MongoDB 分片技术详解
在分布式计算环境中,分片是一种将庞大的数据集分散存储在多个 MongoDB 实例上的有效方法。它允许我们将大型数据分割成更易于管理的小块。
什么是分片?
MongoDB 的分片机制提供了一种可扩展的解决方案,使我们能够跨多台服务器存储海量数据,而不是局限于单台服务器。随着数据量的快速增长,单机存储变得越来越不可行。对存储在单个服务器上的庞大数据进行查询,可能会导致资源高度占用,并难以保证理想的读写吞吐量。
处理不断增长的数据量,主要有两种扩展方式:
- 垂直扩展:通过升级服务器的硬件配置,例如更强大的处理器、更大容量的内存或更多的磁盘空间,来提升单个服务器的性能。然而,在现实应用中,现有技术和硬件配置的限制可能会影响垂直扩展的效益。
- 水平扩展:通过添加更多服务器,并将负载分散到多个服务器上。每个服务器处理整个数据集的一个子集,这种方式比部署高端硬件更高效、成本效益更高。然而,它也需要对涉及多台服务器的复杂基础设施进行额外的维护。
MongoDB 的分片技术正是基于水平扩展的理念而设计的。
分片的核心组件
要在 MongoDB 中实现分片,需要以下关键组件:
- 分片 (Shard): 这是一个独立的 MongoDB 实例,负责处理原始数据的一个子集。为了确保数据的可靠性,分片通常部署在副本集中。
- Mongos:这是一个充当客户端应用程序和分片集群之间接口的 MongoDB 实例。它的主要作用是作为分片的查询路由器,负责将客户端的请求路由到正确的分片。
- 配置服务器 (Config Server):这是一个存储集群元数据信息和配置细节的 MongoDB 实例。MongoDB 要求配置服务器必须部署为副本集,以保障元数据的可靠性和一致性。
分片架构概览
MongoDB 分片集群由多个副本集构成。每个副本集至少包含 3 个或更多的 MongoDB 实例。一个分片集群可能由多个 MongoDB 分片实例组成,并且每个分片实例都工作在一个分片副本集中。应用程序通过 Mongos 与分片集群交互,而 Mongos 负责与各个分片通信。因此,应用程序在分片架构中不会直接与分片节点交互。查询路由器根据分片键将数据子集分布在不同的分片节点之间。
分片实现的详细步骤
以下是在 MongoDB 中实现分片的详细步骤:
步骤 1
- 在副本集中启动配置服务器,并启用它们之间的复制功能。
mongod –configsvr –port 27019 –replSet rs0 –dbpath C:datadata1 –bind_ip localhost
mongod –configsvr –port 27018 –replSet rs0 –dbpath C:datadata2 –bind_ip localhost
mongod –configsvr –port 27017 –replSet rs0 –dbpath C:datadata3 –bind_ip localhost
步骤 2
- 在其中一台配置服务器上初始化副本集。
rs.initiate({_id:"rs0", configsvr:true, members:[{_id:0, host:"IP:27017"}, {_id:1, host:"IP:27018"}, {_id:2, host:"IP:27019"}]})
{
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(1593569257, 1),
"electionId" : ObjectId("000000000000000000000000")
},
"lastCommittedOpTime" : Timestamp(0, 0),
"$clusterTime" : {
"clusterTime" : Timestamp(1593569257, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1593569257, 1)
}
步骤 3
- 在副本集中启动分片服务器,并启用它们之间的复制功能。
mongod –shardsvr –port 27020 –replSet rs1 –dbpath C:datadata4 –bind_ip localhost mongod –shardsvr –port 27021 –replSet rs1 –dbpath C:datadata5 –bind_ip localhost mongod –shardsvr –port 27022 –replSet rs1 –dbpath C:datadata6 –bind_ip localhost
MongoDB 将初始化第一个分片服务器为主服务器。要移动主分片服务器,可以使用 movePrimary 方法。
步骤 4
- 在其中一台分片服务器上初始化副本集。
rs.initiate({_id:"rs0", members:[{_id:0, host:"IP:27020"}, {_id:1, host:"IP:27021"}, {_id:2, host:"IP:27022"}]})
{
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1593569748, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1593569748, 1)
}
步骤 5
- 启动 Mongos 以连接分片集群。
mongos –port 40000 –configdb rs0/localhost:27019,localhost:27018, localhost:27017
步骤 6
- 连接到 Mongos 路由服务器。
mongo --port 40000
- 现在,添加分片服务器。
sh.addShard("rs1/localhost:27020,localhost:27021,localhost:27022")
{
"shardAdded" : "rs1",
"ok" : 1,
"operationTime" : Timestamp(1593570212, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570212, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
步骤 7
- 在 MongoDB Shell 上启用对数据库和集合的分片。
- 在数据库上启用分片。
sh.enableSharding("geekFlareDB")
{
"ok" : 1,
"operationTime" : Timestamp(1591630612, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1591630612, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
步骤 8
- 要对集合进行分片,需要使用分片键(将在下文中详细描述)。
语法:sh.shardCollection(“dbName.collectionName”, { “key” : 1 } )
sh.shardCollection("geekFlareDB.geekFlareCollection", { "key" : 1 } )
{
