在 Linux 系统中,`free` 命令可以显示计算机内存的使用情况,包括已用内存和可用内存。 对于新手用户来说,`free` 命令的输出结果可能有些难以理解。 本文将详细介绍如何解读 `free` 命令的输出,帮助你更好地了解系统内存的使用状况。
`free` 命令详解
`free` 命令会在终端窗口中快速打印内存的使用情况摘要。 它并没有过多的选项,学习如何使用它并不复杂。 然而,要真正理解它所提供的信息,则需要一定的知识背景。 很多人容易被 `free` 命令的输出所迷惑。
这种困惑部分源于一些术语,比如“free”(空闲)和“available”(可用)之间的区别。 部分原因还在于 Linux 内核对内存和文件系统的管理机制。 如果有空闲内存,内核会将其用于自身目的,直到你需要再次使用它。
接下来,我们将深入探讨这些底层机制和数据处理流程,以便你了解系统后台的运作方式,以及它们如何影响你的随机存取存储器(RAM)的使用。
`free` 命令的列
让我们在不使用任何选项的情况下执行 `free` 命令,看看会得到什么:
free

这样的输出可能看起来不太直观。 如果你的终端窗口足够宽,输出会更加清晰。 以下是一个更规范的表格输出:
total used free shared buff/cache available Mem: 2038576 670716 327956 14296 1039904 1187160 Swap: 1557568 769096 788472
这些数值的单位是千字节 (KiB),即 1024 字节。 在 Manjaro 发行版中,`free` 命令被别名为 `free -m`。 这会强制 `free` 命令使用兆字节 (MiB),即 1,048,576 字节。 在其他发行版中,默认单位是千字节。
表格的第一行显示了系统内存的使用情况,第二行显示了交换空间的使用情况。 下面将详细介绍每一列的含义。内存行的列包括:
total: 计算机中安装的物理 RAM 总量。
used: 已使用的内存量,计算方法为 Total – (Free + Buffers + Cache)。
free: 未被使用的内存量。 为什么不是 Total = Used + Free 呢? 我们稍后会解释。
shared: `tmpfs` 文件系统使用的内存。
buff/cache: 用于缓冲区和缓存的内存。
available: 这是一个对可用于满足应用程序内存请求的内存的估计,以及计算机中其他软件(例如你的图形桌面环境和 Linux 命令)所需的内存。
对于交换空间行,列的含义如下:
total: 交换分区或交换文件的大小。
used: 正在使用的交换空间量。
free: 剩余(未使用的)交换空间。
使用宽屏显示
要将 “Buff/cache” 列分解为 “Buffers” 和 “Cache” 两个单独的列,可以使用 `-w` (wide) 选项:
free -w
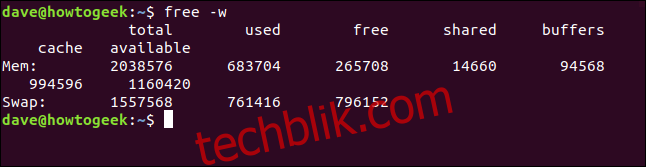
这是运行结果。 现在我们看到了 “Buffers” 和 “Cache” 两列,而不是原来的 “Buff/cache” 列。 如下是表格的数值:
total used free shared buffers cache available Mem: 2038576 683724 265708 14660 94568 994596 1160420 Swap: 1557568 761416 796152
