联邦学习代表了一种数据收集和机器学习模型训练方式的创新突破。
通过联邦学习,机器学习的开发在保护数据隐私的前提下,能够以更低的成本进行训练。本文将深入探讨联邦学习的概念、工作原理、应用场景以及相关框架。
什么是联邦学习?
 来源: 维基百科
来源: 维基百科
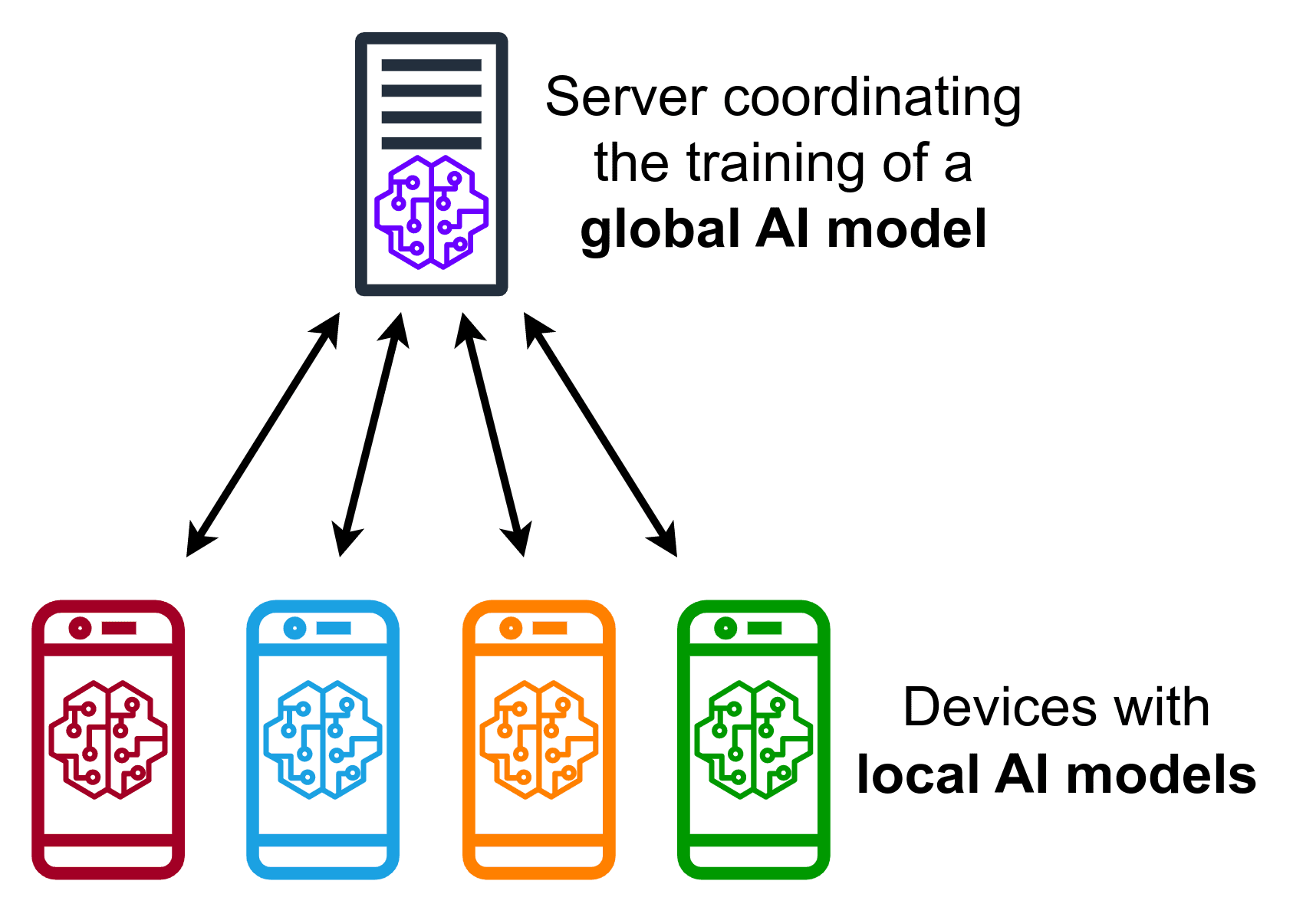
联邦学习是一种颠覆传统机器学习模型训练方式的新范式。 传统的机器学习模型通常会将来自多个客户端的数据收集到一个中央存储库中,然后在这个中央存储库中训练模型并用于预测。 而联邦学习则与之相反。 它不要求客户端将数据发送到中央存储库,而是让客户端基于本地数据训练模型,从而有效地保护了个人数据的隐私性。
另请阅读:顶级机器学习模型详解
联邦学习如何运作?
