Python 在数据科学中的崛起与数据分析基础
近年来,Python 在数据科学领域的应用呈现爆炸式增长,并且这一趋势仍在持续加速。数据科学本身是一个广泛的研究领域,包含众多子领域。在这些子领域中,数据分析无疑占据着核心地位,对于任何数据科学从业者,无论其技能水平如何,理解数据分析或至少掌握其基本概念都变得至关重要。
什么是数据分析?
数据分析的核心是对大量非结构化或杂乱无章的数据进行清理和转换,其目的是从中提取关键的洞察和信息,这些信息能够帮助我们做出更明智的决策。 市场上存在多种用于数据分析的工具,例如Python、Microsoft Excel、Tableau和SaS等等。本文将重点探讨如何使用 Python 进行数据分析,更具体地说,我们将深入了解如何使用一个名为 Pandas 的 Python 库。
Pandas 简介
Pandas 是一个开源的 Python 库,专门用于数据操作和整理。它以其高效和快速的特性著称,并提供了强大的工具来将各种数据加载到内存中。Pandas 可以用于重塑、切片、索引数据,甚至可以对多种形式的数据进行分组。
Pandas 中的数据结构
Pandas 主要提供了三种数据结构,分别是:
- Series (序列)
- DataFrame (数据帧)
- Panel (面板)
理解这三种结构的最佳方式是将它们想象成彼此嵌套的堆栈。DataFrame 可以被看作是一系列 Series 的堆叠,而 Panel 则是 DataFrame 的堆叠。
- Series 是一维数组。
- 多个 Series 堆叠在一起形成二维 DataFrame。
- 多个 DataFrame 堆叠在一起形成三维 Panel。
在实际应用中,我们最常使用的数据结构是二维 DataFrame,它也是我们经常遇到的某些数据集的默认呈现方式。
使用 Pandas 进行数据分析
为了方便本文的演示,我们无需进行任何安装。我们将使用谷歌开发的在线 Python 环境 Colab。它是一个基于云的 Jupyter Notebook,预装了数据科学家常用的几乎所有 Python 包,非常适合数据分析、机器学习和人工智能等应用。
现在,请访问以下链接: https://colab.research.google.com/notebooks/intro.ipynb。您应该会看到类似下面的内容。
通过左上角的导航菜单,点击 “文件” 选项,然后选择 “新建笔记本”。这时,您会在浏览器中看到一个新的 Jupyter Notebook 页面。首先,我们需要将 Pandas 导入到我们的工作环境中。我们可以通过运行以下代码来实现:
import pandas as pd
在本文中,我们将使用一个房价数据集进行数据分析。 您可以在 这里 找到我们使用的数据集。 第一步是将这个数据集加载到我们的环境中。
我们可以在一个新的代码单元格中使用以下代码来实现:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
当我们需要读取 CSV 文件时,可以使用 .read_csv 函数,并且通过传递 sep 属性来指明 CSV 文件是以逗号分隔的。
