深入解析 Deepfakes,以及如何使用 Faceswap 轻松创建它们。
人工智能正在迅速发展,其能力已经逼近人类的水平。
它不仅能提供建议、撰写文章、创作艺术,现在还能模仿人类的外貌和声音。
这既是技术领域的新突破,也是我们必须警惕的潜在风险。
什么是 Deepfakes?
“Deepfake”这个词由“深度学习”(Deep Learning)和“伪造”(Fake)组合而成。简单来说,Deepfake 指的是经过高级技术处理的、高度逼真的伪造媒体内容。
根据维基百科的定义,Deepfake 也被称为合成媒体,它通过修改现有的图像、音频或视频,使其看起来像是另一个人在说或做某事。
通常,Deepfake 能够让知名人士说出或做出他们从未做过的事情。
由于其高超的制作技术,Deepfake 的真假往往难以辨别。
Deepfakes 的工作原理?
简单来说,Deepfake 的运作方式是将原始视频中的一部分(例如人脸)替换成一个相似的伪造对象。 这个过程也被称为换脸,就像那个著名的 “奥巴马” 视频一样。
但 Deepfake 不仅限于视频,还包括图像和音频(甚至可能在不久的将来出现 Deepfake VR 头像)。
资料来源:迪士尼
这些技术背后的工作原理主要取决于所使用的应用程序和底层算法。
根据迪士尼的研究论文,Deepfake 技术包括编码器-解码器、生成对抗网络 (GAN) 以及基于几何的深度伪造等多种方法。
本文主要侧重于 Deepfake 与 Faceswap 配合使用的方式。 Faceswap 是一款免费开源的 Deepfake 软件,它支持多种算法来达到预期效果。
生成 Deepfake 的主要过程包括:提取、训练和转换。
#1. 提取
提取是指从原始媒体样本和替换样本中检测并提取出感兴趣的主题区域。
根据硬件性能的不同,可以选择多种不同的算法进行有效检测。
例如,Faceswap 提供了多种提取、对齐和遮罩选项,以适应 CPU 或 GPU 的效率。
提取过程首先识别整个视频中的人脸。 然后对齐面部的关键特征(例如眼睛、鼻子、下巴等)。 最后,遮罩会遮挡图像中除感兴趣区域之外的其他元素。
完成输出所需的时间是选择任何选项的重要考虑因素。在性能较弱的硬件上选择高资源消耗的算法可能会导致失败或需要很长时间才能产生可接受的结果。
除了硬件外,选择算法还取决于其他参数,例如输入视频是否受到手部动作或眼镜等面部遮挡物的影响。
最后,清理(稍后解释)输出至关重要,因为提取过程中可能会出现误报。
提取过程需要在原始视频和用于替换的伪造视频上重复进行。
#2. 训练
训练是 Deepfake 生成的核心环节。
训练过程主要围绕神经网络展开,它由编码器和解码器组成。算法将提取的数据输入神经网络,以创建用于后续转换的模型。
编码器将输入转换为向量表示,然后算法会从向量中重新创建人脸,就像解码器所做的那样。
之后,神经网络会评估其迭代结果,并通过分配损失分数将它们与原始迭代结果进行比较。 随着算法的不断迭代,损失值会逐渐下降。当预览效果达到可接受的程度时,就可以停止训练。
训练是一个耗时的过程,输出效果通常会随着迭代次数和输入数据质量的提高而改善。
例如,Faceawap 建议每个面部至少使用 500 张图像,包括原始图像和用于替换的图像。 此外,图像之间应存在显著差异,覆盖各种光照条件和角度,以获得最佳的模拟效果。
考虑到训练时间可能很长,一些应用程序(如 Faceswap)允许中途停止训练或稍后继续。
值得注意的是,输出的逼真程度还取决于算法的效率和输入质量,以及硬件性能的限制。
#3. 转换
转换是 Deepfake 创建的最后阶段。 转换算法需要源视频、训练模型和源对齐文件。
之后,可以调整一些与色彩校正、蒙版类型和所需输出格式等相关的选项。
配置完这些选项后,只需等待最终渲染即可。
如前所述,Faceswap 支持多种算法,并且可以根据需要进行调整,以获得理想的换脸效果。
这就结束了吗?
