在 AWS S3 存储桶中自动化访问权限编排
多年前,在本地 Unix 服务器盛行,并配备大型文件系统的时候,各大公司纷纷制定了详尽的文件夹管理规则和策略,以控制不同人员对不同文件夹的访问权限。
通常,一个组织的平台会服务于具有截然不同利益、机密级别限制或内容定义的不同用户群体。对于跨国组织而言,这甚至可能意味着要根据地理位置来隔离内容,基本上是在属于不同国家/地区的用户之间分隔内容。
其他常见的例子包括:
- 开发、测试和生产环境之间的数据隔离
- 营销内容不应向公众开放
- 特定国家/地区的法规内容无法被其他地区的用户查看或访问
- 与项目相关的内容,例如“领导力数据”仅限于少数人访问等。
这样的例子不胜枚举。关键在于,始终需要在所有访问平台的各个用户之间协调文件和数据的访问权限。
对于本地解决方案,这是一项常规任务。文件系统管理员只需设置一些规则,使用选定的工具,然后将人员映射到用户组,而用户组又映射到他们应该能够访问的文件夹列表或挂载点。在此过程中,访问级别被定义为只读或读写访问。
现在,看看 AWS 云平台,很明显,人们对内容访问限制有着类似的要求。但是,现在解决这个问题的方法必须有所不同。文件不再存储在 Unix 服务器上,而是存在于云端(不仅整个组织,甚至全世界都有可能访问),并且内容不再存储在文件夹中,而是存储在 S3 存储桶中。

下面描述的是解决此问题的替代方案。它基于我为具体项目设计此类解决方案的实际经验。
简单但高度手动的方法
在没有任何自动化的情况下解决此问题的一种方法相对简单直接:
- 为每个不同的人群创建一个新的存储桶。
- 分配对存储桶的访问权限,以便只有该特定组才能访问该 S3 存储桶。
如果需要一个非常简单和快速的解决方案,这当然是可行的。但是,需要注意一些限制。
默认情况下,一个 AWS 账户下最多只能创建 100 个 S3 存储桶。通过向 AWS 提交服务限制增加的请求,可以将此限制扩大到 1000 个。如果这些限制不是您特定实施案例所担心的,那么您可以允许每个不同的域用户在单独的 S3 存储桶上操作,然后就可以完成任务。
如果某些人具有跨职能职责,或者只是某些人需要同时访问更多域的内容,则可能会出现问题。例如:
- 数据分析师评估来自几个不同领域、地区等的数据内容。
- 测试团队共享服务于不同开发团队的服务。
- 报告用户需要在同一区域内的不同国家/地区之上构建仪表板分析。
正如您可能想象的那样,这个列表可以无限扩展,并且组织的需求可能会产生各种各样的用例。
此列表越复杂,就需要更复杂的访问权限编排,以便向所有不同的组授予对组织中不同 S3 存储桶的不同访问权限。将需要额外的工具,甚至可能需要专门的资源(管理员)来维护访问权限列表,并在任何更改请求时更新它们(这将非常频繁,尤其是在组织规模庞大的情况下)。
那么,如何以更系统和自动化的方式实现同样的事情呢?