接下来,我们来分析一下每列数据的含义。
`total` 列
这是最简单的一列,它表示安装在主板上的 RAM 总量,是所有正在运行的进程争夺的宝贵资源。 如果内核没有做好管理,这些进程可能会为了内存资源而发生冲突。
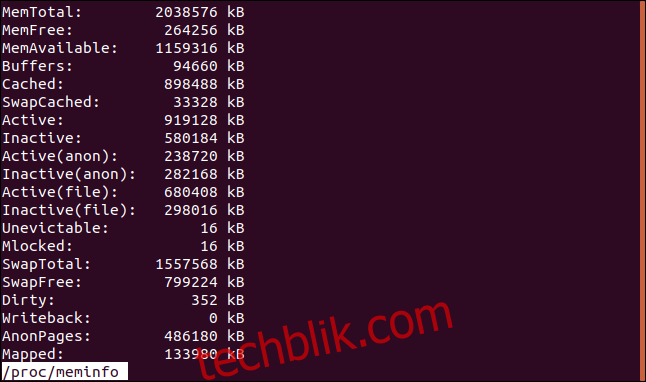
实际上,`free` 命令是从 `/proc/meminfo` 伪文件中获取信息的。 你可以使用以下命令查看此文件:
less /proc/meminfo

输出结果是一个名称和值的列表。
`used` 列
这一列的含义开始变得有趣起来。
“used” 列的数值不仅表示你所期望的,还有其他的一些含义。 它包括分配给进程的内存、用户程序占用的内存以及桌面环境(例如GNOME或KDE)所使用的内存。 这部分并没有什么意外。 但它也包括 “Buffers” 和 “Cache” 列的数值。
未被使用的 RAM 是一种浪费。 内核会使用空闲的 RAM 来存储缓存和缓冲区,以提高系统运行效率。 因此,这部分 RAM 被内核用于自身目的,而不是被用户空间的程序使用。
如果内核收到内存请求,需要释放一些它自己使用的 RAM,这个过程是无缝完成的。 释放这些 RAM 并将其用于其他应用程序不会影响 Linux 系统的正常运行。 它可能只会影响系统的性能。
所以这一列的真正含义是“所有被使用的 RAM,即使它可以立即被回收”。
`free` 列
此列包含的是完全未被任何进程使用的 RAM 量。 由于 “Used” 列包含了 “Buffers” 和 “Cache” 的数值,因此对于一个正常运行的 Linux 系统来说,很少有 RAM 会被列为“空闲”。
这不一定是坏事,很可能表明你有一个正常运行的系统,RAM 使用率处于良好的调节状态。 也就是说,RAM 不仅被应用程序和其他用户空间进程使用,也被内核使用,目的是让你的计算机性能尽可能好。
`shared` 列
“Shared” 列表示专门用于存储 基于 RAM 的文件系统(`tmpfs`)的内存。 `tmpfs` 是在内存中创建的文件系统,目的是提高操作系统的运行效率。 你可以使用 `df` 命令来查看系统中有哪些 `tmpfs` 文件系统。
我们使用的选项是:
`-h` (human-readable):使用更易读的单位显示结果。
`–total`:在输出结果底部显示一行总计。
`–type=tmpfs`:只显示 `tmpfs` 文件系统。
df -h --total --type=tmpfs

当你查看这些值时,可能会发现它们比 “shared” 列中的数值大很多倍。 这里显示的大小是这些文件系统的最大大小。 实际上,它们每个只占用所需的内存。 “Shared” 列中的数值才代表实际的内存使用情况。
这些文件系统包含哪些内容? 下面是一个简单的细分:
/run:包含许多临时文件,例如PID 文件、systemd日志(无需在重启后保留)、Unix 域套接字、先进先出以及用于管理守护进程的相关信息。
/dev/shm:允许在Debian和基于 Debian 的 Linux 发行版上执行POSIX 标准内存管理。
/run/lock:保存锁定文件。 这些文件作为指示器,让系统知道某个文件或其他共享资源正在被使用。 它们包含使用该资源的进程的 PID。