不!
这仅仅是换脸,是 Deepfake 技术的一个子集。 换脸,顾名思义,只是替换了人脸的一部分,让人们对 Deepfake 的潜力有一个大致的了解。
为了实现逼真的替换效果,你可能还需要模仿音频(通常称为声音克隆)以及整个身体的姿态,使之与画面内容相匹配,如下所示:

那么,这里发生了什么?
一种可能性是,Deepfake 的作者自己拍摄了视频(如最后几秒所示),将对话与摩根·弗里曼的合成声音进行口型同步,并替换了他的头部。

总而言之,这不仅仅是换脸,而是包括音频在内的整个画面。
你在 YouTube 上可以找到大量的 Deepfake 视频,它们令人难以置信。 只需要一台配备高效显卡的强大计算机就可以开始制作。
然而,完美是难以实现的,对于 Deepfake 来说尤其如此。
要制作一个足以误导观众或令观众惊叹的 Deepfake,需要技巧和数天到数周的时间来处理一两分钟的视频。
这只是这些算法目前的能力。 但是,未来会怎样,以及这些应用程序在低端硬件上的效果如何,都让政府感到紧张。
但是,我们不会深入探讨其未来的影响。 相反,让我们自己尝试一下如何制作,以获得一点乐趣。
创建(基本)Deepfake 视频
你可以查看这个 Deepfake 应用程序列表,其中有许多可以用来制作模因的工具。
其中之一是 Faceswap,我们将使用它。
在继续之前,我们需要确保一些事项。首先,我们需要一个高质量的目标视频,该视频能够展现不同的情绪。 其次,我们需要一个源视频来替换目标视频中的人脸。
此外,在开始使用 Faceswap 之前,请关闭所有占用大量图形卡的应用程序,如浏览器或游戏。如果你的 VRAM(视频 RAM)小于 2GB,这一点尤为重要。
第 1 步:提取人脸
