网络数据抓取是一种高效且迅速的方式,可以从互联网上搜集海量信息。 当网站未能通过应用程序编程接口(API)以结构化的方式对外公开其数据时,这种技术尤为重要。
举例来说,假设您正在开发一款应用程序,用于比较不同电商网站上的商品价格。 您会如何实现呢? 一种方法是亲自手动浏览各个网站,记录商品价格。 然而,这种方法效率低下,因为电商平台上的商品种类繁多,手动提取数据耗时过长。
更佳的解决方案是使用网页抓取技术。 网页抓取是通过软件自动从网页和网站提取数据的过程。
被称为网络爬虫的软件脚本负责访问网站并从中获取数据。 提取的数据通常以非结构化形式呈现,之后可以进行分析和存储,以便用户理解和使用。
网页抓取在数据提取方面具有极高的价值,它不仅能够访问大量数据,还能实现自动化,从而允许用户设定网络爬虫在特定时间运行或响应特定事件。 此外,网页抓取还能提供实时更新,并有助于市场研究。

众多企业和公司依赖网页抓取技术来提取数据进行分析。 人力资源、电商、金融、房地产、旅游、社交媒体和研究等领域的公司都利用网页抓取从网站提取相关信息。
甚至像谷歌这样的搜索引擎也使用网页抓取来索引互联网上的网站,从而为用户提供相关的搜索结果。
然而,在进行网页抓取时务必保持谨慎。 尽管抓取公开可访问的数据本身并不违法,但某些网站明确禁止这种行为。 这可能是因为这些网站包含敏感的用户信息,其服务条款明确禁止网页抓取,或是为了保护知识产权。
此外,大规模的网页抓取可能会导致网站服务器过载并增加带宽成本,这也是某些网站不允许抓取的原因。
要检查网站是否允许抓取,请在网站的URL后添加`robots.txt`。 `robots.txt` 文件用于指示网络爬虫可以访问网站的哪些部分。 例如,要检查是否可以抓取谷歌,请访问 `google.com/robots.txt`。
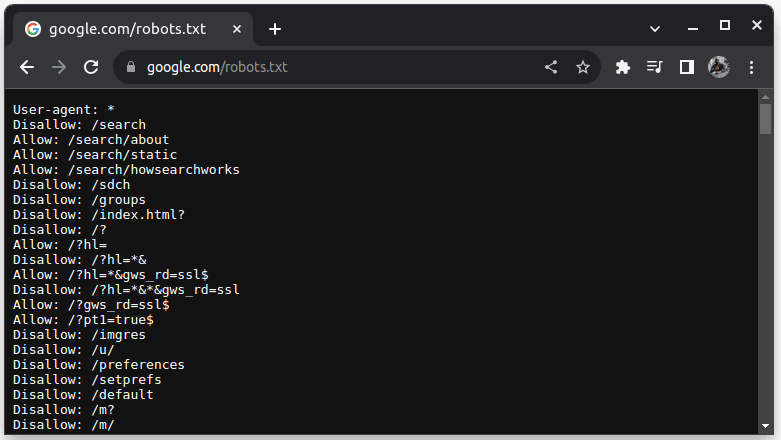
`User-agent: *` 表示所有机器人或软件脚本和爬虫。 `Disallow` 指示机器人不能访问该目录下的任何 URL,例如 `/search`。 `Allow` 指示机器人可以访问的 URL 所在的目录。
LinkedIn 是一个不允许抓取的网站的典型例子。 要检查是否可以抓取 LinkedIn,请访问 `linkedin.com/robots.txt`。
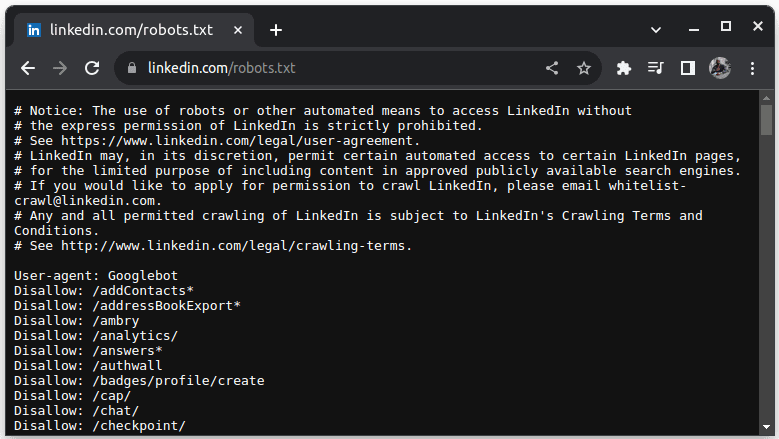
正如您所见,您在未经许可的情况下不能抓取 LinkedIn 的数据。 为了避免任何法律问题,请务必检查网站是否允许抓取。
为什么Java是适合网页抓取的编程语言
虽然可以使用多种编程语言来创建网络爬虫,但Java由于其独特的优势,尤其适合这项工作。 首先,Java拥有庞大的生态系统和活跃的社区,并提供了许多网页抓取库,例如JSoup、WebMagic和HTMLUnit等,这使得编写网页抓取程序变得更加简单。