如果每个域的存储桶方法不可行,那么任何其他解决方案最终都会让更多用户组共享存储桶。在这种情况下,有必要在一些易于动态更改或更新的区域构建分配访问权限的整个逻辑。
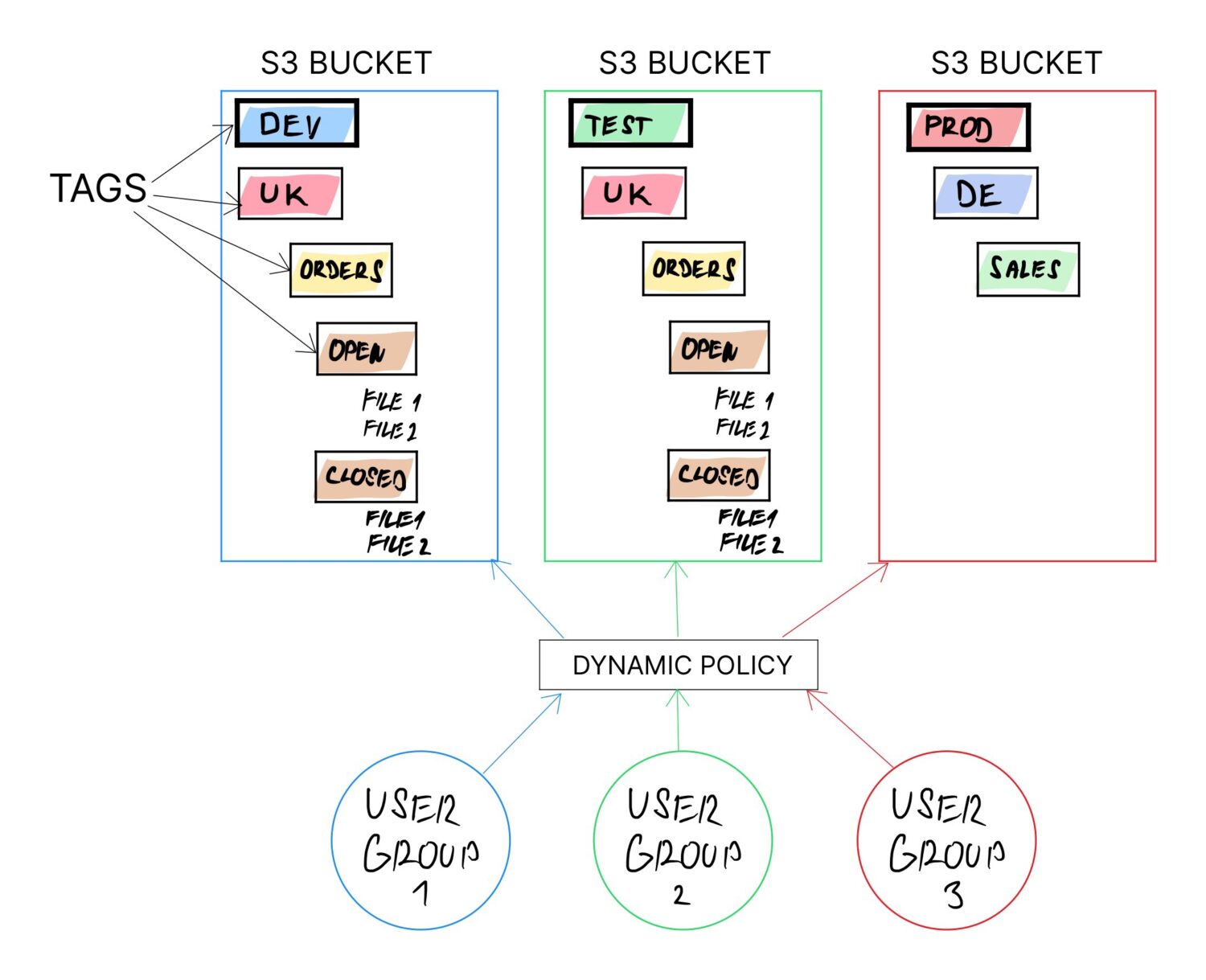
实现此目标的一种方法是在 S3 存储桶上使用标签。建议在任何情况下都使用这些标签(哪怕只是为了更轻松地进行计费分类)。而且,将来可以随时更改任何存储桶的标签。
如果整个逻辑是基于存储桶标签构建的,并且后续的其余部分依赖于标签值配置,那么动态属性就得到了保证,因为只需更新标签值就可以重新定义存储桶的用途。
使用什么类型的标签来完成这项工作?
