Google Search Console(简称 GSC)是 SEO 专家手中一款强大的分析工具,用于解读网站的性能数据。
正则表达式(REGEX)的引入,增强了从内容中获取有价值信息的能力,同时也激发了新的内容创作灵感。
REGEX 功能在网络分析领域备受期待。 它允许过滤来自任何 URL 的特定元素,而这些元素在过去是难以或不可能实现的。
本文将重点介绍在 Google Search Console 中使用 REGEX 的实用技巧和方法。 您还将学习如何结合不同的 REGEX 运算符,以获得所需的分析结果。
REGEX 或正则表达式: 简述
Google Search Console 是一项完全免费的服务,专为网站管理员设计,旨在帮助他们管理网站性能。它提供关于网站点击率、展示次数、点击量以及关键词排名的详细报告,这些报告可用于衡量 SEO 活动的有效性。
然而,在过滤 URL 方面,GSC 存在一定的局限性。 GSC 允许导出最多 1000 行数据进行分析。 它只能过滤 URL 的特定部分,例如路径、域名属性或前缀,而无法处理复杂的字符串和变体。
正则表达式(Regex)是 GSC 的一个强大补充。 其目的是为 SEO 专业人员提供一个系统,使他们能够使用 GSC 来更深入地了解网站的运作和表现。
通过在页面或查询过滤器上应用正则表达式代码,可以查找网站的关键 SEO 信息。 这些代码由元字符组成,其中包含与过滤参数相关的字符串。 当您在面板中输入正则表达式时,它会显示结果,您可以保存这些结果以备将来参考。
在 GSC 上使用正则表达式的优势
使用 Google Search Console 的主要目的是从技术层面分析网站。 SEO 团队会使用许多工具和技术来制定优化策略,从而提高网站在搜索引擎中的排名并带来流量。
正则表达式通过简化收集有用数据的过程,提供了额外的优势,这些数据可以进一步用于制定有针对性的优化计划。 您可以通过正则表达式报告来解读以下信息。
✨ 通过在查询中使用正则表达式代码,您可以了解特定关键词/短语的搜索量。 这将帮助您为博客产生新的内容创意,并获得更多流量。
✨ 正则表达式代码为处理大量网络数据的大型公司中的 SEO 人员节省了大量时间。 只需使用正确语法中的几个元字符和字符串,即可根据特定要求对查询或页面进行排序。
✨ 其主要优势之一在于能够处理单词、句子和 URL 的各种组合。 这些字符必须按照正确的顺序放置,才能形成有效的正则表达式代码。
✨ 毫无疑问,它可以帮助您更深入地了解您的网站,包括表现良好和表现不佳的页面以及趋势。
✨ 您可以在自定义报告中应用正则表达式代码,以跟踪特定查询页面上的流量。 之后,您可以指导团队在特定方向上开展工作。
您可以设置多种正则表达式字符组合来定义代码,并使用它们来解释如何优化网站。
在 Google Search Console 上哪里应用正则表达式?
