利用Bash脚本解析Reddit的JSON数据
Reddit 为每个子版块提供了JSON数据接口。本文将介绍如何使用 Bash 脚本从您感兴趣的任何子版块下载并解析帖子列表。这只是您可以利用 Reddit JSON 数据接口实现的众多功能之一。
安装 Curl 和 JQ
我们将使用 curl 从 Reddit 获取 JSON 数据,并使用 jq 来解析 JSON 数据并提取所需的字段。 在基于 Debian 的 Linux 发行版(如 Ubuntu)上,可以使用 apt-get 安装这两个工具。 如果您使用的是其他 Linux 发行版,请使用发行版自带的包管理器进行安装。
sudo apt-get install curl jq
从Reddit获取JSON数据
首先,我们来了解一下数据接口返回的数据是什么样的。使用 curl 从 /r/MildlyInteresting 子版块获取数据:
curl -s -A "我的 Reddit 爬虫示例" https://www.reddit.com/r/MildlyInteresting.json
注意上述命令中 URL 前的选项:-s 选项使 curl 在静默模式下运行,这意味着我们只看到来自 Reddit 服务器的数据,而不会有其他输出。 -A "我的 Reddit 爬虫示例" 选项则设置了一个自定义的用户代理字符串,以便 Reddit 能够识别访问其数据的服务。Reddit API 服务器会根据用户代理字符串应用速率限制。设置自定义值有助于将我们的速率限制与其他调用者分开,从而减少收到 HTTP 429 速率限制错误的概率。
输出结果会充满整个终端窗口,看起来类似如下:
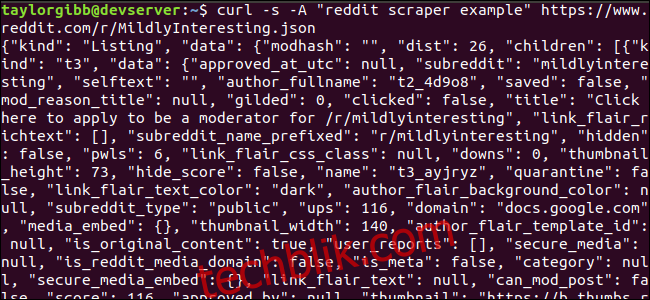
返回的数据中包含许多字段,但我们只对 标题、永久链接 和 URL 感兴趣。您可以在 Reddit 的 API 文档页面上找到类型及其字段的完整列表:https://github.com/reddit-archive/reddit/wiki/JSON
从JSON数据中提取所需信息
我们的目标是从 JSON 输出中提取标题、永久链接和 URL,并将它们保存到一个制表符分隔的文件中。 虽然可以使用 sed 和 grep 等文本处理工具来完成此任务,但我们还有另外一个可以理解 JSON 数据结构的工具,即 jq。 让我们首先尝试使用 jq 对输出进行美化打印和着色。 使用和之前相同的 curl 命令,并通过管道将输出传递给 jq,让它解析和打印 JSON 数据。
curl -s -A "我的 Reddit 爬虫示例" https://www.reddit.com/r/MildlyInteresting.json | jq .