这取决于您的具体用例。例如:
- 可能需要将每种环境类型的存储桶分开。因此,在这种情况下,一个标签名称应类似于“ENV”,并且可能具有诸如“DEV”、“TEST”、“PROD”之类的值。
- 也许您希望根据国家/地区来区分团队。在这种情况下,另一个标签将是“COUNTRY”,并为某个国家/地区名称赋值。
- 或者您可能希望根据用户所属的职能部门来区分用户,例如业务分析师、数据仓库用户、数据科学家等。因此,您将创建一个名为“USER_TYPE”且具有相应值的标签。
- 另一种选择可能是您希望为他们需要使用的特定用户组明确定义一个固定的文件夹结构(以避免他们创建自己的文件夹混乱,并随着时间的推移迷失在其中)。您可以使用标签再次执行此操作,您可以在其中指定几个工作目录,例如:“data/import”、“data/processed”、“data/error”等。
理想情况下,您希望定义标签,使其能够进行逻辑组合,并在存储桶上形成完整的文件夹结构。
例如,您可以组合上面示例中的以下标签,为来自不同国家/地区的各种类型的用户构建专用文件夹结构,并预定义他们将使用的导入文件夹:
- /
/ / /
只需更改 <ENV> 的值,即可重新定义标签的用途(是否分配给测试环境、开发环境、生产环境等)。
这将使许多不同的用户能够使用同一个存储桶。存储桶本身并不直接支持文件夹,但它们支持“标签”。这些标签最终充当子文件夹,因为用户需要通过一系列标签才能访问他们的数据(就像他们对子文件夹所做的那样)。
在以某种可用的形式定义标签之后,下一步是构建将使用标签的 S3 存储桶策略。
如果策略使用标签名称,那么您正在创建所谓的“动态策略”。这基本上意味着您的策略对于具有策略在表单或占位符中引用的不同标签值的存储桶将会有不同的行为。
此步骤显然涉及一些动态策略的自定义编码,但是您可以使用 Amazon AWS 策略编辑器工具来简化此步骤,它将指导您完成整个过程。
在策略本身中,您需要编写应用于存储桶的特定访问权限以及此类权限的访问级别(读、写)。该逻辑将读取存储桶上的标签,并构建存储桶上的文件夹结构(根据标签创建标签)。根据标签的具体值,将创建子文件夹,并分配相应的访问权限。
这种动态策略的好处是,您可以只创建一个动态策略,然后将完全相同的动态策略分配给许多存储桶。对于具有不同标签值的存储桶,此策略的行为会有所不同,但它始终符合您对具有此类标签值的存储桶的期望。
这是一种真正有效的方法,可以以有组织和集中的方式为大量的存储桶管理访问权限分配,同时期望每个存储桶都遵循一些预先商定的模板结构,并供您的用户在整个组织中使用。
自动化新实体的加入
在定义动态策略并将其分配给现有存储桶后,用户可以开始使用相同的存储桶,而不会出现来自不同组的用户无法访问位于他们没有权限访问的文件夹结构下的内容(存储在同一存储桶中)的风险。
此外,对于一些具有更广泛访问权限的用户组,可以很容易地访问数据,因为它们都存储在同一个存储桶中。
最后一步是让新用户、新存储桶甚至新标签的加入尽可能简单。 这就需要另外一些自定义编码,但是,它不需要过于复杂,假设您的加入流程有一些非常明确的规则,可以使用简单、直接的算法逻辑来封装(至少您可以通过这种方式证明您的流程具有一定的逻辑,而不是以一种过于混乱的方式完成的)。
这可以像通过 AWS CLI 命令创建一个可执行脚本一样简单,其中包含成功将新实体加入平台所需的参数。它甚至可以是一系列 CLI 脚本,可以按特定顺序执行,例如:
- create_new_bucket(<ENV>,<ENV_VALUE>,<COUNTRY>,<COUNTRY_VALUE>, ..)
- create_new_tag(<bucket_id>,<tag_name>,<tag_value>)
- update_existing_tag(<bucket_id>,<tag_name>,<tag_value>)
- create_user_group(<user_type>,<country>,<env>)
- 等等
您明白了。 😃
专业提示👨💻
如果您愿意,可以使用一个专业提示,它可以很容易地应用于上述方法。
动态策略不仅可以用于分配文件夹位置的访问权限,还可以自动分配存储桶和用户组的服务权限!
所需要做的就是扩展存储桶上的标签列表,然后添加动态策略访问权限,以便为具体的用户组使用特定的服务。
例如,可能有一些用户组也需要访问特定的数据库集群服务器。这绝对可以通过利用存储桶任务的动态策略来实现,如果对服务的访问是通过基于角色的方法驱动的,则更是如此。只需向动态策略代码添加一个部分,该部分将处理有关数据库集群规范的标签,并将策略访问权限直接分配给特定的数据库集群和用户组。
这样,新用户组的加入将仅通过此单一动态策略执行。此外,由于它是动态的,因此可以重复使用相同的策略来引导许多不同的用户组(前提是它们遵循相同的模板,但不一定是相同的服务)。
您还可以查看这些 AWS S3 命令来管理存储桶和数据。