要在 GSC 上使用正则表达式功能,您首先需要获得网站的所有权。 这是一个强制条件,因为您无法在 Google Search Console 上附加不属于您的网站进行任何分析。
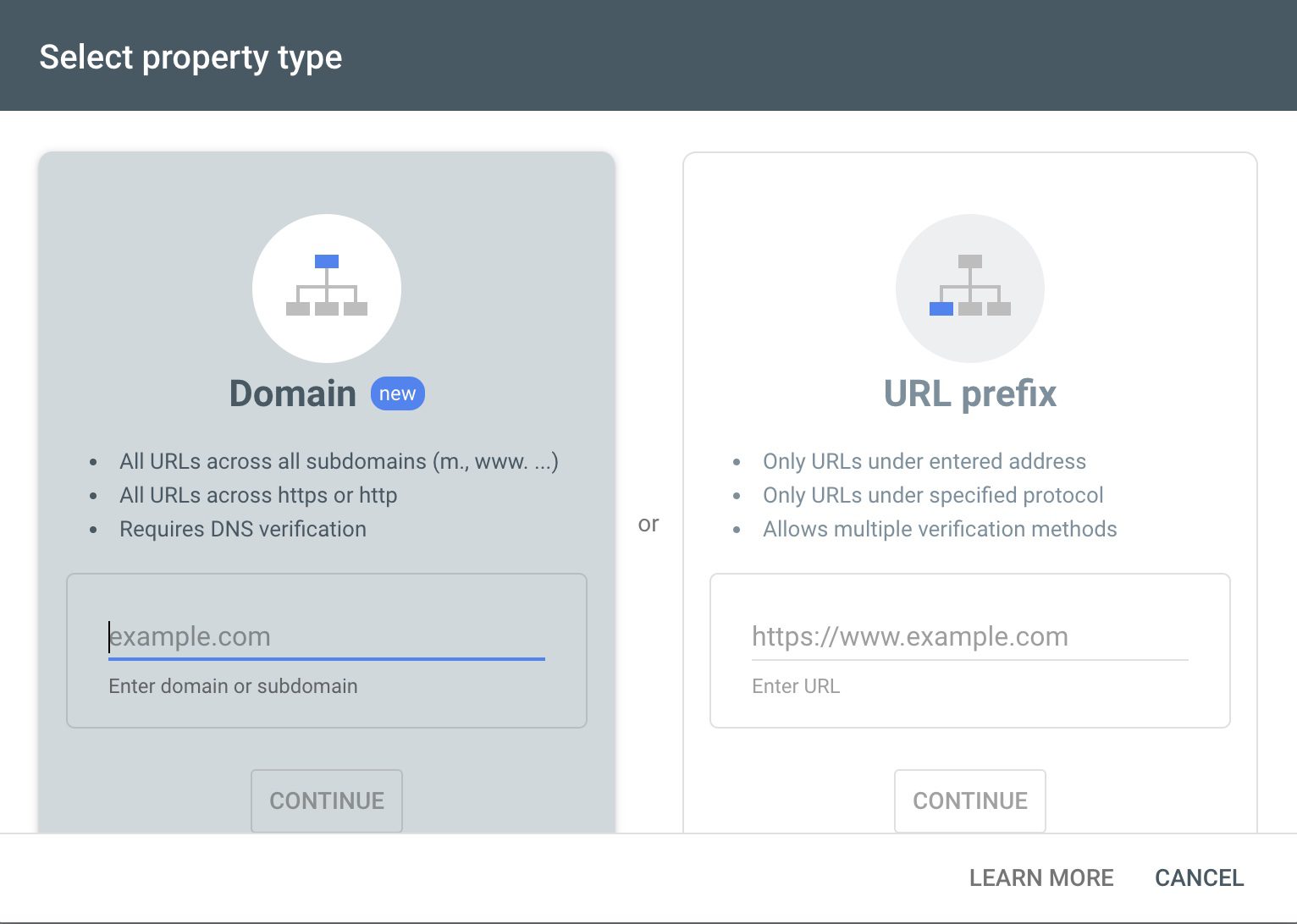
您需要使用 Gmail ID 登录 Google Search Console,然后从侧边栏的选项中添加属性。 属性是您拥有或有权在控制台中访问的网站。
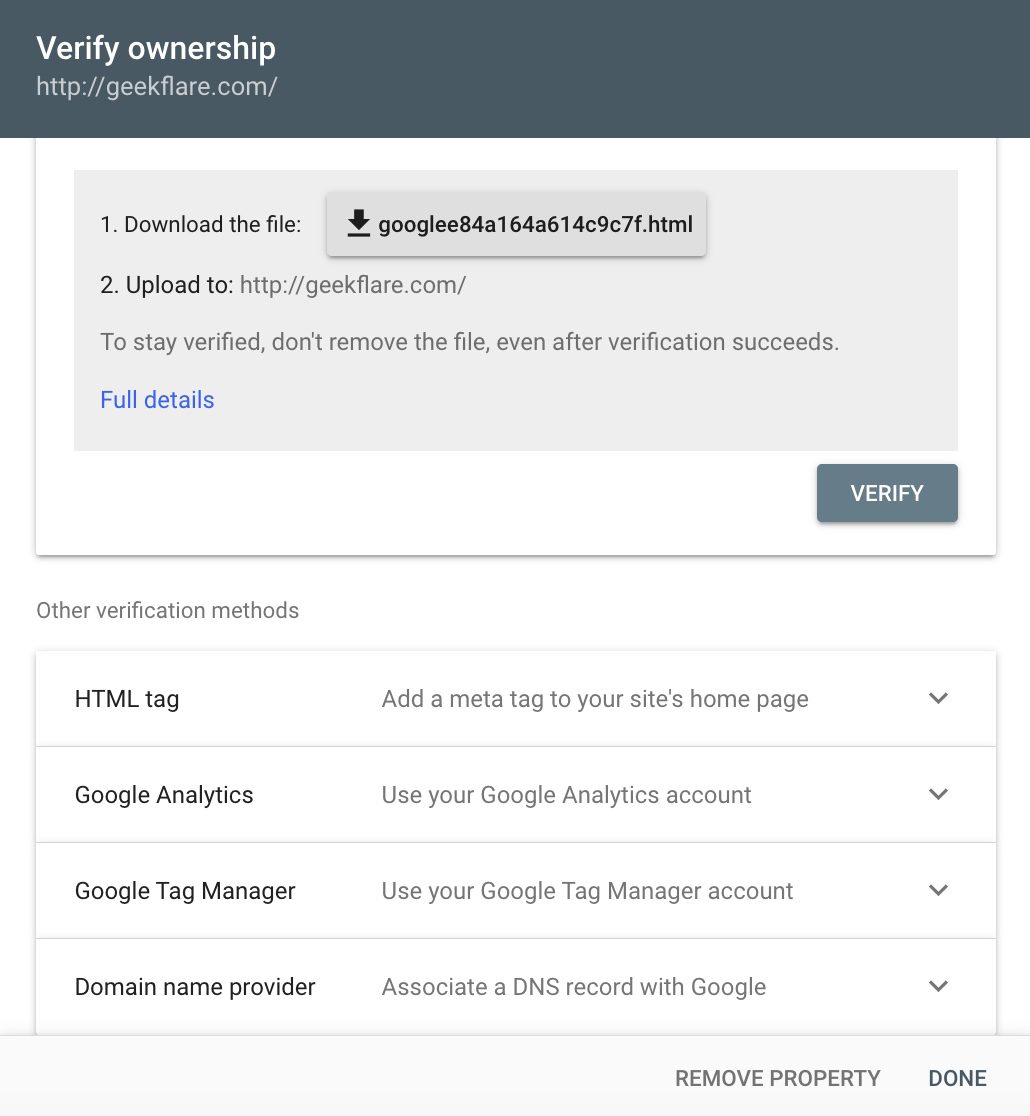
添加网站或任何 URL 后,面板会要求您进行验证✅。 验证程序会显示在该栏中,完成验证后,您可以选择您的属性进行进一步操作。
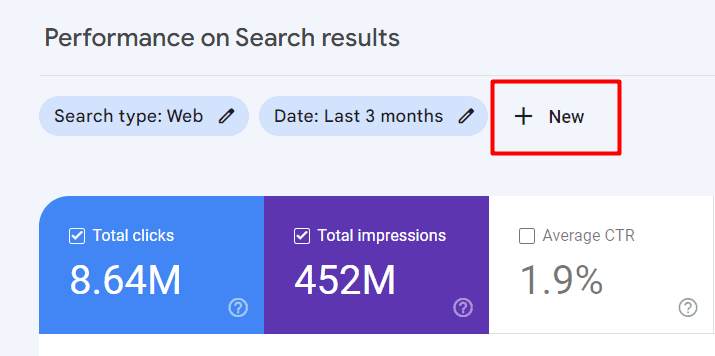
在列出的属性名称下,单击“效果”参数,然后单击图表上方的“新建”按钮以获取过滤选项。
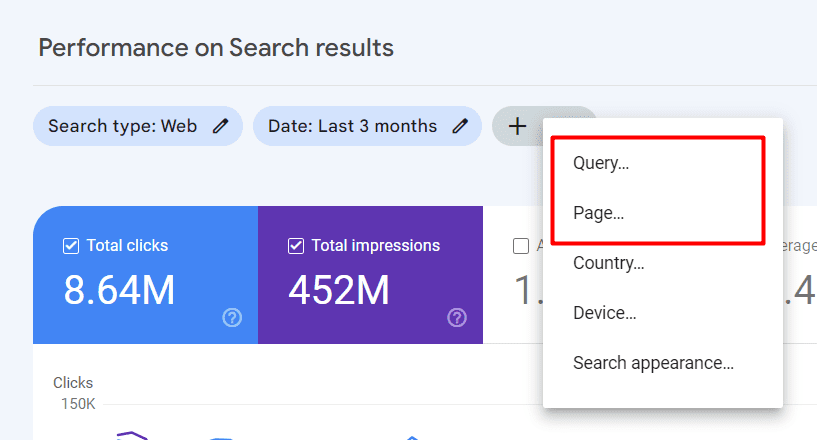
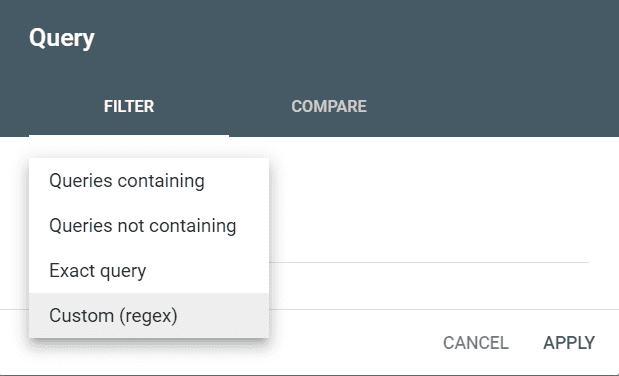
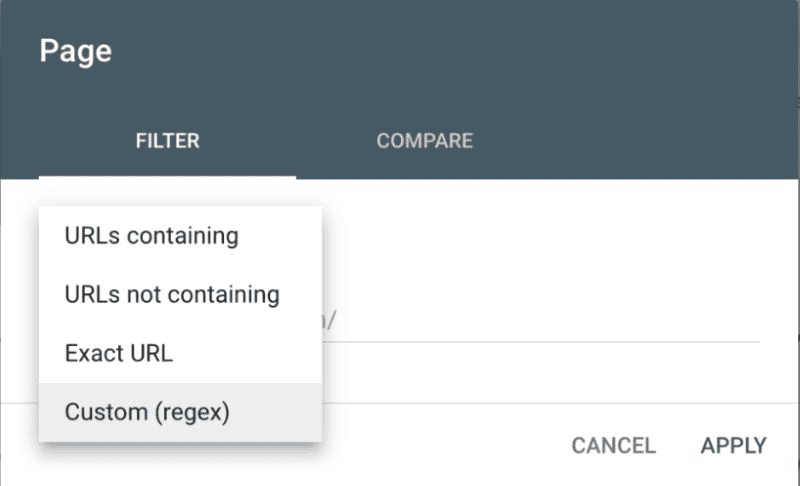
您可以选择“查询”或“页面”来使用正则表达式代码过滤结果。
解释正则表达式字符
在 Google Search Console 上过滤查询和页面时,可以使用多种字符作为正则表达式。 每个元字符在过滤器中代表不同的含义。 如果您能理解它们,那么使用 Regex 在 GSC 中进行分析将变得非常简单。
在下图中,我通过合适的例子解释了正则表达式代码中使用的一些符号和字符。
| 字符 | 用法 |
| () | 这些括号用于对字符或表达式进行分组,也称为捕获组。 例如, (极客)。 您将获得所有标题或标签开头带有 “极客” 一词的网页。 |
| [^\mobile] | 如果脱字符号后跟着反斜杠,它将过滤带有给定单词 “mobile” 的 URL。 |