/sys/fs/cgroup:这是管理控制组的核心元素。 进程根据它们使用的资源类型被组织成层级结构。 这使得可以监控和限制进程对资源的使用。
/run/user/121:这是一个由`pam_systemd`为用户存储临时文件的目录。 在这种情况下,用户的 ID 为 121。“用户”可能是普通用户、守护进程或其他进程。
/run/user/1000:这是一个由`pam_systemd`为用户存储临时文件的目录,用户的用户 ID 为 1000。 这是当前用户的目录,用户名为 dave。
`buffers` 和 `cache` 列
只有当你使用 `-w` (wide) 选项时,“buffers” 和 “cache” 列才会出现。 如果不使用 `-w` 选项,这两列的数值将会被合并到 “Buff/cache” 列中。
这两个内存区域相互关联,并且彼此依赖。 缓存区(Cache)保存的是从硬盘读取的数据。 这些数据会被保留,以便在再次需要时可以快速访问。 从缓存中读取数据比从硬盘驱动器中读取数据要快得多。 缓存还可以保存已修改但尚未写回硬盘驱动器的数据,或已计算但尚未保存到文件的值。
为了跟踪各种文件片段和数据存储,内核在缓冲区(Buffers)内存区域中为缓存(Cache)内存区域建立索引。 缓冲区是内存的一部分,它保存磁盘块和其他信息结构。 这些结构包含有关保存在高速缓存内存区域中的数据的信息。 所以,缓冲区是缓存的元数据。
当发出文件读取请求时,内核会读取缓冲区数据结构中的数据,以查找请求的文件或文件片段。 如果找到了,则从缓冲区数据结构指向的高速缓存内存区域中读取请求的数据。 如果缓存中没有所需数据,那么就从硬盘驱动器中读取该文件。
缓冲区存储区域中的结构包括:
缓冲区头:每个缓冲区都在一个名为缓冲区头的数据块中。 此外,如果块中的数据发生更改,并且相关的内存页面“变脏”,描述符会记录需要将数据写回硬盘驱动器的信息。
索引节点:索引节点保存有关文件和目录的元数据,包括它们在硬盘驱动器(或虚拟文件系统)上的位置、文件大小和文件的时间戳。
Dentries:一个dentry(目录条目)是一个用于保存目录列表信息的结构。 可以把它们看作是目录中文件和目录的 inode 列表。
现在应该可以理解为什么将缓冲区和缓存内存区域压缩成一个 “Buff/cache” 列是有意义的。 它们就像同一事物的两个部分。 如果没有缓冲存储区为缓存内容提供索引,那么缓存存储区就没有任何用处。
`available` 列
“available” 列是 “free” 列加上 “buffers” 和 “cache” 列(或 “Buff/cache” 列)中可以立即释放的部分之和。 “available” 列是一个估计值,而不是一个精确的数字。 这是一个有根据的估计,但是不应该把它看作是精确到最后一个字节的数值。
改变显示单位
要改变 `free` 命令显示数值的单位,可以使用以下选项:
`-b`:以字节为单位显示数值。
`-k`:以千字节为单位显示数值(默认值)。
`-m`:以 MiB (mebibytes) 为单位显示数值。
`-g`:以 GiB (gibibytes) 为单位显示数值。
`-h`:使用最合适的、易于阅读的单位显示数值。
例如,要使用易于阅读的单位,可以使用 `-h` 选项:
free -h
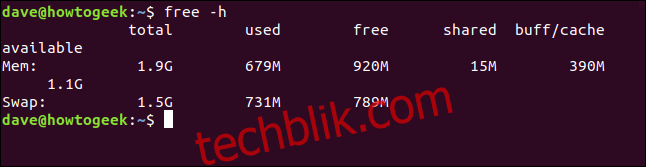
