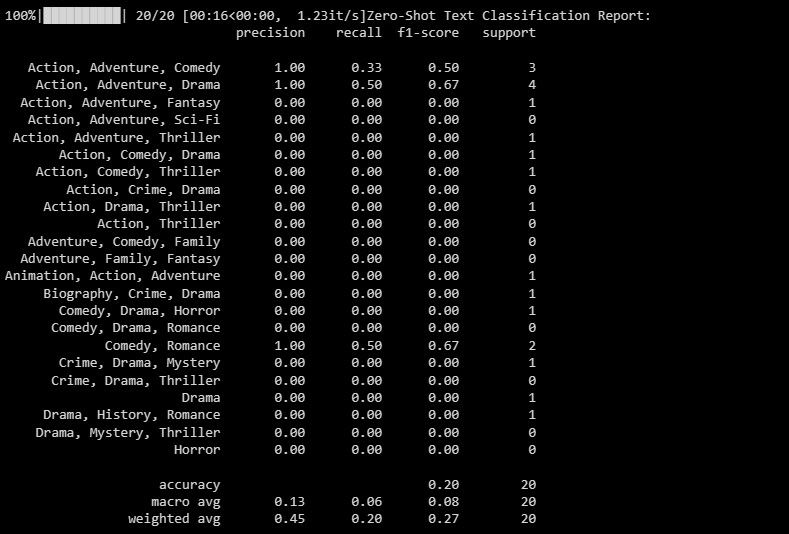
这个分类报告提供了模型尝试预测的每个标签的评估指标。
使用 Scikit-LLM 进行多标签零样本分类
在一些情况下,一个文本可能同时属于多个类别。传统的分类模型很难处理这种情况。但 Scikit-LLM 可以轻松地实现多标签分类。多标签零样本分类对于为单个文本示例分配多个描述性标签至关重要。
可以使用 `MultiLabelZeroShotGPTClassifier` 来预测每个文本样本的标签。
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
在上面的代码中,我们定义了文本可能属于的候选标签。
输出结果如下:
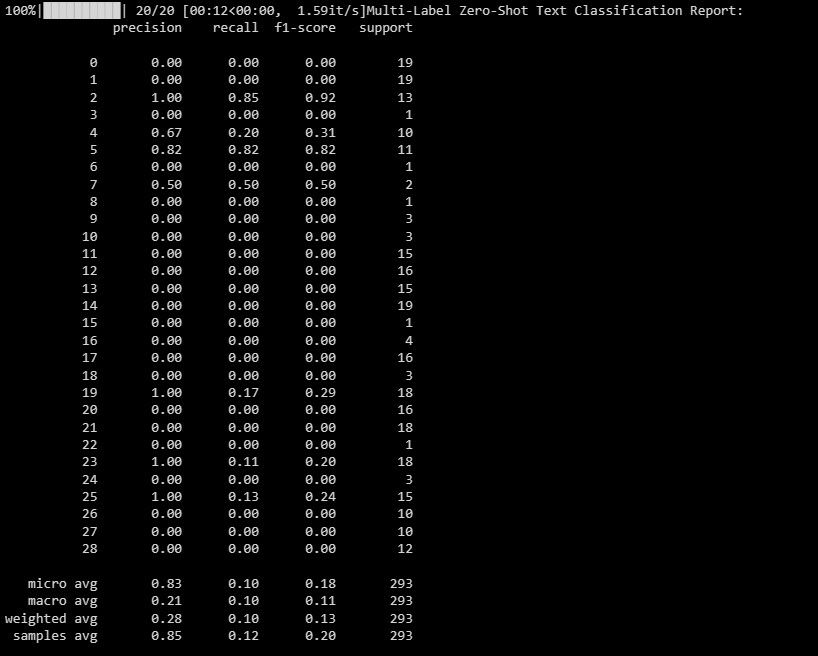
这份报告帮助你了解模型在多标签分类中对每个标签的表现。
使用 Scikit-LLM 进行文本向量化
在文本向量化中,文本数据被转化为机器学习模型可以理解的数字格式。 Scikit-LLM 提供了 `GPTVectorizer` 用于实现这个功能。 它允许你使用 GPT 模型将文本转换为固定维度的向量。
你可以使用词频-逆文档频率 (TF-IDF) 来实现文本向量化。