| | | 这是一个 OR 符号,仅用于应用代码中的选择。例如,移动|PC 报告将获取包含这两个单词中任意一个的所有页面。 |
| ^ | 插入符号仅匹配字符串开头的单词或短语。例如,^Mobile 您将获得标题或标签开头带有单词 “Mobile” 的所有网页。 |
| $ | 美元符号只会匹配字符串末尾的单词或短语。例如,Mobile$您将获得标题或标签末尾带有单词 “Mobile” 的所有网页。 |
| . | 句点符号用于匹配字符串中的任何单个字符。 |
| \ | 反斜杠用于跳过字符的字面含义。 例如,\d 将匹配数字 0-9 的页面。 |
| [xyz] | 此正则表达式代码将使用括号中的一个或所有这些字符来匹配查询;x、y 或 z。例如, 移动[xyz] 该代码将匹配包含 mobile 与 x、y 或 z 组合的所有单词的页面,如 mobilex、mobilezy 和 mobilezxy。 |
| [c-m] | 此正则表达式代码将与 c 和 m 之间的任何小写或大写字母的查询相匹配。例如, Mobile[c-m]该代码将匹配包含 mobile 与 c 和 m 之间字母组合的所有单词的页面;例如,mobilecjg、mobileeel、mobilecdf。 |
| [3-7] | 此正则表达式代码将与数字在 3 到 7 之间的查询相匹配。 例如,Mobile[0-9] 该代码将匹配所有单词由 mobile 与 3 到 7 之间的数字组合而成的页面;例如,mobile73、mobile654、mobile445。 |
| [\w] | 这将匹配网页上带有字母 “to” 的每个单词,例如 wards、into、to。 例如,[\w]*移动的[\w] |
| [\w] | 反斜杠后跟括号内的小写字母 “w”。这将匹配任何单词或字符,例如字母(小写和大写)、数字或下划线。 |
