数据抓取是从网页上收集特定信息的过程。用户可以从中提取文本、图片、视频、评论、产品信息等多种类型的数据。这种数据提取技术常被用于市场调研、情感分析、竞争对手分析以及数据聚合等多种用途。
如果需要处理的数据量较小,用户可以通过简单的复制粘贴操作,将网页中的特定信息手动提取到电子表格或文档中。例如,当消费者希望通过在线评论来辅助其购买决策时,他们可以通过这种方式手动获取所需信息。
然而,当需要处理大规模数据集时,手动提取数据显然效率低下,此时就需要借助自动化的数据提取技术。用户可以选择构建内部数据提取方案,或者利用代理API或抓取API来完成任务。
值得注意的是,这些技术在某些情况下可能效果不佳,因为目标网站可能启用了验证码保护机制。此外,用户还需处理机器人检测和代理管理等问题。这些任务可能会耗费大量时间,并限制用户能够提取数据的范围和性质。
抓取浏览器:一种高效的解决方案
Bright Data 的抓取浏览器可以有效解决上述挑战。这款集成式浏览器能够帮助用户轻松采集那些难以抓取的网站数据。它基于图形用户界面(GUI)操作,并由Puppeteer或Playwright API驱动,使其不易被机器人检测到。
该抓取浏览器内置了解锁机制,可以自动处理所有拦截问题,例如验证码、IP封锁等。此外,该浏览器运行在 Bright Data 的服务器上,用户无需投入昂贵的内部基础设施即可完成大型数据抓取项目。
Bright Data 抓取浏览器的突出特点
- 自动网站解锁: 无需频繁刷新浏览器,该浏览器能自动适应各种挑战,包括验证码、IP封锁、指纹识别和重试机制。它模拟真实用户行为,减少被封锁的风险。