此过程的第一步是从视频中提取人脸。为此,我们需要在输入目录中选择目标视频,并指定提取的输出目录。
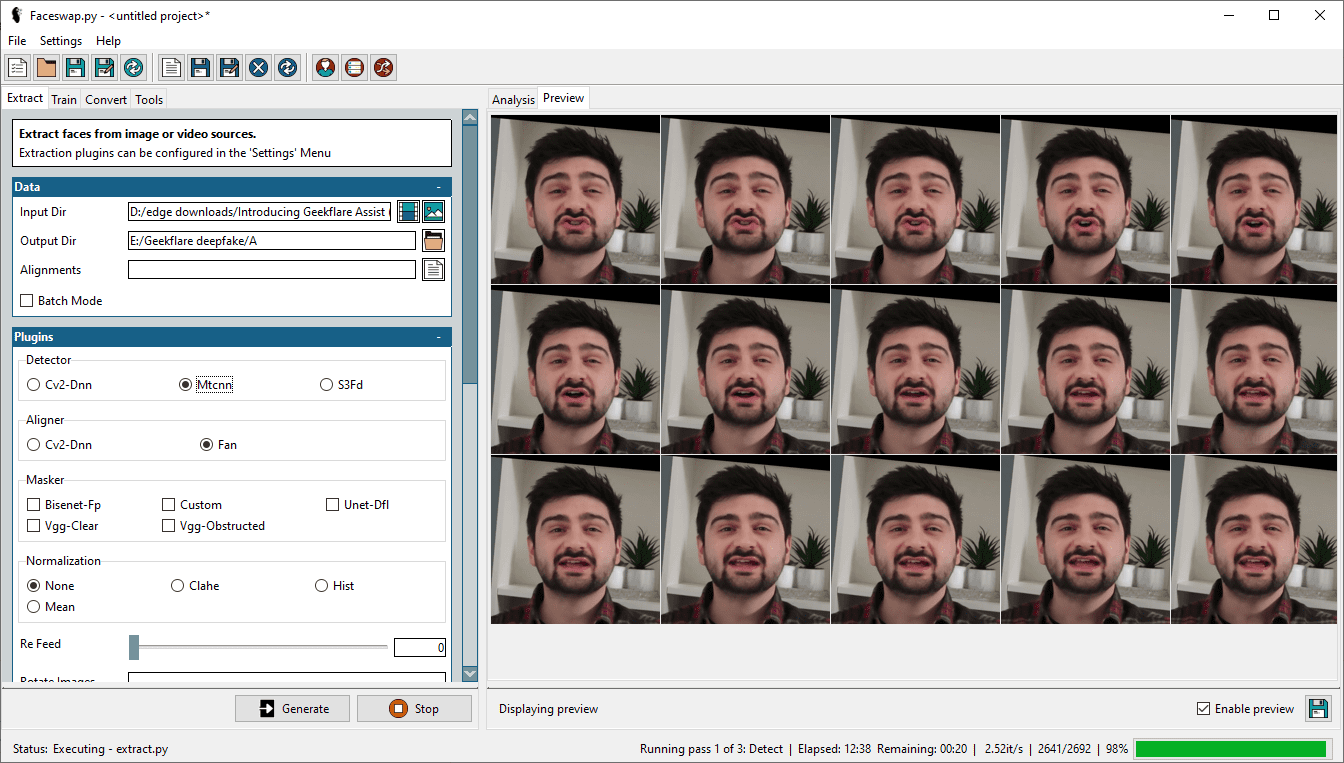
此外,还有几个选项,包括检测器、对齐器和掩蔽器等; 这些选项的详细解释可以在 Faceswap 常见问题解答中找到。在此重复这些信息是没有必要的。
 资料来源:Faceswap 常见问题解答
资料来源:Faceswap 常见问题解答
通常,最好查看文档以获得更深入的理解和更好的输出效果。但是,您可以通过将鼠标悬停在特定的选项上来找到 Faceswap 中有用的说明信息。
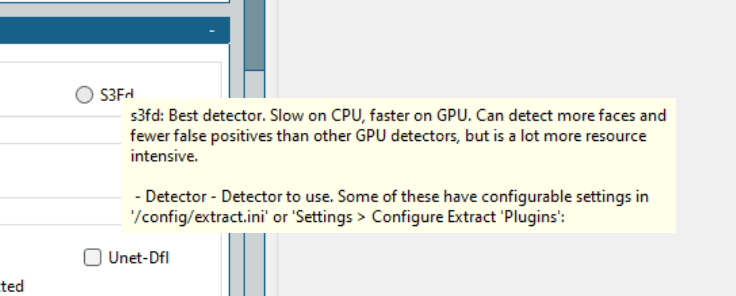
简而言之,没有通用的方法。 用户应该从最适合的算法开始,然后逐步调整以成功创建一个令人信服的 Deepfake。
就本文的案例而言,我使用了 Mtcnn(检测器)、Fan(对齐器)和 Bisenet-Fp(掩蔽器),并保持所有其他选项不变。
我最初尝试将 S3Fd(最佳检测器)和其他几个掩码结合使用。 但是,我的 2GB Nvidia GeForce GTX 750Ti 性能不足,导致程序多次失败。
最后,我降低了期望和设置,并成功完成了提取过程。
除了选择合适的检测器和掩蔽器之外,”设置 > 配置设置” 中还有一些选项可以帮助进一步调整各项设置,以适应不同的硬件性能。
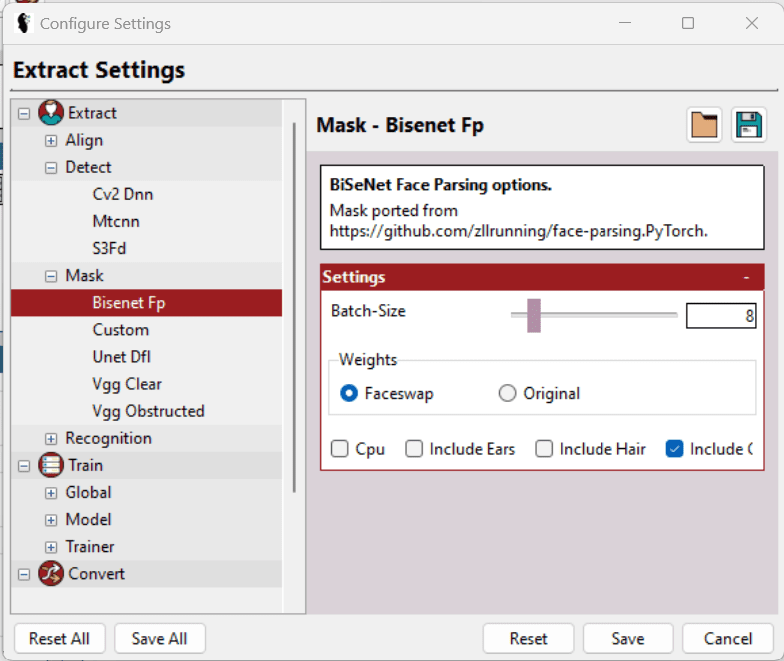
简单来说,批量大小、输入大小和输出大小应尽可能选择最小值,并勾选 LowMem 等选项。这些选项并非通用,而是根据特定部分而设置。 此外,工具提示可以帮助你选择最佳选项。