注意命令末尾的句点 .,它表示解析输入并按原样输出。 现在的输出格式良好且颜色丰富。
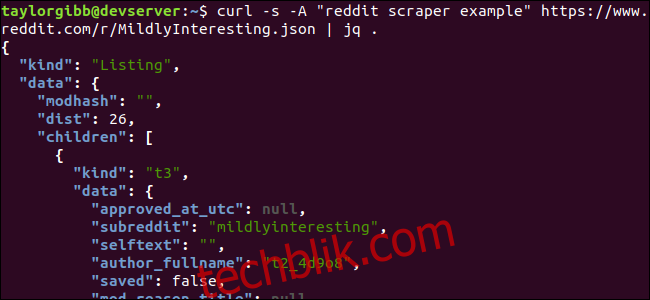
让我们分析一下从 Reddit 返回的 JSON 数据的结构。 根结果是一个包含两个属性的对象:种类和数据。 其中,数据属性有一个名为 children 的属性,它是一个包含该子版块所有帖子的数组。
数组中的每个元素都是一个对象,同样包含两个属性:kind 和 data。 我们要抓取的属性在 data 对象中。 jq 需要一个能够应用于输入数据并生成所需输出的表达式。 该表达式必须描述数组的层次结构和成员,以及应该如何转换数据。 现在让我们使用正确的表达式重新运行整个命令:
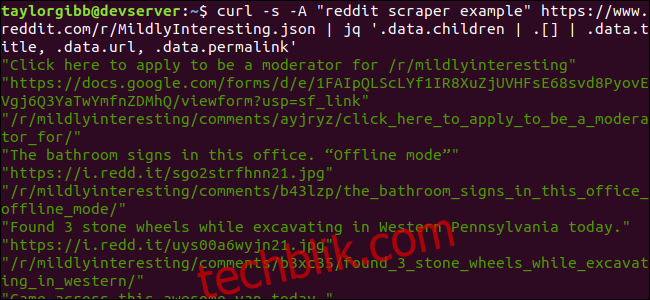
curl -s -A "我的 Reddit 爬虫示例" https://www.reddit.com/r/MildlyInteresting.json | jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
输出将显示标题、URL 和永久链接,每一项各占一行。
让我们深入了解一下我们调用的 jq 命令:
jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
该命令包含三个表达式,通过两个管道符号分隔。 每个表达式的结果都会被传递给下一个表达式进行进一步处理。 第一个表达式过滤掉除 Reddit 帖子数组之外的所有内容。 该输出通过管道传输到第二个表达式,该表达式强制输入为一个数组。 第三个表达式作用于数组中的每个元素,并提取三个属性。 有关 jq 及其表达式语法的详细信息,请参阅jq官方手册。
整合所有内容到脚本中
现在,我们将 API 调用和 JSON 数据处理整合到一个脚本中,该脚本将生成一个包含所需帖子的文件。 我们将添加对从任何子版块获取帖子的支持,而不仅限于 /r/MildlyInteresting。
打开您的编辑器,并将以下代码复制到一个名为 scrape-reddit.sh 的文件中:
#!/bin/bash
if [ -z "$1" ]
then
echo "请指定一个子版块"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete '"' >> ${OUTPUT_FILE}
done
此脚本首先检查用户是否提供了子版块名称。 如果没有,它将输出错误消息并以非零返回码退出。
接下来,它将第一个参数存储为子版块名称,并创建一个带有时间戳的文件名,用于保存输出。
当使用自定义标头和要抓取的子版块的 URL 调用 curl 时,该操作开始。 输出通过管道传递给 jq,在那里它被解析并简化为三个字段:标题、URL 和永久链接。 这些行一次读取,并使用 read 命令保存到变量中。所有这些操作都在一个 while 循环内完成,直到没有更多行可读取。 内部 while 循环的最后一行回显三个字段,它们由制表符分隔,然后通过 tr 命令管道传输,以便删除双引号。 最后将输出附加到文件中。
在执行此脚本之前,我们需要确保它具有执行权限。 使用 chmod 命令为文件添加这些权限:
chmod u+x scrape-reddit.sh
最后,使用子版块名称执行脚本:
./scrape-reddit.sh MildlyInteresting
将在同一目录中生成一个输出文件,其内容如下所示:
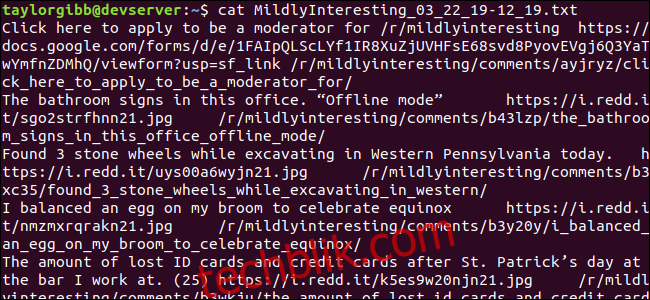
每行包含我们需要的三个字段,它们用制表符分隔。
更进一步
Reddit 是一个拥有丰富有趣内容和媒体的宝库。使用其 JSON API 可以轻松访问所有内容。现在您已经有了访问这些数据并处理结果的方法,您可以执行以下操作:
- 从 /r/WorldNews 获取最新的头条新闻,并将它们发送到您的桌面通知系统。 通知发送
- 将 /r/DadJokes 中的最佳笑话集成到您的系统的每日消息中。
- 从 /r/aww 获取今日最佳图片,并将其设置为桌面背景。
所有这一切都可以使用您现在掌握的数据和系统工具来实现。祝您编程愉快!