- 庞大的代理网络: 该抓取浏览器拥有超过7200万个IP地址,覆盖全球各地,用户可以精确定位到特定国家、城市甚至运营商,享受顶级的技术服务。
- 高度可扩展: Bright Data的基础设施支持同时开启数千个会话,满足大规模数据抓取的需求。
- 兼容 Puppeteer 和 Playwright: 该浏览器允许用户使用 Puppeteer (Python) 或 Playwright (Node.js) 进行API调用,轻松获取任意数量的浏览器会话。
- 节省时间和资源: 无需配置代理,抓取浏览器会在后台自动处理一切。同时,用户也无需搭建内部基础设施,该工具可独立处理所有任务。
如何设置抓取浏览器
- 访问 Bright Data 网站,在“Scraping Solutions”标签页下找到并点击“Scraping Browser”。
- 创建一个新账户。 您会看到两个选项:“开始免费试用”和“使用 Google 免费试用开始”。 选择“开始免费试用”并进入下一步。 您可以选择手动创建帐户,也可以使用您的 Google 帐户。
- 账户创建完成后,您将看到仪表板上的多个选项。请选择“代理和抓取基础设施”。
- 在新打开的窗口中,选择“Scraping Browser”,然后点击“开始”。
- 保存并激活您的配置。
- 激活您的免费试用。 第一个选项为您提供 5 美元的信用额度,可以用于代理使用。 请单击第一个选项进行试用。 如果您是重度用户,您也可以选择第二个选项,充值 50 美元或更多,即可免费获得 50 美元。
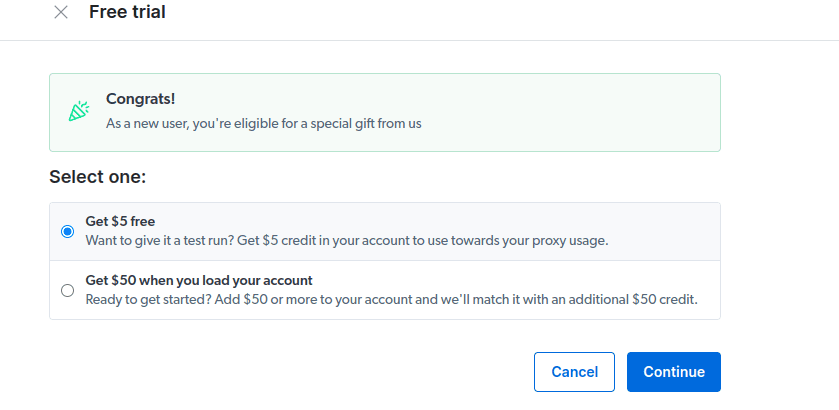