尽管该工具在提取人脸方面表现出色,但输出的帧数可能远远超过训练模型所需帧数(稍后讨论)。例如,它可能包含所有的人脸(如果视频中有多个面孔)和一些根本没有目标人脸的不正确检测。
这需要清理数据集。你可以手动检查输出文件夹并删除不需要的帧,也可以使用 Faceswap 的排序工具来获得帮助。
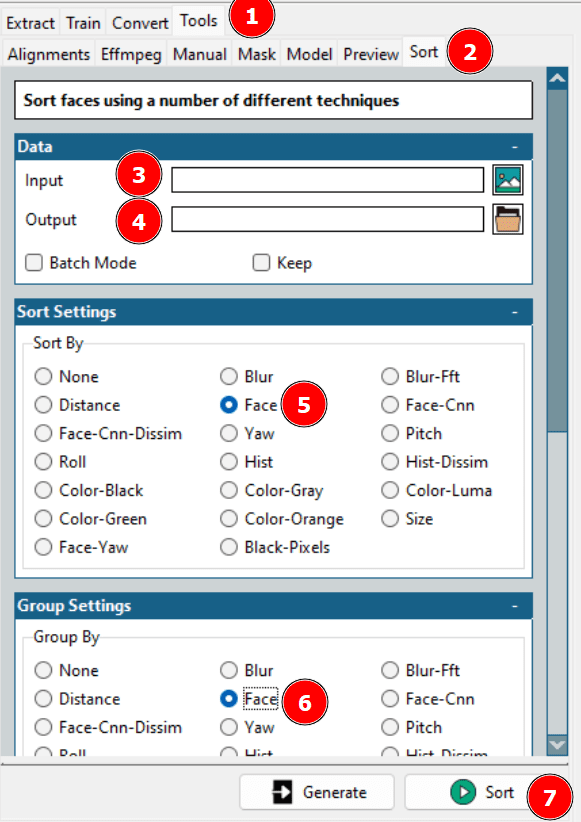
使用上述工具,可以按顺序排列不同的面孔,你可以将所需的面孔放在一个文件夹中,然后删除其余的面孔。
请记住,你需要对源视频重复提取过程。
第 2 步:训练模型
这是创建 Deepfake 中耗时最长的过程。在这里,“Input A” 指的是目标人脸,“Input B” 指的是源人脸。此外,“模型目录”用于保存训练文件。
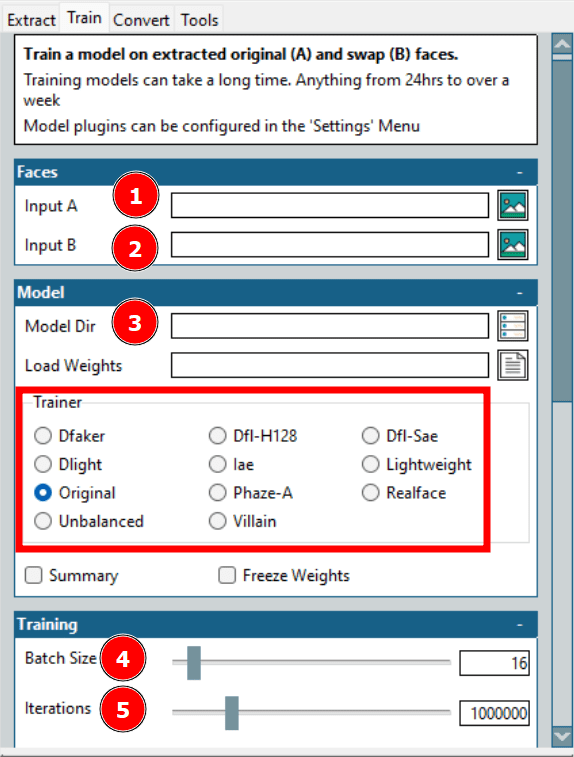
此处最重要的选项是 Trainer(训练器)。有很多单独的缩放选项;但最适合我的硬件的是 Dfl-H128 和具有最低配置设置的轻量级训练器。
接下来是批量大小。较大的批量大小可以减少总训练时间,但会消耗更多的 VRAM。迭代次数对输出没有固定的影响。你应设置一个足够大的值,并在预览效果可接受时停止训练。
还有一些其他设置,例如创建具有预设间隔的延时摄影;但是,我使用最少的训练模型进行了演示。
第 3 步:切换到原件
这是 Deepfake 创建的最后一步。
这一步通常不需要花费太多时间。你可以使用多种选项来快速获得所需的输出。
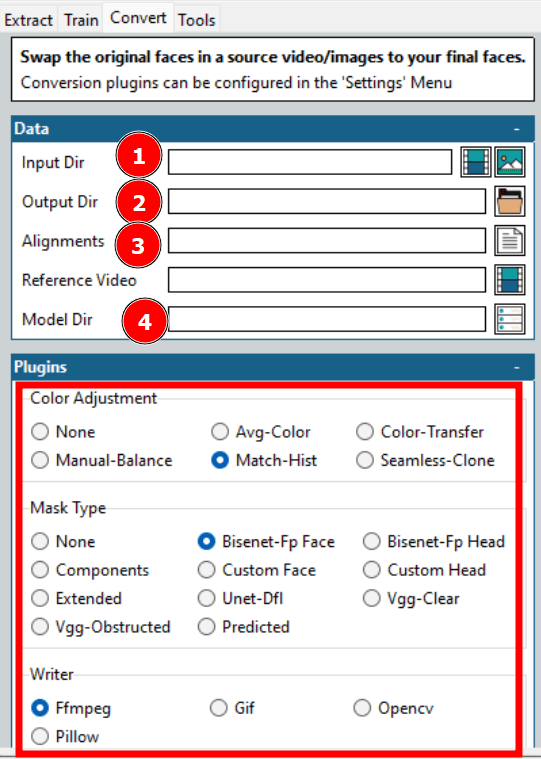
如上图所示,这些是开始转换需要选择的一些选项。
大多数选项都已讨论过,例如输入和输出目录、模型目录等。需要特别注意的是“对齐”选项,它指的是目标视频的对齐文件 (.fsa)。 该文件在提取过程中在输入目录中创建。