`free` 命令会为每个数值选择最合适的单位。 如你所见,一些数值以 MiB 为单位显示,一些数值以 GiB 为单位显示。
显示总计
`–total` 选项会使 `free` 命令显示一个总计行,该行对 “Mem” 和 “Swap” 行的 “Total”、“Used” 和 “Free” 列的值进行求和。
free -h --total
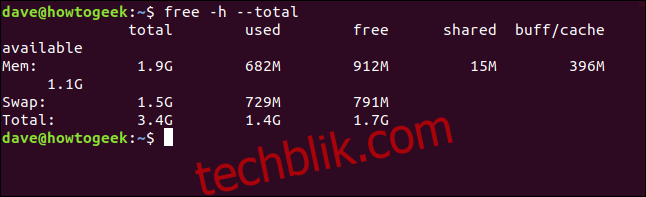
`count` 选项
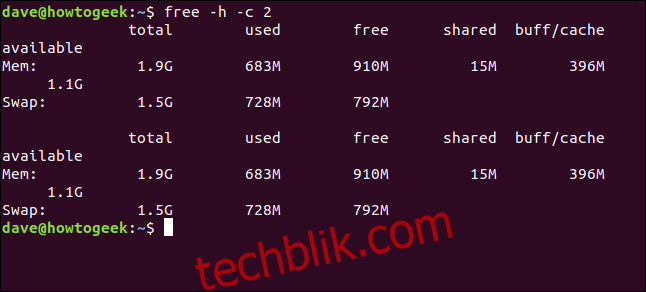
`-c` (count) 选项用于指定 `free` 命令的运行次数,每次运行之间暂停一秒钟。 要让 `free` 命令运行两次,可以使用以下命令:
free -h -c 2
持续运行 `free` 命令
如果你想查看某个应用程序对内存使用量的影响,连续运行 `free` 命令会很有用。 这样,你就可以在启动、使用和关闭正在调查的应用程序时,在终端窗口中查看内存使用情况。
`-s` (seconds) 选项用于指定每次运行 `free` 命令之间的暂停时间。 要让 `free` 命令持续运行,每次更新之间暂停 3 秒,可以使用以下命令:
free -s 3
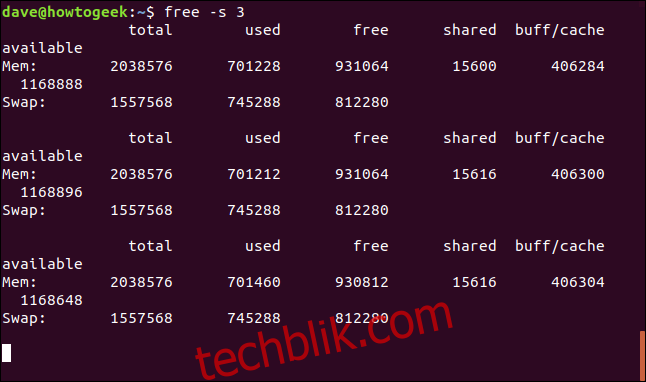
按 `Ctrl+C` 可以停止进程并返回到命令提示符。
结合使用 `count` 和 `seconds` 选项
要指定每次更新之间的暂停时间,并且在指定次数的报告之后停止 `free` 命令的运行,可以结合使用 `-s` (seconds) 和 `-c` (count) 选项。 要让 `free` 命令每次更新之间暂停 2 秒,并且运行 5 次,可以使用以下命令:
free -s 2 -c 5
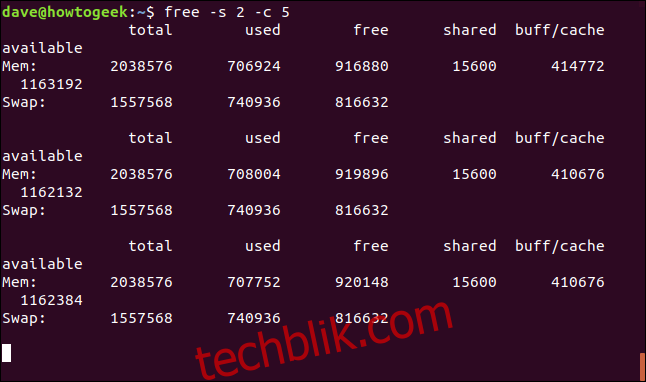
在显示了 5 次更新之后,该进程会自动终止,你会返回到命令提示符。

分离低内存和高内存
现在,这个功能可能用处不大。但是,如果你在 32 位计算机上运行 Linux,它可能会很有用。它可以将内存使用情况分为低内存和高内存。
在 32 位 Linux 系统上,CPU 最多可以寻址 4GB 的内存。 内存分为低内存和高内存。 低内存直接映射到内核的部分地址空间。 高内存没有直接的内核映射。 通常,高内存高于 896MB。
这意味着内核本身(包括其活动的模块)只能使用低内存。 用户进程(任何不是内核本身的东西)可以使用低内存和高内存。
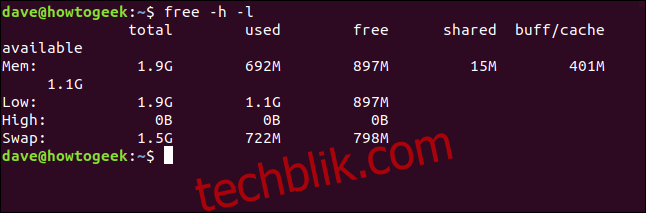
在 64 位计算机上,不会显示高内存的值:
free -h -l
总结
快速回顾一下:
| total | 系统中安装的 RAM 总量。 |
| used | 等于 Total – (Free + Buffers + Cache)。 |
| free | 完全未被任何进程使用的内存量。 |
| shared | `tmpfs` 文件系统占用的内存。 |
| buffers | 为存储在缓存中的所有内容提供索引而维护的数据结构。 |
| cache | 从硬盘读取的数据、等待写回硬盘的修改数据以及其他计算值。 |
| available | 真正的可用内存。它是 Free、Buffer 和 Cache 中可用于满足内存请求的估计值。 |