| [\W] | 此正则表达式代码会将包含 “mobile” 一词的页面与其他单词匹配,无论是在标题、元还是文章中,例如 mobilephone、mobileapp。 例如,[\W]*移动的[\W] |
| [\W] | 反斜杠后跟括号内的大写字母 “W”。这将匹配除字母或数字以外的所有内容。 它表示空白字符和符号,例如;?:#@$%。 |
您可以使用这些字符创建多个代码来过滤 GSC 上的复杂查询。
Google Search Console 上的特定正则表达式
您可以使用 Google Search Console 上的元字符来创建独特的模式或代码以实现特定目标。 以下是一些示例,您可以在 GSC 门户上尝试。
🔶^[\w\W\s\S]{70,}$
此代码将匹配页面上的所有单词、数字、非单词或特殊字符、符号、空格以及非空白或换行符。而量词“70”表示字符串很长,或者至少有 70 个字符。
示例:此类代码适用于验证密码、对具有详细描述的产品列表进行排序或其他场景。
🔶 (\w+\s){6,}\w+
此正则表达式代码分为三个部分。 它的目的是匹配单词和数字之间的空格。 因此,该代码将获取至少 6 个单词或更长的字符串,例如:“这是一个至少有 6 个单词或更长的字符串”。
示例:这些代码适用于过滤标题较长、社交媒体评论等较长的文本。
🔶 ^(谁|什么|哪里|何时|为什么|如何)[“ “]
这个正则表达式代码非常简单,对博主和 SEO 专家都很有用。 它会匹配搜索引擎上以 “谁”、“什么”、“哪里”、“何时”、“为什么” 或 “如何” 开头的所有查询。 该字符串必须以这些单词中的任何一个开头,后跟一个空格。 因此,它不会获取 “然而”、“整体” 等词语。
示例:这些代码适合了解市场趋势和用户讨论,从而获得新的内容创意。
🔶 “谁|什么|哪里|何时|为什么|如何”
它类似于上述正则表达式代码,但在此函数中,将匹配包含这些单词的任何字符串,无论该字符串是否以这些单词开头。