如果尚未移动该特定文件,则可以将 “对齐” 字段留空。否则,可以选择该文件并转到其他选项。但是,如果你之前清理过提取的文件,请记住清理对齐文件。
为此,可以使用工具 > 对齐 中的迷你工具。
首先,在 Job 部分选择 “Remove-Faces”,然后选择原始对齐文件和清理后的目标面部文件夹,并单击右下角的 Alignments 按钮。
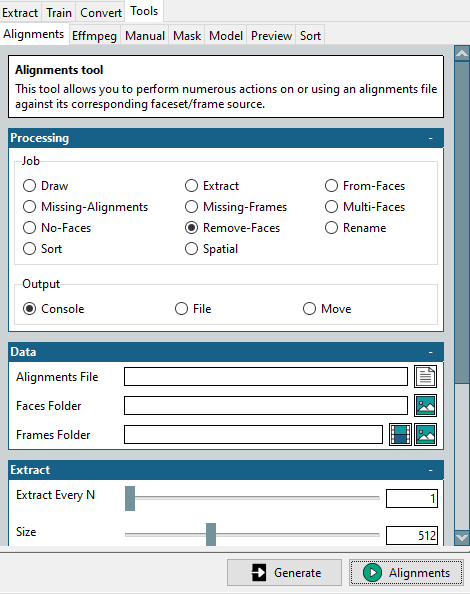
这会创建一个修改后的对齐文件,与优化的面部文件夹相匹配。 请记住,我们需要将其用于要交换的目标视频。
其他配置选项包括颜色调整和蒙版类型。 颜色调整决定蒙版的混合方式,你可以尝试一些选项,检查预览效果,然后选择最佳选项。
蒙版类型更为重要。同样,这取决于你的期望和可用的硬件。 通常,你还需要考虑输入视频的特性。例如,Vgg-Clear 适用于没有遮挡的正脸,而 Vgg-Obstructed 可以处理遮挡物,如手势和眼镜等。
接下来,Writer 根据你想要的输出提供一些选项。 例如,你可以选择 Ffmpeg 进行视频渲染。
总而言之,Deepfake 成功的关键是预览一些输出并根据时间可用性和硬件性能进行优化。
Deepfake 的应用
Deepfake 既有好的应用,也有坏的和危险的应用。
好的应用包括使用真人重新创建历史场景,以提高参与度。
此外,在线学习平台正在使用 Deepfake 从文本生成视频。
但最大的受益者之一将是电影业。 在这里,我们很容易想象到真正的主角表演特技,即使是那些可能危及生命的特技。 此外,制作多语种电影将比以往任何时候都容易。