"collectionsharded" : "geekFlareDB.geekFlareCollection",
"collectionUUID" : UUID("0d024925-e46c-472a-bf1a-13a8967e97c1"),
"ok" : 1,
"operationTime" : Timestamp(1593570389, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570389, 3),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
请注意,如果该集合不存在,请按照如下方式创建:
db.createCollection("geekFlareCollection")
{
"ok" : 1,
"operationTime" : Timestamp(1593570344, 4),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570344, 5),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
步骤 9
将数据插入到集合中。此时 MongoDB 日志会开始增长,显示平衡器正在运行并尝试在分片之间平衡数据。
步骤 10
最后一步是检查分片的状态。可以在 Mongos 路由节点上通过运行以下命令来检查状态。
分片状态
通过在 Mongos 路由节点上运行以下命令来检查分片状态。
sh.status()
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5ede66c22c3262378c706d21")
}
shards:
{ "_id" : "rs1", "host" : "rs1/localhost:27020,localhost:27021,localhost:27022", "state" : 1 }
active mongoses:
"4.2.7" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 5
Last reported error: Could not find host matching read preference { mode: "primary" } for set rs1
Time of Reported error: Tue Jun 09 2020 15:25:03 GMT+0530 (India Standard Time)
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
rs1 1024
too many chunks to print, use verbose if you want to force print
{ "_id" : "geekFlareDB", "primary" : "rs1", "partitioned" : true, "version" : { "uuid" : UUID("a770da01-1900-401e-9f34-35ce595a5d54"), "lastMod" : 1 } }
geekFlareDB.geekFlareCol
shard key: { "key" : 1 }
unique: false
balancing: true
chunks:
rs1 1
{ "key" : { "$minKey" : 1 } } -->> { "key" : { "$maxKey" : 1 } } on : rs1 Timestamp(1, 0)
geekFlareDB.geekFlareCollection
shard key: { "product" : 1 }
unique: false
balancing: true
chunks:
rs1 1
{ "product" : { "$minKey" : 1 } } -->> { "product" : { "$maxKey" : 1 } } on : rs1 Timestamp(1, 0)
{ "_id" : "test", "primary" : "rs1", "partitioned" : false, "version" : { "uuid" : UUID("fbc00f03-b5b5-4d13-9d09-259d7fdb7289"), "lastMod" : 1 } }
mongos>
数据分布机制
Mongos 路由器根据分片键将负载分布在不同的分片上,力求数据的均匀分布,这时,平衡器就会开始工作。
数据在分片之间分配的关键组件是:
- 平衡器负责在分片节点之间平衡数据子集。当 Mongos 服务器开始在分片之间分配负载时,平衡器将启动。一旦启动,它会尝试更均匀地分布数据。要检查平衡器的状态,请运行
sh.status()或sh.getBalancerState()或sh.isBalancerRunning()。
mongos> sh.isBalancerRunning() true mongos>
或者
mongos> sh.getBalancerState() true mongos>
在插入数据后,我们可以观察到 Mongos 守护进程的一些活动,表明它正在为特定的分片移动数据块。这个过程表明平衡器正在尝试在分片之间平衡数据。运行平衡器可能会导致性能问题,因此建议在特定的 平衡器窗口 内运行。
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5efbeff98a8bbb2d27231674")
}
shards:
{ "_id" : "rs1", "host" : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022", "state" : 1 }
{ "_id" : "rs2", "host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025", "state" : 1 }
active mongoses:
"4.2.7" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: yes
Failed balancer rounds in last 5 attempts: 5
Last reported error: Could not find host matching read preference { mode: "primary" } for set rs2
Time of Reported error: Wed Jul 01 2020 14:39:59 GMT+0530 (India Standard Time)
Migration Results for the last 24 hours:
1024 : Success
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
rs2 1024
too many chunks to print, use verbose if you want to force print
