你是否經常依賴聊天機器人或人工智慧(AI)來協助工作或解答問題呢?
如果你的答案是「非常多!」或「一直!」,那麼你可能需要稍微擔心一下。😟
無論你是一位熱衷使用AI工具來研究論文的研究生,或者是一位試圖完全依靠AI生成程式碼的程式設計師,AI產出的內容都有很高的機率出現不準確的情況,這主要歸咎於AI訓練數據中存在的不一致性或虛構數據。
儘管AI和機器學習(ML)模型正在改變世界,承擔重複性任務並通過自動化解決許多問題,但在根據所提供的提示生成精確輸出方面,仍有許多工作需要完成。
如果你花足夠的時間使用內容生成器和聊天機器人,很快就會發現你得到的答案可能是錯誤的、不相關的,甚至是虛構的。這些情況被稱為AI幻覺或虛構,對於依賴生成式AI機器人的組織和個人而言,這已然成為一個巨大的問題。
無論你是否經歷過AI幻覺並希望了解更多,本文都將深入探討這個主題。我們將了解AI幻覺的意義、發生的原因、範例,以及是否有可能修復它。
讓我們開始吧!
什麼是AI幻覺?
AI幻覺指的是AI模型或大型語言模型(LLM)生成虛假、不準確或不合邏輯的資訊。 AI模型產生的自信回應,實際上與其訓練數據不匹配或不一致,並且將數據表示為事實,即使它毫無邏輯意義或推理!
俗話說,人非聖賢,孰能無過!😅

人工智慧工具和模型(例如ChatGPT)通常經過訓練,以預測與所詢問的查詢最匹配的詞語。雖然機器人通常會產生事實且準確的回應,但有時這種演算法使其缺乏推理能力,從而導致聊天機器人吐出與事實不符且錯誤的陳述。
換句話說,AI模型有時會「幻覺」回應,試圖取悅你(使用者)——使其更帶有偏見、不夠客觀、專業化或不夠充分。
AI幻覺的種類繁多,從輕微的不一致到完全錯誤或捏造的反應都有。以下是你可能遇到的一些AI幻覺類型:
#1. 句子矛盾:當LLM模型生成的句子與其先前聲明的句子完全矛盾時,就會發生這種情況。
#2. 事實矛盾:當AI模型將虛假或虛構的資訊呈現為事實時,就會出現這種幻覺類型。
#3. 提示矛盾:當輸出與產生輸出的提示相矛盾時,就會發生這種幻覺類型。例如,如果提示是「為我的朋友寫一份生日派對邀請函」。該模型可能會產生類似「週年紀念快樂,爸爸媽媽」的輸出。
#4. 隨機或不相關的幻覺:當模型生成與給定提示完全不相關的輸出時,就會發生這種幻覺。例如,如果提示是「紐約市有什麼特別之處?」你可能會收到這樣的輸出:「紐約是美國人口最稠密的城市之一。狗是最忠誠的動物,也是人類最好的朋友。」
另請閱讀:生成式AI搜索如何改變搜索引擎
AI幻覺的例子
AI幻覺有一些最著名的例子和事件,你絕對不能錯過。以下是一些臭名昭著的AI幻覺案例:
- Google的聊天機器人Bard錯誤地聲稱詹姆斯·韋伯太空望遠鏡拍攝了世界上第一張不屬於我們太陽系的系外行星的圖像。
- Meta在2022年為學生和科學研究人員設計的Galactica LLM演示,在提示用戶起草一篇關於創建頭像的論文時,向用戶提供了不準確的資訊和虛假的研究內容。
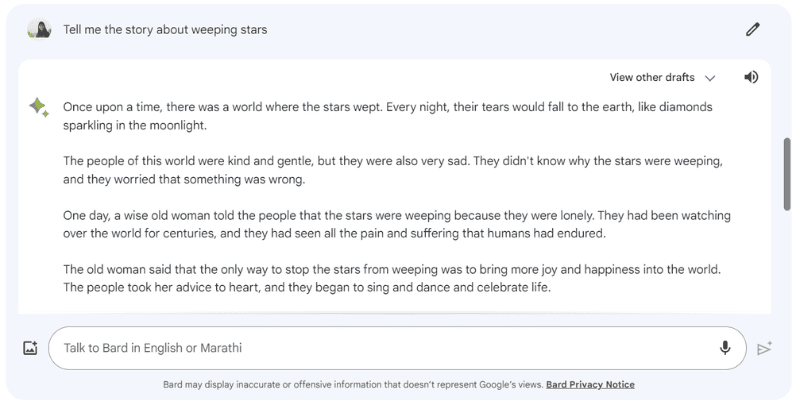
這是一個例子,當我給Google Bard提示「告訴我關於哭泣的星星的故事」時,它會產生幻覺,但實際上並不存這種事情。
這是另一個經過測試的ChatGPT (GPT-3.5)的例子,當我給它提示時,透過談論一個不真實存在的人Ben先生而產生幻覺,「告訴我一個超級英雄Ben先生生活中的一天,他走在水面上、與狗說話、控制生命。」