示例:此代码适用于突出显示有问题的语句、过滤用户输入等。
🔶 .*
元字符句点后跟星号通常称为通配符表达式,因为您可以通过将其放在此代码下使用它来匹配任何特定字符串。
示例:正则表达式 .*Android.* 将获取您的资源上包含 “Android” 一词的所有页面。 通过直接在过滤器上使用代码 .*,它将提取一个月内出现在搜索引擎上的所有页面。
🔶 [^\/\.\-:0-9A-Za-z_]
插入符号后跟一个反斜杠,它将排除代码中指示的字符。 在这里,代码将匹配不包含正斜杠、数字、句点、冒号、连字符以及所有大写和小写字母的字符串。
示例:因此,该代码适用于捕获 URL、元描述或包含 &%$@ 等特殊字符的内容。
🔶 ?i)(((is|are).(brand|site|company)|(brand|site|company).(is|are)).*(scum|reliable))
这是一个包含特定部分的长正则表达式代码。 代码开头使用的字符 ?i 用于不区分大小写的标志。 这意味着代码将匹配字符串,无论它们是大写还是小写。 其后的括号包含一些由竖线 (OR) 字符分隔的单词。
正则表达式代码将检测查询,无论隐含字母的大小写,其中包括 “is” 或 “are”、“brand”、“company” 或 “site” 以及 “scum” 或 “reliable”。
示例:可以仔细使用此正则表达式代码来查找客户查询的模式。 您将能够知道您的网站是否有正面或负面评论。
🔶 (kwd1|kwd2).*
它是析取正则表达式代码的简化用法,其中 GSC 将过滤掉单词 kwd1 或 kwd2 后跟任何其他字母或数字的页面或查询。
示例:您可以使用此模式提取网站上的页面,其中这些单词中的任何一个与 URL、标题、元或内容中的其他单词或数字相连接。
🔶 (关键字 1 和关键字 2)