{ "_id" : "geekFlareDB", "primary" : "rs2", "partitioned" : true, "version" : { "uuid" : UUID("a8b8dc5c-85b0-4481-bda1-00e53f6f35cd"), "lastMod" : 1 } }
geekFlareDB.geekFlareCollection
shard key: { "key" : 1 }
unique: false
balancing: true
chunks:
rs2 1
{ "key" : { "$minKey" : 1 } } -->> { "key" : { "$maxKey" : 1 } } on : rs2 Timestamp(1, 0)
{ "_id" : "test", "primary" : "rs2", "partitioned" : false, "version" : { "uuid" : UUID("a28d7504-1596-460e-9e09-0bdc6450028f"), "lastMod" : 1 } }
mongos>
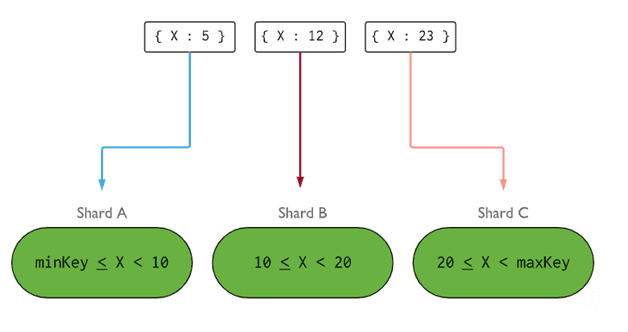
- 分片键 (Shard Key) 决定了如何将分片集合中的文档分配到各个分片。分片键可以是索引字段或索引复合字段,它必须存在于要插入集合的所有文档中。数据将按范围被分成块,每个块与一个分片键关联。路由器根据范围查询,确定哪个分片将存储该数据块。
选择分片键时,需要考虑以下五个关键属性:
- 基数
- 写分布
- 读分布
- 读定位
- 读位置
理想的分片键应使 MongoDB 能够在所有分片上平均分配负载。选择一个合适的分片键至关重要。
删除分片节点
在从集群中移除分片之前,务必确保已将该分片上的数据安全迁移到剩余的分片。MongoDB 负责在移除指定分片节点前,安全地将数据迁移到其他分片节点。
运行以下命令以删除所需的分片:
步骤 1
首先,需要确定要删除的分片的主机名。 以下命令将列出集群中存在的所有分片以及分片的状态。
db.adminCommand( { listShards: 1 } )
mongos> db.adminCommand( { listShards: 1 } )
{
"shards" : [
{
"_id" : "rs1",
"host" : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022",
"state" : 1
},
{
"_id" : "rs2",
"host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1593572866, 15),
"$clusterTime" : {
"clusterTime" : Timestamp(1593572866, 15),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
步骤 2
发出以下命令,从集群中移除所需的分片。一旦发出,平衡器将负责从正在耗尽的分片节点中删除数据块,并平衡剩余块在其余分片节点之间的分布。
db.adminCommand( { removeShard: “shardedReplicaNodes” } )
mongos> db.adminCommand( { removeShard: "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022" } )
{
"msg" : "draining started successfully",
"state" : "started",
"shard" : "rs1",
"note" : "you need to drop or movePrimary these databases",
"dbsToMove" : [ ],
"ok" : 1,
"operationTime" : Timestamp(1593572385, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1593572385, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
步骤 3
要检查耗尽分片的状态,请再次发出相同的命令。
db.adminCommand( { removeShard: “rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022” } )
我们需要等待数据排空完成。 msg 和 state 字段将显示数据排空是否已完成,如下所示:
"msg" : "draining ongoing", "state" : "ongoing",
我们还可以使用 sh.status() 命令检查状态。一旦删除分片节点,该节点将不再显示在输出中。但是,如果数据排空正在进行,则该分片节点的排空状态将为 true。
步骤 4
继续使用上述命令检查排空状态,直到完全删除所需的分片。完成数据排空后,命令输出将反映出已完成的消息和状态。
"msg" : "removeshard completed successfully", "state" : "completed", "shard" : "rs1", "ok" : 1,
步骤 5
最后,我们需要检查集群中剩余的分片。 要检查状态,请输入 sh.status() 或 db.adminCommand( { listShards: 1 } )。
mongos> db.adminCommand( { listShards: 1 } )
{
"shards" : [
{
"_id" : "rs2",
"host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1593575215, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1593575215, 3),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
这里可以看到,已删除的分片不再显示在分片列表中。
分片相对于复制的优势
- 在复制中,主节点处理所有写入操作,而辅助节点则维护备份副本或提供只读操作。 但是,当分片与副本集一起使用时,负载会分布在多个服务器之间。
- 单个副本集限制为 12 个节点,而分片集群对分片数量没有限制。
- 复制需要高端硬件或垂直扩展来处理大型数据集,与在分片中添加额外的服务器相比,这成本更高。
- 在复制中,可以通过添加更多的从/从节点来提高读取性能,而在分片中,可以通过添加更多的分片节点来提高读取和写入性能。
分片技术的局限性
- 分片集群不支持跨分片的唯一索引,除非唯一索引以完整的分片键为前缀。
- 对一个或多个文档的分片集合的所有更新操作,必须在查询中包含分片键或
_id字段。 - 只有当集合的大小不超过指定阈值时,才能对集合进行分片。 此阈值可以根据所有分片键的平均大小和配置的块大小来估计。
- 分片还存在对最大集合大小或数据块拆分数量的操作限制。
- 选择不合适的分片键可能会导致性能瓶颈。
总结
MongoDB 提供了内置的分片功能,可用于处理大型数据库,同时确保性能不受影响。 希望以上内容能够帮助您理解 MongoDB 分片机制的设置。 接下来,您可能需要进一步熟悉一些常用的 MongoDB 命令。