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5])
这是输出结果:
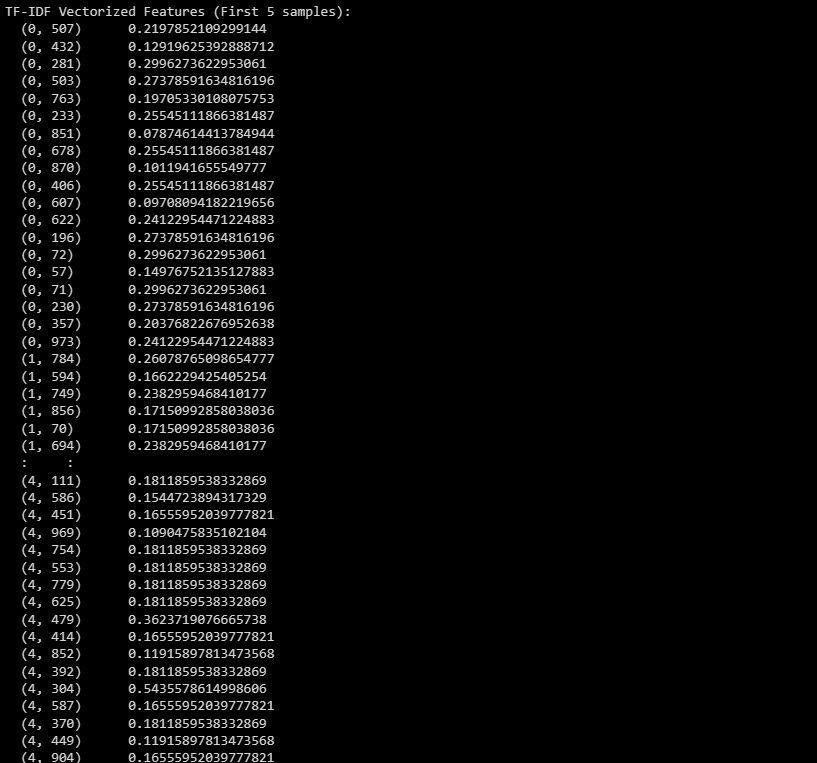
输出显示了数据集中前 5 个样本的 TF-IDF 向量化特征。
使用 Scikit-LLM 进行文本摘要
文本摘要有助于压缩一段文本,同时保留其最重要的信息。 Scikit-LLM 提供了 `GPTSummarizer`,它使用 GPT 模型生成简洁的文本摘要。
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15) summaries = summarizer.fit_transform(X_test) print(summaries)
输出结果如下:
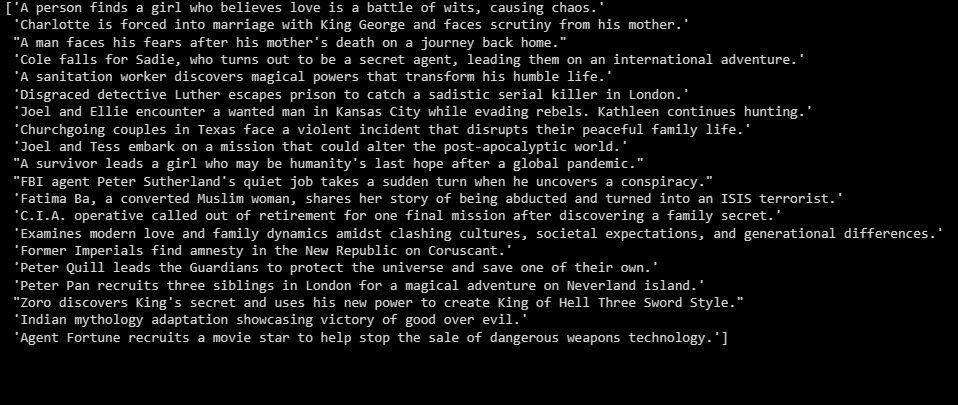
以上是测试数据集的文本摘要。
在大型语言模型之上构建应用程序
Scikit-LLM 为使用大型语言模型进行文本分析打开了无限可能。 深入了解大型语言模型背后的技术至关重要。 这将帮助你理解它们的优点和局限性,从而使你能够基于这项尖端技术构建高效的应用。