- 输入您的账单信息。请不必担心,因为该平台不会向您收费。 账单信息只是用来验证您是新用户,而非通过创建多个账户来获取免费额度。
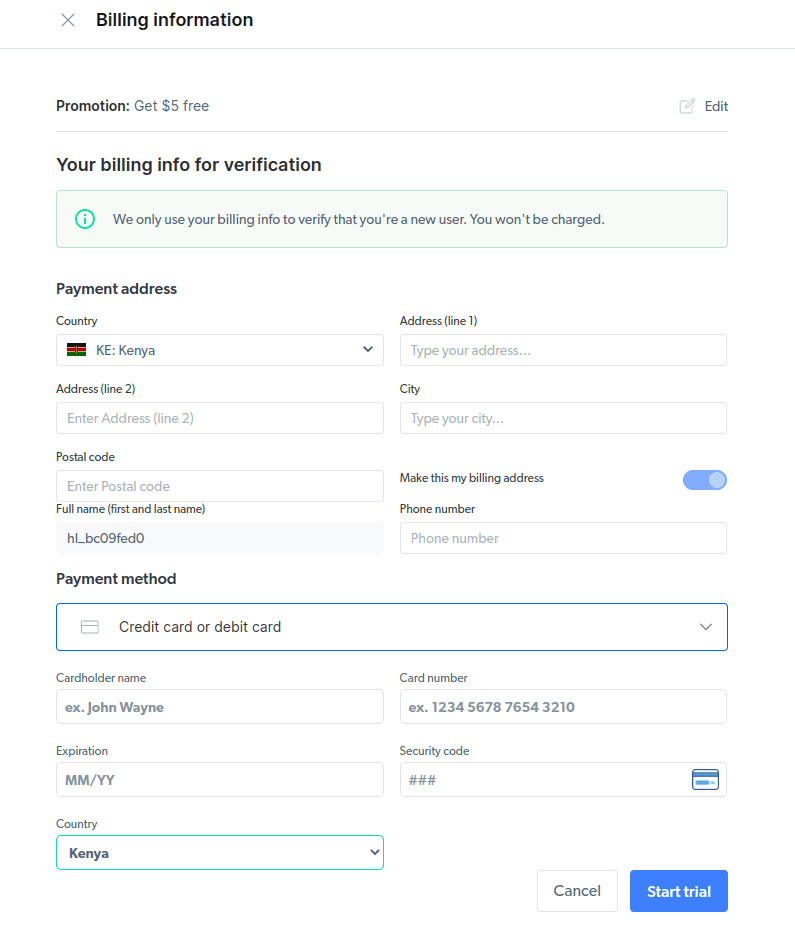
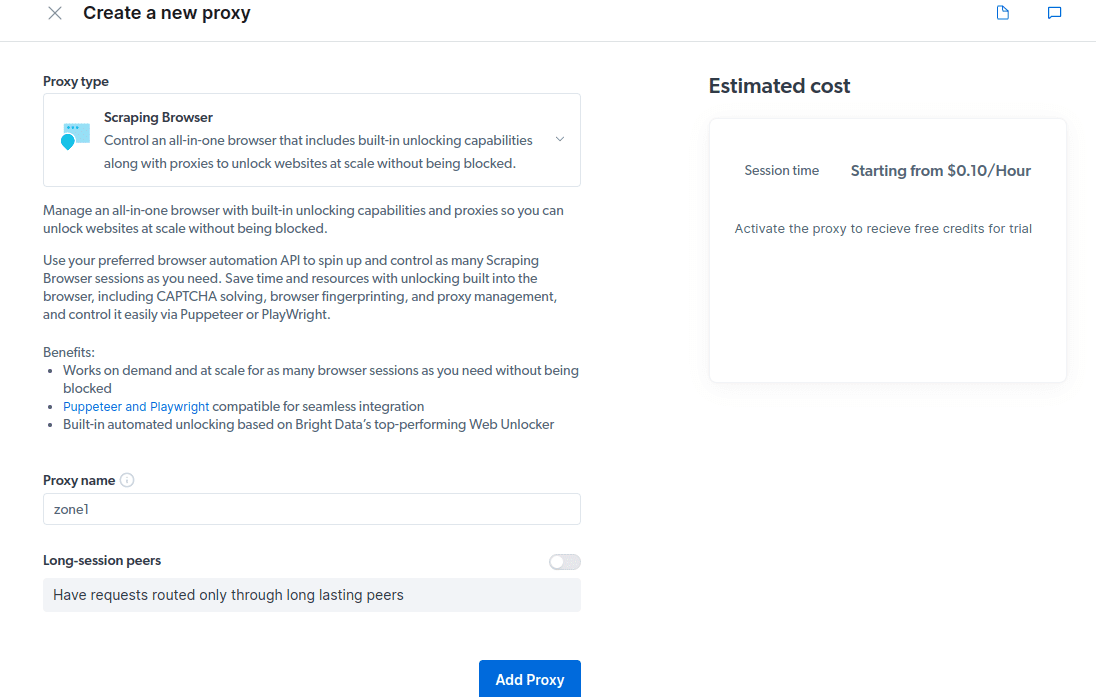
- 创建新的代理。 在保存账单信息后,您可以创建一个新的代理。 点击“添加”图标并选择“Scraping Browser”作为您的“代理类型”。 然后点击“添加代理”并继续下一步。
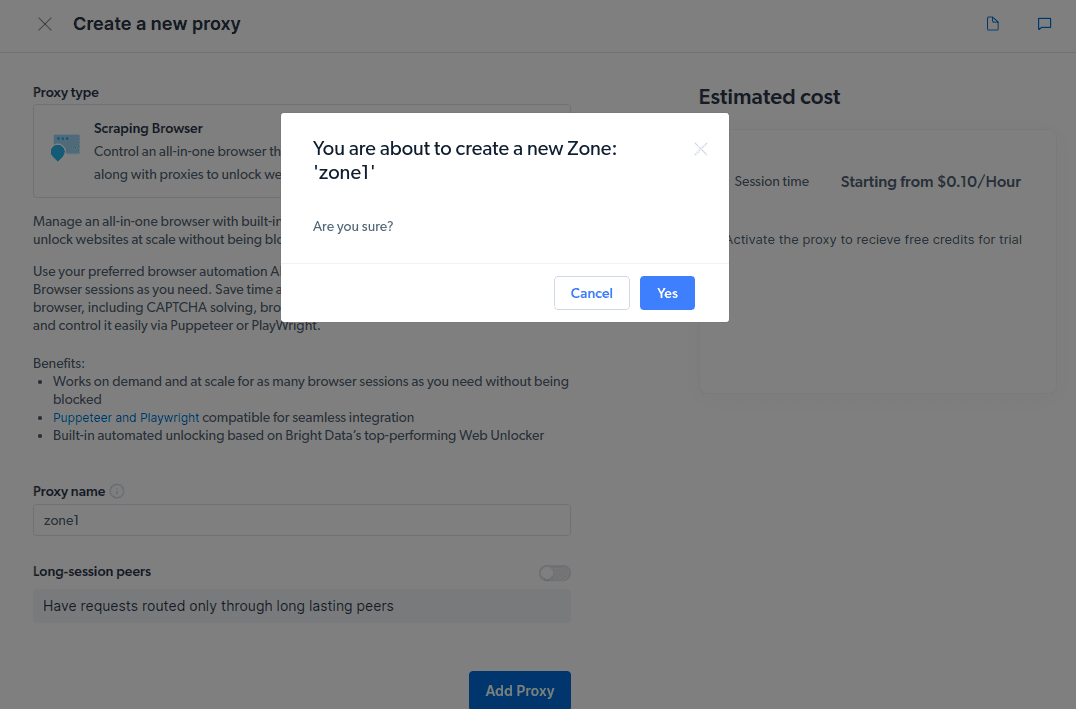
- 创建一个新的“区域”。 此时会弹出窗口,询问您是否要创建新的区域,请点击“是”继续。
- 点击“查看代码和集成示例”。 您现在可以获取代理集成示例,这些示例代码可用于从目标网站中抓取数据。 您可以使用 Node.js 或 Python 从目标网站提取数据。
现在您已经具备了从网站中提取数据所需的全部要素。接下来,我们将以 techblik.com.com 网站为例来演示抓取浏览器的工作原理。本示例将使用 Node.js 进行演示。如果您已经安装了 Node.js,那么就可以继续操作。
请按照以下步骤操作:
- 在您的本地机器上创建一个新的项目文件夹。进入该文件夹并创建一个名为 script.js 的文件。我们将在此本地运行抓取代码,并在终端显示抓取结果。
- 使用您偏好的代码编辑器打开项目,我这里使用 VsCode。
- 安装木偶师(puppeteer)。 请使用以下命令:
npm i puppeteer-core - 将下列代码添加到 script.js 文件中:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
