Data Lakehouse 是一种新兴的数据管理架构,它结合了数据湖和数据仓库的最佳部分。 使用数据湖屋,您能够在单个平台中存储不同类型的数据并执行符合 ACID 的查询和分析。
那么,为什么要使用数据湖屋呢? 作为一名高级软件工程师,我可以理解当您必须管理和维护两个独立的系统并且有大量数据从一个系统传输到另一个系统时会变得多么困难。
如果您想使用数据来运行业务分析和生成报告,则需要将结构化数据存储在数据仓库中。 另一方面,要以原始格式存储来自各种数据源的所有数据,您需要一个数据湖。 拥有一个湖屋就消除了维护不同系统的需要,因为它带来了两全其美的效果。
Data Lakehouse的意义

为了发展您的组织和业务,您需要能够存储和分析数据,无论其格式或结构如何。 数据湖屋对于现代数据管理非常重要,因为它们解决了数据湖和数据仓库的局限性。
您的数据湖通常会变成数据沼泽,数据在没有任何结构或治理的情况下被转储。 这使得查找和使用数据变得困难,并且还可能导致数据质量问题。 另一方面,拥有数据仓库往往会导致你过于僵化。 它也变得昂贵。
数据湖屋有其自己的一套特征。 让我们来看看它们。
数据湖屋的特征
在深入了解数据湖屋架构之前,让我们先了解一下数据湖屋最重要的功能或特征。
数据湖屋架构
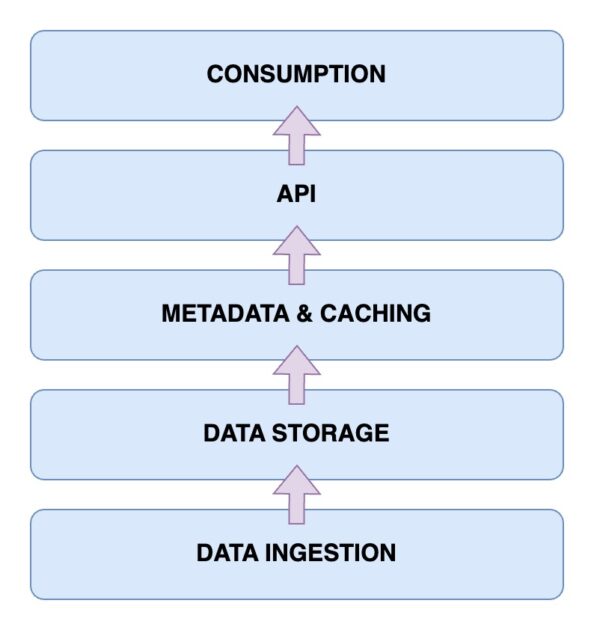
现在,是时候看看数据湖屋的架构了。 了解数据湖屋架构是了解其工作原理的关键。 Data Lakehouse 架构主要有五个主要组件。 让我们一一看看。
数据摄取层
这是捕获各种格式的所有不同数据的层。 这些可能是主数据库中的数据更改、来自各种物联网传感器的数据或流经数据流的实时用户数据。
数据存储层
从各种来源获取数据后,就可以将它们存储为适当的格式。 这就是存储层发挥作用的地方。数据可以存储在各种介质中,例如 AWS S3。 实际上,这是您的数据湖。
元数据和缓存层
现在您已经有了数据存储层,您需要元数据和数据管理层。 这提供了数据湖中所有数据的统一视图。 这也是向现有数据湖添加 ACID 事务以将其转变为数据湖屋的层。
API层
您可以使用 API 层从元数据层访问索引数据。 它们可以采用数据库驱动程序的形式,让您可以通过代码运行查询。 或者,这些可以以可以从任何客户端访问的端点的形式公开。
数据消费层
该层包含分析和商业智能工具,它们是数据湖站数据的主要用户。 您可以在此处运行机器学习程序,从您存储和索引的数据中获得有价值的见解。
现在,您已经对湖屋建筑有了清晰的了解。 但如何构建一个呢?