ChatGPT實際上描述了Ben先生從早到晚的一整天例行公事,而Ben先生實際上並不存在,這是AI產生幻覺的原因之一,因為它按照輸入的提示編造了故事。
真是有夠誇張的!
好了,到底是什麼原因呢?我們再來看看幾個導致AI產生幻覺的原因。
為什麼AI會產生幻覺?

AI幻覺背後有多種技術原因和潛在因素。以下是一些可能的原因:
- 數據品質低劣、不足或過時:大型語言模型和AI模型嚴重依賴訓練數據。因此,它們的品質取決於它們所訓練的數據。如果AI工具的訓練數據存在錯誤、不一致、偏見或效率低下,或者它根本不理解所提出的提示,就會產生AI幻覺,因為該工具從有限的數據集生成輸出。
- 過度擬合:在有限的數據集上進行訓練後,AI模型可能會嘗試記住提示和相應的輸出,使其無法有效地生成或總結新數據,從而導致AI幻覺。
- 輸入情境:AI幻覺也可能由於不明確、不準確、不一致或矛盾的提示而發生。雖然AI模型的訓練數據集不在用戶手中,但他們作為提示的輸入卻掌握在使用者手中。因此,提供清晰的提示以避免AI幻覺至關重要。
- 使用成語或俚語:如果提示由成語或俚語組成,AI產生幻覺的可能性很高,特別是如果模型沒有針對此類單詞或俚語進行訓練。
- 對抗性攻擊:攻擊者有時會故意輸入旨在混淆AI模型的提示,破壞其訓練數據並導致AI幻覺。
AI幻覺的負面影響
AI幻覺是一個主要的道德問題,會對個人和組織產生重大影響。以下是導致AI幻覺成為主要問題的幾個原因:

- 錯誤資訊的傳播:由於錯誤提示或訓練數據不一致而導致的AI幻覺可能會導致錯誤資訊的大規模傳播,影響廣泛的個人、組織和政府機構。
- 使用者之間的不信任:當AI幻覺的錯誤資訊在網路上像野火一樣傳播,看起來很權威、像是人工撰寫時,會侵蝕使用者的信任——使得用戶難以信任網路上的資訊。
- 對使用者的傷害:除了道德問題和誤導個人之外,AI幻覺還可能透過傳播關於一些嚴肅問題和主題的錯誤資訊來傷害人類,例如疾病、治療方法或區分致命毒蘑菇和健康食用蘑菇的簡單技巧。即使是輕微的錯誤資訊或不準確也可能危及人的生命。
發現和預防AI幻覺的最佳做法
考慮到AI幻覺的上述負面影響,不惜一切代價預防它們至關重要。雖然擁有這些AI模型的公司正在努力消除或減少AI幻覺,但作為用戶,我們採取最嚴格的措施非常重要。
根據一些研究、我的經驗以及反覆試驗,我整理了一些策略,以便在您下次使用聊天機器人或與大型語言模型(LLM)互動時,發現並防止AI幻覺。
#1. 使用具有代表性和多樣化的訓練數據
作為用戶,使用具有代表現實世界的多樣化訓練數據集的大型語言模型至關重要,這可以減少輸出有偏見、不準確或捏造的可能性。
與此同時,公司所有者必須確保定期更新和擴展AI模型的訓練數據集,以考慮並更新文化、政治和其他不斷發展的事件。
#2. 限制結果或反應
作為使用者,你可以透過向AI工具提供關於你想要的響應類型的特定提示,來限制AI工具可能產生的潛在響應數量。
例如,你可以明確地詢問並命令模型僅回答「是」或「否」。或者,你也可以在提示中提供多個選項供工具選擇,限制其偏離實際答案和產生幻覺的可能性。
當我向ChatGPT GPT 3.5詢問是或否的問題時,它準確地生成了以下輸出:

#3. 使用相關數據包裝和提升模型
在沒有先驗知識或提供特定背景的情況下,你不能期望人類為任何特定問題或困境提供解決方案。同樣,AI模型的好壞取決於你輸入的訓練數據集。

