探索大数据分析中的 Apache Hive 与 Impala
在大数据分析领域,您可能会遇到众多 Apache 工具,这些工具种类繁多,有时会让新手感到困惑甚至不知所措。本文旨在澄清这种困惑,深入探讨 Apache Hive 和 Impala 这两个关键工具,并阐明它们之间的主要区别。
什么是 Apache Hive?
Apache Hive 是构建在 Apache Hadoop 平台之上的 SQL 数据访问接口。它允许用户使用类似 SQL 的语言来查询、聚合和分析存储在 Hadoop 分布式文件系统 (HDFS) 中的数据。您可以像操作普通数据库表一样处理这些数据。
Hive 的查询语言 HiveQL 基于 SQL,但并非完全符合 SQL-92 标准。然而,它提供了强大的扩展性,允许用户使用自定义的标量函数(UDF)、聚合函数(UDAF)和表函数(UDTF)来增强其功能。
Apache Hive 的工作原理
Hive 将 HiveQL 查询转化为 MapReduce、Apache Tez 或 Apache Spark 任务,这些任务在 Hadoop 集群上执行。Hive 将数据组织成 HDFS 文件数组,以便分布式处理。Hive 表的数据组织结构类似于关系数据库,从最重要的单元到最细粒度的单元层层递进,例如数据库由分区组成,分区又可以进一步分解为“桶”。
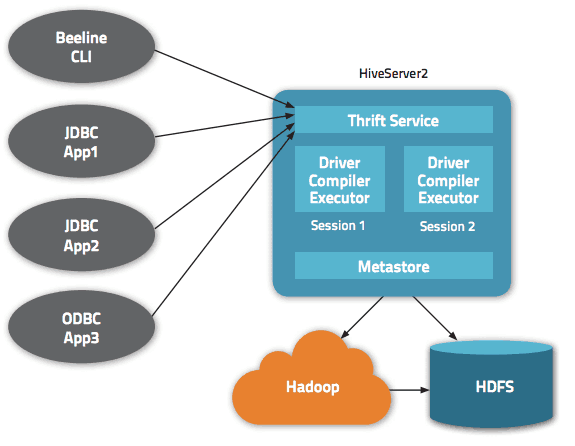
Hive 提供多种接口,如 Web 界面、命令行界面 (CLI) 和外部客户端。Apache Hive Thrift 服务器允许远程客户端通过各种编程语言向 Hive 提交命令和请求。Hive 的元数据信息存储在中央目录中。驱动程序负责执行查询,包含编译器和优化器,以确定最佳的执行计划。
Hive 的安全性由 Hadoop 提供,依赖 Kerberos 进行客户端和服务器之间的身份验证。新创建文件的权限由 HDFS 规则确定。
Hive 的主要特点
- 支持 Hadoop 和 Spark 计算引擎
- 使用 HDFS 作为数据仓库
- 使用 MapReduce 并支持 ETL(提取、转换、加载)
- 由于 HDFS 的特性,具有类似 Hadoop 的容错能力
Hive 的优势
Hive 是查询和数据分析的理想选择,有助于获得有价值的见解,从而在竞争中占据优势并快速响应市场需求。其主要优势包括:
- 易于使用: 类似 SQL 的语言降低了学习曲线。
- 快速数据加载: 数据可以快速插入,无需转换为内部数据库格式。
- 可扩展性: 可以存储高达数百 PB 的数据集。
- 弹性: 云服务允许用户根据工作负载快速启动虚拟服务器。
- 安全性: 具有在出现问题时复制工作负载的能力。
- 高吞吐量: 每小时可执行高达 10 万个请求。
什么是 Apache Impala?