构建数据湖屋的步骤
让我们看看如何构建自己的数据湖屋。 无论您拥有现有的数据湖或仓库,还是从头开始构建 Lakehouse,步骤都保持相似。
接下来,让我们看看如果您有现有的数据管理解决方案,如何迁移到数据湖屋。
迁移到 Data Lakehouse 的步骤
当您将数据工作负载迁移到 data Lakehouse 解决方案时,您应该牢记某些步骤。 制定行动计划可以让您避免最后一刻出现问题。
第 1 步:分析数据
任何成功迁移的第一步也是最关键的步骤之一是数据分析。 通过适当的分析,您可以定义迁移的范围。 此外,它还可以让您识别您可能拥有的所有其他依赖项。 现在,您可以更全面地了解您的环境以及要迁移的内容。 这使您能够更好地确定任务的优先级。
步骤 2:准备迁移数据
成功迁移的下一步是数据准备。 这包括您将要迁移的数据,以及您将需要的支持数据框架。 与其盲目地等待所有数据在 Lakehouse 中可用,不如了解您实际需要的数据集和列可以节省宝贵的时间和资源。
步骤 3:将数据转换为所需格式
您可以利用自动转换。 事实上,您应该尽可能选择自动转换工具。 迁移到 data Lakehouse 时的数据转换可能很棘手。 幸运的是,大多数工具都带有易于阅读的 SQL 代码或低代码解决方案。 类似的工具 炼金术士 帮忙解决这个问题。
步骤 4:迁移后验证数据
迁移完成后,就可以验证数据了。 在这里,您应该尝试尽可能自动化验证过程。 否则,手动迁移会变得乏味并减慢您的速度。 它只能作为最后的手段使用。 验证您的业务流程和数据作业在迁移后是否不受影响非常重要。
数据湖屋的主要特点
🔷 完整的数据管理 – 您获得的数据管理功能可帮助您充分利用数据。 其中包括数据清理、ETL 或提取-转换-加载过程以及模式实施。 因此,您可以轻松清理和准备数据以供进一步分析和 BI(商业智能)工具使用。
🔷 开放存储格式 – 保存数据的存储格式是开放且标准化的。 这意味着您从不同数据源收集的数据都以类似方式存储,您可以从一开始就使用它们。 它支持 AVRO、ORC 或 Parquet 等格式。 此外,它们还支持表格数据格式。
🔷 存储分离——您可以将存储与计算资源分离。 这是通过为两者使用单独的集群来实现的。 因此,您可以根据需要单独扩展存储,而不必对计算资源进行任何不必要的更改。
🔷 数据流支持 – 做出数据驱动的决策通常涉及使用实时数据流。 与标准数据仓库相比,数据湖屋为您提供实时数据摄取的支持。
🔷数据治理——它支持强有力的治理。 此外,您还可以获得审核功能。 这些对于维护数据完整性尤其重要。
🔷降低数据成本——运行数据湖房的运营成本相对低于数据仓库。 您可以以更低的价格获得云对象存储来满足您不断增长的数据需求。 此外,您还可以获得混合架构。 因此,您无需维护多个数据存储系统。
数据湖、数据仓库、数据湖屋
功能数据湖数据仓库数据湖屋数据存储存储原始或非结构化数据存储经过处理和结构化的数据存储原始数据和结构化数据数据模式没有固定模式有固定模式使用开源模式进行集成数据转换数据不转换需要广泛的 ETL 根据需要进行 ETL 符合 ACID 没有符合 ACID – 符合ACID标准查询性能通常较慢,因为数据是非结构化的,由于结构化数据,速度很快,由于半结构化数据,速度快,存储具有成本效益,存储和查询成本较高,存储和查询成本平衡,数据治理需要仔细治理,需要强有力的治理,支持治理措施实时分析有限实时分析有限实时时间分析支持实时分析用例数据存储、探索、ML和AI使用BI进行报告和分析机器学习和分析
结论
通过无缝结合数据湖和数据仓库的优势,数据湖屋解决了您在管理和分析数据时可能面临的重要挑战。
现在您已经了解了湖屋的特点和建筑。 数据湖站的重要性显而易见,因为它能够处理结构化和非结构化数据,为存储、查询和分析提供统一的平台。 此外,您还可以获得 ACID 合规性。
通过本文中提到的有关构建和迁移到数据湖屋的步骤,您可以释放统一且经济高效的数据管理平台的优势。 保持现代数据管理格局的领先地位,推动数据驱动的决策、分析和业务增长。
接下来,请查看我们有关数据复制的详细文章。