联邦学习的学习过程包含一系列生成模型的迭代步骤,这些步骤被称为学习轮次。 一个典型的学习过程会不断迭代这些轮次,从而逐步改进模型。每一轮学习都包含以下步骤。
典型的学习回合
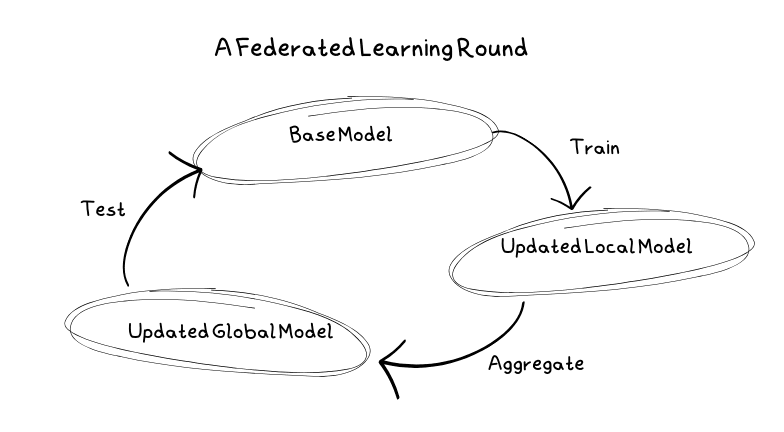
首先,服务器会选择要训练的模型以及一些超参数,例如训练轮数、要使用的客户端节点数量以及每个节点所占的比例。 同时,模型也会被初始化,以生成一个基础模型。
接下来,客户端会获取基础模型的副本进行训练。 这些客户端可以是移动设备、个人电脑或服务器。 他们会利用各自的本地数据来训练模型,从而避免了敏感数据与服务器的共享。
一旦客户端基于本地数据完成模型训练,他们会将模型更新发送回服务器。 服务器在接收到更新后,会将这些更新与来自其他客户端的更新进行聚合,从而创建一个新的基础模型。 由于客户端的可靠性可能无法保证,一些客户端可能无法及时发送更新。此时,服务器会处理所有可能的错误。
在重新部署基础模型之前,必须对其进行测试。 然而,服务器不存储任何数据。 因此,为了测试模型,服务器会将其发送回客户端,让客户端使用本地数据进行测试。 如果测试结果优于之前的模型,则会采用并使用该模型。
这是一个有用的指南,由Google AI的联邦学习团队提供,详细介绍了联邦学习的工作原理。
集中式、联合式、异构式
在这种设定下,有一个中央服务器负责控制整个学习过程。这种类型的设置被称为集中式联邦学习。
与集中式学习相对的是去中心化联邦学习,在这种模式下,客户端之间会进行点对点的协调。
另外一种设置被称为异构学习。在这种设置中,客户端不一定具有相同的全局模型架构。
联邦学习的优势
- 联邦学习最大的优势在于它能够保护私有数据的隐私性。 客户端分享的是训练结果,而不是训练过程中使用的数据。 此外,还可以制定协议来聚合这些结果,从而避免将结果与特定客户端关联起来。
- 由于客户端和服务器之间不共享数据,这也有助于减少网络带宽的消耗。 相反,模型是在客户端和服务器之间交换。
- 这还降低了模型训练的成本,因为无需购买昂贵的训练硬件。 相反,开发人员可以利用客户端的硬件来训练模型。 由于涉及的数据量较少,这对客户端的设备不会造成额外的压力。
联邦学习的缺点
- 该模型依赖于多个不同节点的参与。 其中一些节点并不受开发人员的控制,因此无法保证其可用性。这使得训练硬件的可靠性存在一定风险。
- 用于训练模型的客户端通常不是高性能的GPU,而是普通的设备,例如手机。 即使这些设备的算力加起来,可能也无法与GPU集群相媲美。
- 联邦学习还假设所有客户端节点都是值得信赖的,并且为共同利益而工作。 然而,实际情况并非总是如此,一些节点可能会发布错误的更新,从而导致模型漂移。
联邦学习的应用
联邦学习能够在保护隐私的同时实现机器学习。这在很多场景下都非常有用,例如:
- 智能手机键盘上的下一个词预测。
- 物联网设备可以根据实际情况,在本地训练模型。
- 制药和医疗保健行业。
- 国防工业也可以从这种无需共享敏感数据的模型训练方式中受益。
联邦学习框架
目前有很多可以用来实施联邦学习模式的框架。 其中一些比较好的包括NVFlare、FATE、Flower和PySft。 你可以参考这篇指南,详细比较这些不同的框架。
结论
本文介绍了联邦学习的概念、工作原理以及其优缺点。此外,本文还概述了联邦学习在实际应用中的场景和常用框架。
接下来,你可以阅读有关训练机器学习模型的最佳MLOps平台的文章。