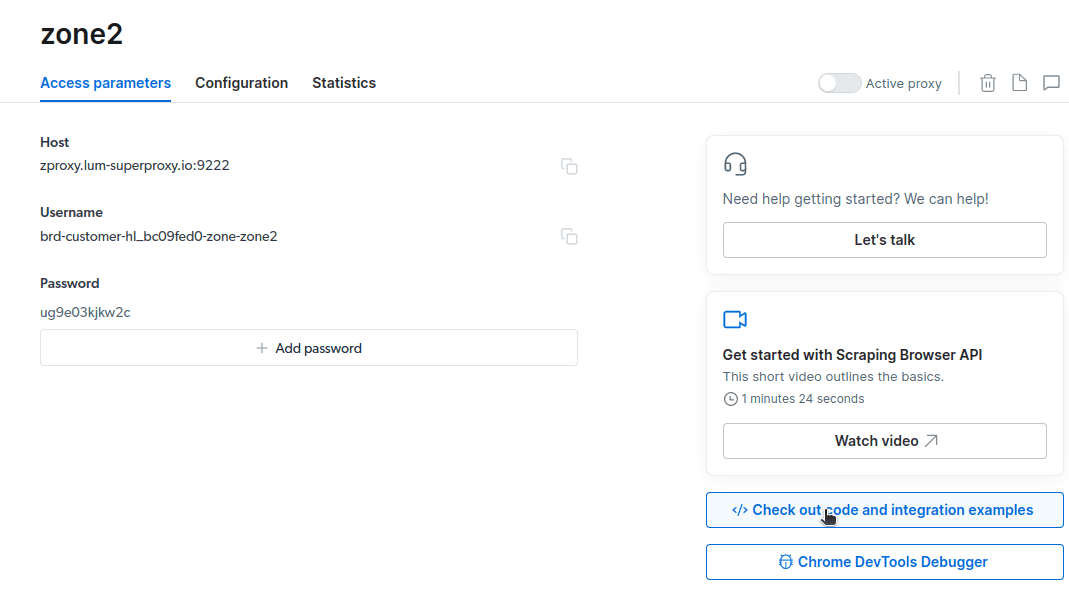
const auth='USERNAME:PASSWORD'; 中的内容替换为您账户的详细信息。您可以在“访问参数”选项卡中找到您的用户名、区域名和密码。我将第10行代码修改如下:
await page.goto('https://techblik.com.com/authors/');
我最终的代码如下:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://techblik.com.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
运行结果将类似如下:
如何导出数据
您可以使用多种方法导出数据,具体取决于您计划如何使用它。本例中,我们通过修改脚本将数据导出到一个名为 data.html 的新文件中,而不是直接在控制台打印输出。
您可以修改代码如下:
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://techblik.com.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
现在使用以下命令运行代码:
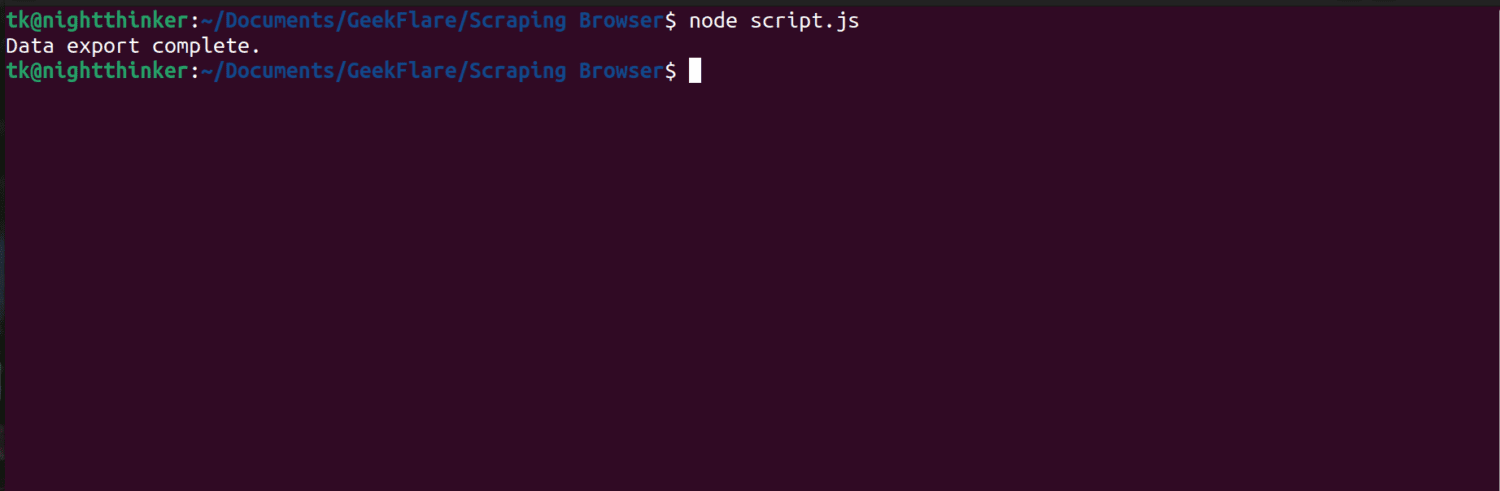
node script.js
如您在下面的截图中看到,终端会显示“数据导出完成”的消息。
现在查看项目文件夹,可以看到一个名为 data.html 的文件,其中包含了抓取到的数千行代码。