这段代码是一个清晰的连词表达式的例子。“AND” 是正则表达式代码中使用的运算符。 它用于获取具有相同序列的这两个给定单词的页面。
示例:您可以在 GSC 上应用代码来获取具有相同顺序的两个特定单词的页面、标题或元。
🔶 “关键字1关键字2”
该代码适合匹配网页上的短语或单词的确切顺序。
示例:在 GSC 上应用代码来查找标题、描述或包含特定短语的内容的页面。
🔶 (关键字1 | 关键字2)
该代码有两个字和一个管道字符。 它表示 GSC 将显示您网站上包含 “关键字1” 或 “关键字2” 但不能同时包含两者的页面。
示例:应用代码从您的网站中提取包含由竖线字符分隔的两个或多个单词中的任意一个的页面。
🔶 (关键字1)\b(关键字2)\b
该正则表达式代码有两个特定的单词,其中字符 \b 是单词边界的符号。 它将提供包含这两个单词的页面,并且它们之间没有其他单词、数字或字符。
示例:在 GSC 过滤器上使用此代码可了解连续包含两个单独单词的页面。
🔶 (关键字1)\w+(关键字2)
该代码包含两个单词,中间有元字符 \w+,其中 “w” 为小写。 因此,它将获取包含这两个单词的所有页面,无论是在标题、描述还是内容中,无论它们之间的单词数量是多少。
示例:您可以应用此代码来提取网站上标题、内容或元中至少包含这两个单词的所有页面。
🔶 (关键字)\b短语
这是一个简单的正则表达式代码,用于将字符串与括号中的单词以及后跟单词短语进行匹配。 元字符 \b 表示单词边界或给定单词之间没有其他字符。
示例:GSC 上的此正则表达式代码将提供在文章中任何位置串联给定单词的页面,例如 “关键字短语”。
🔶 a-url.|.b-url.|.c-url.|.e-url.|.f-url.|.g-url.|.h-url.|.i-url.|.j -url.|.k-url.|.l-url.|.m-url.|.n-url.|.o-url.|.p-url.|.