另外需要注意的是,我们加载的 CSV 文件存储在名为 df 的变量中。
在 Jupyter Notebook 中,我们无需使用 print() 函数来显示变量的值。只需在代码单元格中输入变量名称,Jupyter Notebook 就会自动将其打印出来。
您可以尝试在新单元格中键入 df 并运行,它会以 DataFrame 的形式输出数据集中的所有数据。
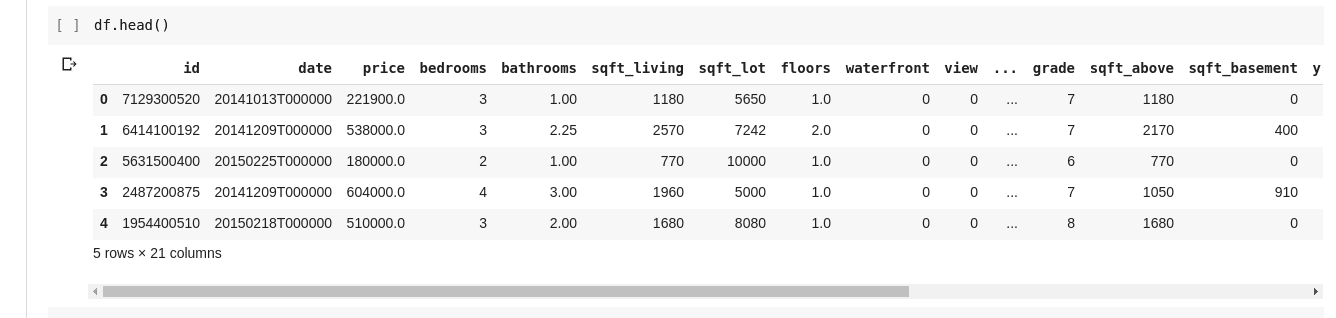
然而,我们并不总是需要查看所有的数据。有时,我们可能只想查看前几行数据以及它们的列名。我们可以使用 df.head() 函数来打印前五行,或者使用 df.tail() 函数来打印最后五行。这两个函数的输出格式类似:
接下来,我们可能需要了解数据集中各个列之间的关系。 .describe() 函数可以帮助我们实现这个目的。
运行 df.describe() 将会产生如下输出:
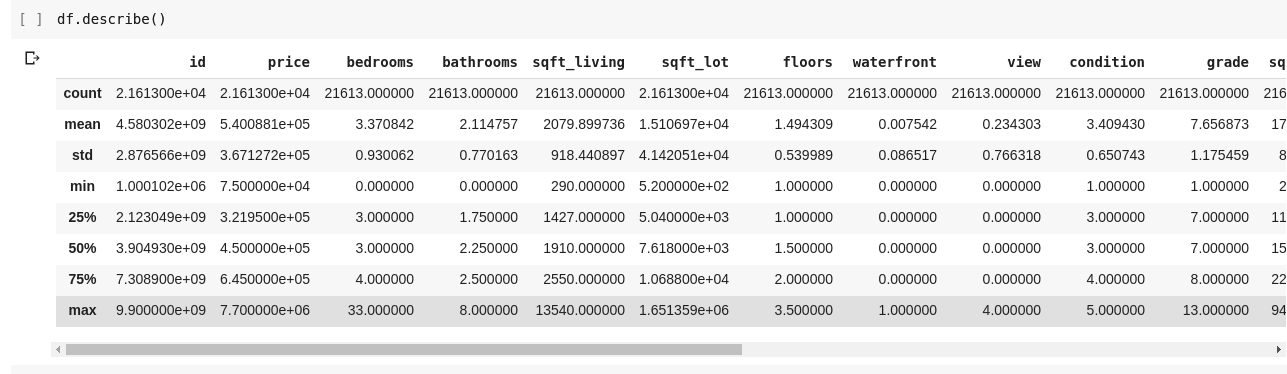
.describe() 函数输出了 DataFrame 中每一列的均值、标准差、最小值、最大值以及百分位数等信息。 这些统计数据对于理解数据的分布非常有用。
我们还可以使用 df.shape 来检查二维 DataFrame 的形状,了解它有多少行和多少列。该函数会返回一个形如 (rows, columns) 的元组。
此外,我们可以使用 df.columns 来查看 DataFrame 中所有列的名称。
如果我们只想选择 DataFrame 中的某一列并返回其中所有的数据,该如何操作呢?我们可以采用类似于字典切片的方式来实现。在新代码单元格中输入以下代码并运行:
df['price ']
上面的代码会返回名为 “price” 的列,我们可以将其保存到一个新的变量中,以便后续操作:
price = df['price']
现在,我们可以像操作 DataFrame 一样,对 price 变量执行所有相同的操作,因为它实际上只是 DataFrame 的一个子集,例如使用 df.head() 或 df.shape。
我们还可以通过将列名列表传递给 df 来选择多个列:
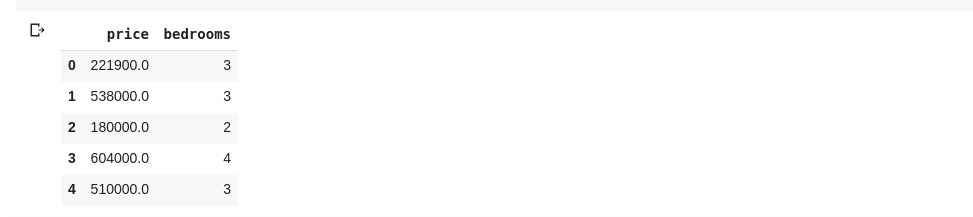
data = df[['price ', 'bedrooms']]
上述代码选择了名为 “price” 和 “bedrooms” 的列。如果在新的代码单元格中输入 data.head(), 我们会得到以下结果:
以上列切片方式返回了列中的所有行元素。如果我们想从数据集中返回行和列的子集呢?可以使用 .iloc 方法,该方法采用类似于 Python 列表的索引方式。 例如,我们可以这样做:
df.iloc[50: , 3]
它返回从第 50 行到最后的第 3 列的数据。这种方式非常简洁,与 Python 中列表的切片操作方式类似。
接下来,让我们做一些更有趣的事情。我们的房价数据集包含一列表示房屋的价格,另一列表示房屋的卧室数量。 房价是一个连续值,这意味着我们可能不会有两个价格相同的房屋。而卧室的数量则是一个离散值,所以我们可能会有多套拥有两间、三间或四间卧室等的房屋。