以上只是对使用抓取浏览器提取数据的一个粗略介绍。您甚至可以使用该工具进行更精确的定位,例如仅提取作者的姓名和描述。
要使用抓取浏览器,请先确定要提取的数据集,并相应地修改代码。您可以提取文本、图片、视频、元数据和链接等内容,具体取决于目标网站和 HTML 文件的结构。
常见问题解答
数据提取和网络抓取是否合法?
网络抓取是一个备受争议的话题。有人认为它不道德,而其他人则认为它是可以接受的。网络抓取的合法性取决于被抓取内容的性质和目标网页的政策。一般而言,抓取包含个人信息的(如地址、财务信息)数据是被认为是非法的。在抓取数据之前,请查看目标网站的任何相关指南。务必确保您不会抓取那些非公开的数据。
抓取浏览器是免费工具吗?
不是的。抓取浏览器是一项付费服务。注册免费试用版后,该工具会为您提供5美元的信用额度。付费套餐的起价为15美元/GB+0.1美元/小时。您也可以选择按需付费的选项,起价为20美元/GB+0.1美元/小时。
抓取浏览器和无头浏览器有什么区别?
抓取浏览器是一款有头浏览器,这意味着它具有图形用户界面(GUI)。而无头浏览器则没有图形界面。Selenium等无头浏览器主要用于自动化网页抓取,但有时会受到验证码和机器人检测等问题的限制。
总结
如您所见,抓取浏览器简化了从网页中提取数据的过程。与Selenium等工具相比,抓取浏览器更易于使用。即使是非开发人员也可以使用这个具有出色用户界面和良好文档的浏览器。该工具具有其他抓取工具不具备的解锁功能,使其对所有希望自动化此类流程的用户都非常有效。
此外,您还可以了解如何阻止 ChatGPT 插件抓取您的网站内容。