將AI模型的訓練數據與相關且產業特定的數據和資訊結合,為模型提供了額外的背景和數據點。這些額外的背景有助於AI模型增強理解能力,使其能夠生成準確、合理且符合情境的答案,而不是產生幻覺的回應。
#4. 建立供AI模型遵循的數據範本
以預定義格式提供數據範本,或提供特定公式或計算範例,可以在很大程度上幫助AI模型產生準確的回應,並與規定的準則保持一致。
依靠準則和數據範本可以減少AI模型產生幻覺的可能性,並確保生成回應的一致性和準確性。因此,以表格或範例的形式提供參考模型,可以有效地指導AI模型進行計算,從而消除幻覺發生的情況。
#5. 透過為模型分配特定角色,讓提示盡可能明確
為AI模型分配特定的角色是防止幻覺最聰明、最有效的方法之一。例如,你可以提供諸如「你是一位經驗豐富且技術精湛的吉他手」或「你是一位出色的數學家」之類的提示,然後再提出你的特定問題。
分配角色引導模型提供你想要的答案,而不是虛構的幻覺答案。
別擔心,你仍然可以享受AI帶來的樂趣(不用擔心幻覺)。看看如何自己創作爆紅的AI螺旋藝術!
#6. 使用溫度參數來測試
溫度參數在決定AI模型可以產生幻覺或創造性回應的程度上,扮演著至關重要的角色。
雖然較低的溫度通常意味著確定性或可預測的輸出,但較高的溫度意味著AI模型更有可能生成隨機回應和幻覺。
一些AI公司在其工具中提供「溫度」欄或滑桿,供用戶根據自己的喜好調整溫度設定。
同時,公司還可以設定預設溫度,使該工具能夠產生合理的回應,並在準確性和創造力之間取得適當的平衡。
#7. 務必進行驗證
最後,100%依賴AI產生的輸出而不進行覆核或事實查核並非明智之舉。
雖然AI公司和研究人員正在解決幻覺問題並開發防止此問題的模型,但作為用戶,在使用或完全相信AI模型生成的答案之前,驗證其準確性至關重要。
因此,除了使用上述最佳做法之外,從起草帶有規範的提示到在提示中新增範例來指導AI,你必須始終驗證並交叉檢查AI模型產生的輸出。
你能夠徹底修復或消除AI幻覺嗎?專家的看法
雖然控制AI幻覺取決於我們提供的提示,但有時,模型生成的輸出是如此自信,以至於很難分辨真假。
那麼,最終是否有可能完全修復或預防AI幻覺呢?
當被問到這個問題時,布朗大學教授Suresh Venkatasubramanian回答說,AI幻覺是否可以預防是「積極研究的一個重點」。
他進一步解釋說,這背後的原因是這些AI模型的本質——這些AI模型是多麼複雜和脆弱。即使提示輸入的微小變化也會顯著改變輸出。
雖然Venkatasubramanian認為解決AI幻覺問題是一個研究重點,但華盛頓大學教授、知情公眾中心聯合創始人Jevin West認為AI幻覺永遠不會消失。
West認為,不可能對AI機器人或聊天機器人產生的幻覺進行逆向工程。因此,AI幻覺可能作為AI的固有特徵始終存在。
此外,Google執行長Sundar Pichai在一份哥倫比亞廣播公司採訪中表示,每個使用AI的人都會面臨幻覺,但業界還沒有人解決幻覺問題。幾乎所有的AI模型都面臨這個問題。他進一步聲稱並保證,在克服AI幻覺方面,AI領域很快就會取得進展。
與此同時,ChatGPT製造商OpenAI的執行長Sam Altman於2023年6月訪問了位於德里的印度Indraprastha信息技術學院,他在那裡表示,AI幻覺問題將在一年半到兩年內得到更好的解決。

他進一步補充說,該模型需要學習準確性和創造力之間的區別,以及何時使用其中之一。
總結
近年來,AI幻覺引起了相當多的關注,也是企業和研究人員試圖盡早解決和克服的重點領域。
儘管AI取得了顯著的進步,但它也不能避免錯誤,AI幻覺的問題給一些個人和產業帶來了重大挑戰,包括醫療保健、內容生成和汽車產業。
在研究人員盡自己的一份力量的同時,作為使用者,我們也有責任提供明確而準確的提示、新增範例並提供數據範本,以利用有效且明智的回應,避免混亂AI模型的訓練數據並防止出現幻覺。
即使AI幻覺是否可以完全治癒或修復仍然是一個問題;我個人相信這是充滿希望的,我們可以繼續以負責任和安全的方式使用AI系統來造福世界。
接下來是我們日常生活中AI的範例。