Apache Impala 是一个大规模并行 SQL 查询引擎,用于交互式查询存储在 Apache Hadoop 中的数据。它使用 C++ 编写,并在 Apache 2.0 许可下分发,常被称为 MPP 引擎、分布式 DBMS 或 Hadoop 上的 SQL 数据库。

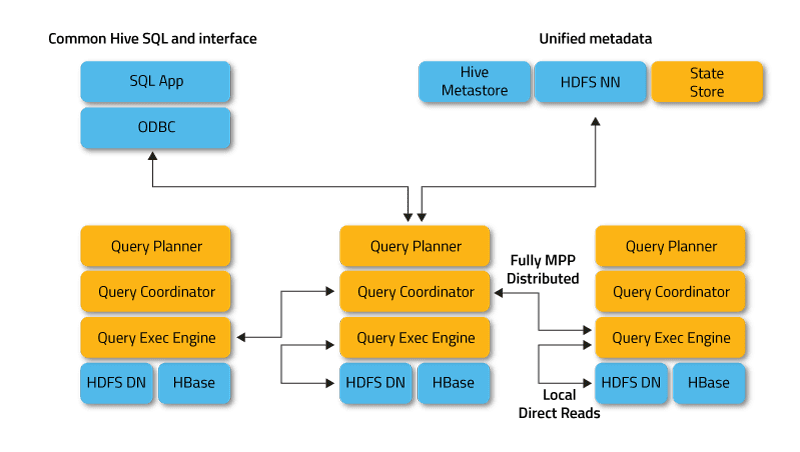
Impala 以分布式模式运行,在不同的集群节点上处理请求,客户端可以提交 SQL 查询以访问存储在 HDFS、HBase 或 Amazon S3 中的数据。Impala 通过 HUE Web 界面、ODBC、JDBC 和 Impala Shell 命令行 shell 进行交互。Impala 依赖于 Hive 的元数据存储,了解数据库的可用性和结构。
Impala 的关键组件包括:
- Impalad: 在每个集群节点上运行的守护进程,负责调度和执行查询。
- Statestore: 跟踪集群中所有 impalad 实例的位置和状态。
- Catalog: 元数据协调服务,将 DDL 和 DML 语句的更改传播到所有 impala 节点。
Apache Impala 的工作原理
Impala 使用类似于 HiveQL 的声明式查询语言,该语言是 SQL92 的一个子集。客户端通过 ODBC 或 JDBC 驱动连接到任何 impalad 实例以发送 SQL 查询,连接的 impalad 成为当前请求的协调器。Impala 分析查询,确定集群中 impalad 实例的任务,并生成最佳的执行计划。Impalad 直接访问 HDFS 和 HBase 以提供数据,节省了查询执行时间,因为它不保存中间结果。
Impala 的主要特点
- 支持实时内存处理
- SQL 友好
- 支持 HDFS、Apache HBase 和 Amazon S3 等存储系统
- 支持与 Pentaho、Tableau 等 BI 工具集成
- 使用 HiveQL 语法
Impala 的优势
- 速度: 由于启动时直接启动守护进程,避免了启动开销。
- 直接访问: 不存储中间结果,直接访问 HDFS 或 HBase。
- 运行时代码生成: 在运行时生成程序代码,而不是像 Hive 那样在编译时生成。
- 内置支持: 支持 Kerberos、优先级排序、管理请求队列以及各种大数据格式。
Hive 与 Impala 的相似之处
Hive 和 Impala 都是在 Apache Software Foundation 许可下免费分发的 SQL 工具,用于处理存储在 Hadoop 集群中的数据。它们都使用 HDFS 分布式文件系统。Impala 可以读取和写入 Hive 表,从而实现轻松的数据交换。Impala 旨在快速高效地执行 Hadoop 上的 SQL 操作,常用于大数据分析研究项目。两者都将表定义存储在 Metastore 中,并且 Impala 可以访问 Hive 表,前提是所有列都使用支持的数据类型。
Hive 与 Impala 的差异

| 编程语言 | Hive 使用 Java 编写,Impala 使用 C++ 编写 |
| 用例 | Hive 用于 ETL 过程,Impala 主要用于商业智能 |
| 性能 | Impala 执行速度快,Hive 数据处理速度慢 |
| 延迟/吞吐量 | Hive 吞吐量高,Impala 延迟低 |
| 容错性 | Hive 容错性高,Impala 容错性低 |
| 代码转换 | Hive 编译时生成查询表达式,Impala 运行时生成 |
| 存储支持 | Hive 支持纯文本和 ORC,Impala 支持 LZO、Avro 和 Parquet |
总结
Hive 和 Impala 并非相互竞争,而是有效互补。选择使用哪个工具取决于项目的具体数据和需求。您也可以进一步探索 Hadoop 和 Spark 之间的比较。