此正则表达式代码列出了多个 URL “a,b,c,e,g…..”,并用竖线字符分隔。 因此,它将过滤掉具有这些 URL 之一的字符串。
示例:您可以在 GSC 面板上应用此类模式来获取标题或文章中包含任何特定 URL 的网页。
🔶 ^(苹果|球|猫|鸭场)$
给定的代码意味着将字符串的开头与这些给定单词之一 “apple、ball、cat 或 duck farm” 进行匹配,因为管道字符将它们分开。 同时它也确保没有其他单词或字符。
示例:您可以使用代码来获取开头具有任何特定关键字的页面的详细信息。
🔶 .*\/$
给定的正则表达式代码旨在捕获每个字符串,无论是单词还是数字,但它应该以正斜杠结尾。
示例:您可以使用它来匹配 URL 以正斜杠结尾的页面。
🔶 .(最佳|顶部|对比|评论)。*
此代码将匹配开头有句点的字符串以及给定单词之一(由竖线字符分隔)以及后续的其他单词、数字或特殊字符。
示例:您可以在商业报告中使用正则表达式的此类模式来了解市场趋势。
🔶 (购买|便宜|价格|购买|订单)。
此代码将匹配具有由竖线字符分隔的给定单词之一并后跟其他单词、数字或字符的字符串。
示例:此类代码在匹配与您的网站产品相关的交易搜索或查询时非常有用。
🔶 (脸(b | be)ook)🔶(f(a | e)ce(b | be)ook 🔶(fa(c | s)(e | i)书)
这些代码由括号内的单词以及它们之间的管道字符组成。
第一个正则表达式将匹配包含单词 “face” 后跟 “b” 或 “be” 并以 “ook” 结尾的字符串。 因此,获取的页面将包含 “facebook” 或 “facebeook” 一词。
第二个正则表达式将匹配包含单词 “f”、后跟 “a” 或 “e”、后跟 “ce”、后跟 “b” 或 “be” 并以 “ook” 结尾的字符串。 因此,获取的页面将具有任意一种组合,例如 facebook、fecebook、facebeook 或 fecebeook。
第三个正则表达式将匹配包含单词 “fa”、后跟 “c” 或 “s”、后跟 “e” 或 “I” 并以 “book” 结尾的字符串。 因此,获取的页面将具有任意一种组合,例如 facebook、facibook、fasebook 或 fasibook。
示例:您可以使用此类代码来匹配网页中潜在的拼写错误。
🔶 .wp-.
给定的代码将匹配包含句点、后跟 “wp-”、后跟其他字符的字符串。
示例:适用于提取带有 WordPress URL 的页面。
🔶 .*/url-1/.* 与 .*/url-2/.*
给定的代码有两个不同的 URL,带有比较正则表达式字符。 它将从您的网站获取两个特定的 URL 来比较它们的指标。
示例:您可以应用此代码来比较网站上两个特定网页之间的流量、用户访问量和其他指标。
其他不常见的正则表达式
🔺 (?i)\b关键字\b
此代码将匹配包含 “关键字” 一词的字符串。 搜索与网页中单词的大小写无关。
🔺 “短语”
此代码将简单地匹配其中包含单词短语的页面。
🔺 \w{5}
该代码将匹配具有 5 个单词字符的查询。
🔺 \d{3}
此代码将匹配恰好包含 3 位数字的查询。
🔺 ([^” “]*)
此正则表达式代码将匹配引号中不含任何字符的字符串。
🔺 (?i)\b(关键字1|关键字2|关键字3)\b
此给定代码将匹配具有由竖线字符分隔的任何一个单词且为任意大写或小写的字符串。
🔺 \W+
该代码将匹配任意数量的非单词字符,通常是特殊字符。
🔺 \d{3,5}
该代码将匹配所有包含 3 位数字且最多 5 位数字的字符串。
🔺 \b\w+\b
该代码将匹配任意数量的带有单词边界的单词字符。
结语
在性能过滤器中引入正则表达式代码后,Google 搜索引擎已成为大量信息的来源。 它所需要的只是了解提取分析报告的代码结构。
您可以在面板上创建多个正则表达式代码,以获得有关网站性能的特定详细信息,并使用它们进行优化,以获得更好的结果。
接下来,您可以查看 Google 搜索技巧,帮助您更好地进行在线搜索。