不幸的是,不好的应用有很多。 实际上,到目前为止最大的 Deepfake 应用有 96%(根据这份 Deeptrace 报告)是在色情行业将名人面孔替换为色情演员。
此外,Deepfake 还被用来攻击普通女性。 通常,此类受害者的社交媒体资料上有高质量的照片或视频,可用于制作 Deepfake。
另一个令人担忧的应用是网络钓鱼,即语音网络钓鱼。 在这样一个案例中,一家英国公司的首席执行官根据其德国母公司 “首席执行官” 的指示转账了 24.3 万美元,但后来发现这实际上是一个 Deepfake 电话。
但更危险的是,Deepfake 可能会被用来挑起战争或要求投降。最近的一次尝试是使用 Deepfake 视频让乌克兰总统沃洛季米尔·泽连斯基 (Volodymyr Zelenskyy) 告诉他的部队和人民在正在进行的战争中投降。 但是,这一次,劣质的视频暴露了真相。
总而言之,Deepfake 的应用领域非常广泛,而且才刚刚起步。
这引出了一个关键的问题……
Deepfake 合法吗?
这主要取决于当地政府。 虽然,目前尚未出台明确的法律,包括什么是允许的,什么是不允许的。
但是,显而易见的是,这取决于你使用 Deepfake 的目的。如果你打算在不干扰交换对象的情况下进行娱乐或教育活动,那么几乎没有任何危害。
另一方面,无论管辖权如何,恶意应用程序都应受到法律惩罚。 另一个灰色地带是侵犯版权,需要适当考虑。
但再次强调,你应向当地政府机构咨询 Deepfake 的合法使用方式。
保持警惕!
Deepfake 利用人工智能让人为所欲为。
我们应该采取的第一个建议是:不要相信你在互联网上看到的任何东西。 网络上充斥着大量的虚假信息,而且它们的传播能力只会越来越强。
由于创建 Deepfake 将变得越来越容易,所以现在是我们学习如何识别 Deepfake 的时候了。