如果想要获取卧室数量相同的房屋,并找出每种卧室数量对应的平均价格,该如何操作呢? 使用 Pandas,这很容易实现,可以使用以下代码完成:
df.groupby('bedrooms ')['price '].mean()
上述代码首先使用 df.groupby() 函数,按照卧室数量对 DataFrame 中的数据进行分组,然后我们指定只选取 ‘price’ 列,并使用 .mean() 函数来计算数据集中每种卧室数量对应的平均房价。
如果想要将上述信息可视化展示,例如想了解不同卧室数量的平均价格如何变化,该怎么办? 我们只需在前面的代码后面链接一个 .plot() 函数即可:
df.groupby('bedrooms ')['price '].mean().plot()
执行上述代码后,我们将得到类似下面的输出:
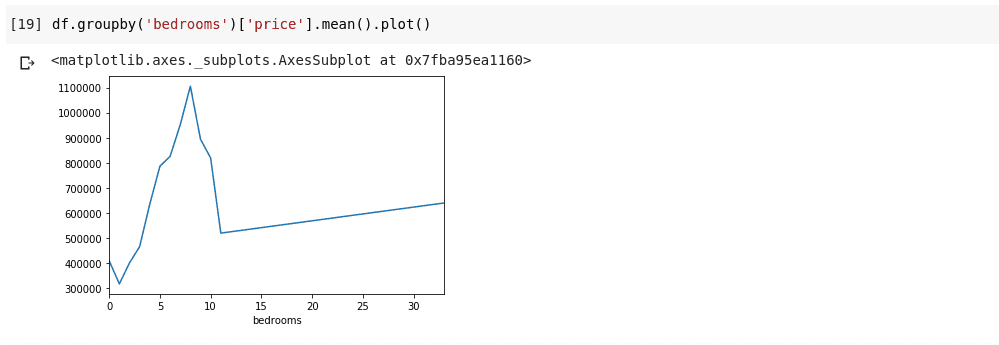
上面的图表展示了数据中的一些趋势。 横轴表示不同的卧室数量(请注意,可能有多套房屋拥有 X 间卧室),纵轴表示与横轴上对应卧室数量的平均价格。 我们可以立即注意到,拥有 5 到 10 间卧室的房屋比拥有 3 间卧室的房屋价格高得多。 此外,我们可以观察到拥有大约 7 或 8 间卧室的房屋比拥有 15、20 甚至 30 间卧室的房屋价格要高得多。
以上信息展示了数据分析的重要性,它使我们能够从数据中提取有用的见解。如果没有进行分析,这些见解通常是难以直接观察到的。
数据缺失
假设我正在进行一项包含一系列问题的调查。我将调查链接分享给成千上万的人,希望他们能提供反馈。我的最终目标是对收集到的数据进行分析,以便从中获得一些关键的见解。
在实际操作中,可能会发生很多错误,例如有些受访者可能因为对回答某些问题感到不自在而将其留空,或者许多人可能会对调查问卷的某些部分做出同样的操作。这似乎不是什么大问题。但是,想象一下,如果我在调查中收集的是数字数据,并且部分分析需要我计算总和、平均值或其他一些算术运算。一些缺失值可能会导致我的分析出现诸多不准确之处。我必须找到一种方法来查找这些缺失值,并将其替换为一些合理的值。
Pandas 提供了名为 isnull() 的函数来查找 DataFrame 中的缺失值。
isnull() 函数可以这样使用:
df.isnull()
这将返回一个布尔值的 DataFrame,它告诉我们哪些数据是缺失的(True),哪些不是缺失的(False)。输出结果类似于:
我们需要一种方法能够替换所有这些缺失值。在大多数情况下,可以将缺失值替换为零。有时,可以将缺失值视为其他所有数据的平均值,或者可能是其周围数据的平均值,具体取决于数据科学家和所分析数据的具体应用场景。
为了填充 DataFrame 中的所有缺失值,我们可以使用 .fillna() 函数:
df.fillna(0)
上述代码用零值填充了所有空数据。当然,也可以使用我们指定的任何其他数字。
数据的重要性再怎么强调都不为过,它帮助我们从数据本身获得答案!人们常说,数据分析是数字经济的新石油。
本文中的所有示例都可以在 这里 找到。
要更深入地了解,请查看 使用 Python 和 Pandas 进行数据分析在线课程。