Java还提供了HTML解析库,简化了从HTML文档中提取数据的过程,并提供了网络库(例如HttpURLConnection)来向不同的网站URL发送请求。
此外,Java对并发和多线程的强大支持也使其非常适合网页抓取,因为它可以并行处理多个请求,从而同时抓取多个页面。 Java的可扩展性使其成为大规模抓取的理想选择,您可以轻松地使用Java编写的网络抓取工具来大规模地抓取网站。
Java的跨平台支持也为用户提供了极大的便利。 您可以使用Java编写一个网络爬虫,并在任何具有兼容Java虚拟机的系统中运行它,无需修改爬虫代码。 这意味着您可以在一种操作系统上开发网页抓取工具,并在不同的操作系统上运行它。
Java还可以与无头浏览器(例如Headless Chrome、HTML Unit、Headless Firefox和PhantomJs)结合使用。 无头浏览器是不显示图形用户界面的浏览器。 它们可以模拟用户交互,对于抓取需要用户交互的网站非常有用。
总而言之,Java是一种非常流行且广泛使用的语言,它具有良好的支持,并且可以轻松地与各种工具(例如数据库和数据处理框架)集成。 这意味着当您抓取数据时,所有必需的工具(包括抓取、处理和存储数据)都可能支持Java。
接下来,让我们看看如何使用Java进行网页抓取。
使用Java进行网页抓取的先决条件
要在网页抓取中使用Java,您需要满足以下先决条件:
1. **Java**:您需要安装Java,最好是使用最新的长期支持(LTS)版本。 如果您尚未安装Java,请参考相关文档了解如何安装。
2. **集成开发环境(IDE)**:您的计算机上需要安装IDE。 本教程将使用IntelliJ IDEA,但您也可以使用您熟悉的任何IDE。
3. **Maven**:这将用于依赖管理和安装网页抓取所需的库。
如果您没有安装Maven,可以通过打开终端并执行以下命令来安装:
sudo apt install maven
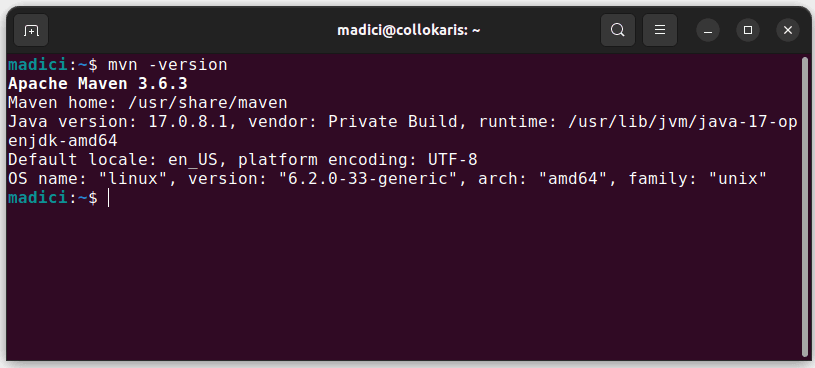
这将从官方存储库安装Maven。您可以通过执行以下命令来验证Maven是否已成功安装:
mvn -version
如果安装成功,您应该看到类似的输出:
配置开发环境
设置您的开发环境:
1. 打开IntelliJ IDEA。 在左侧菜单栏上,单击“项目”,然后选择“新建项目”。
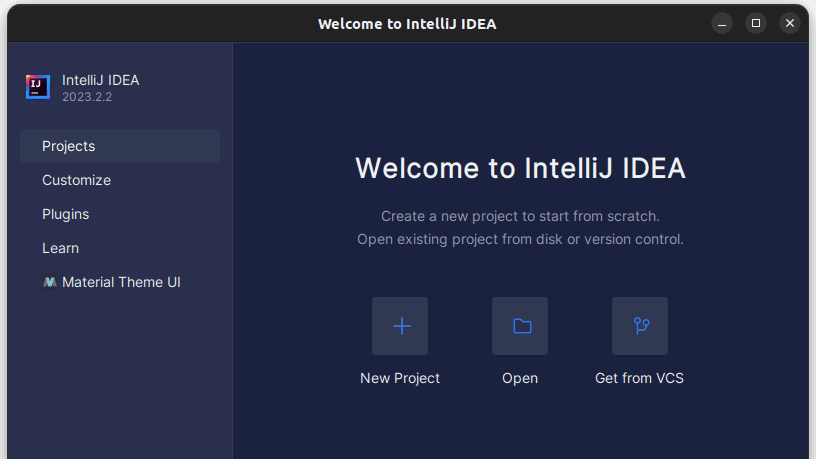
2. 在打开的“新建项目”窗口中,按如下所示填写。 确保语言设置为Java,构建系统设置为Maven。 您可以为项目指定任何您喜欢的名称,并指定项目文件夹的位置。 完成后,单击“创建”。
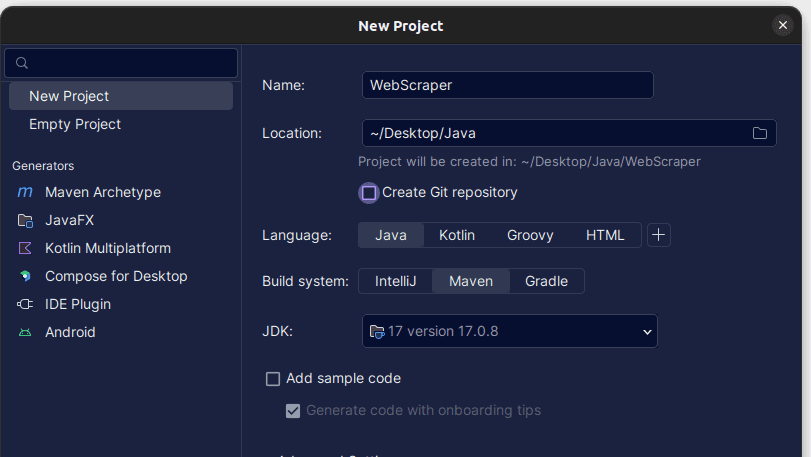
3. 创建项目后,项目中应该有一个`pom.xml` 文件,如下所示。
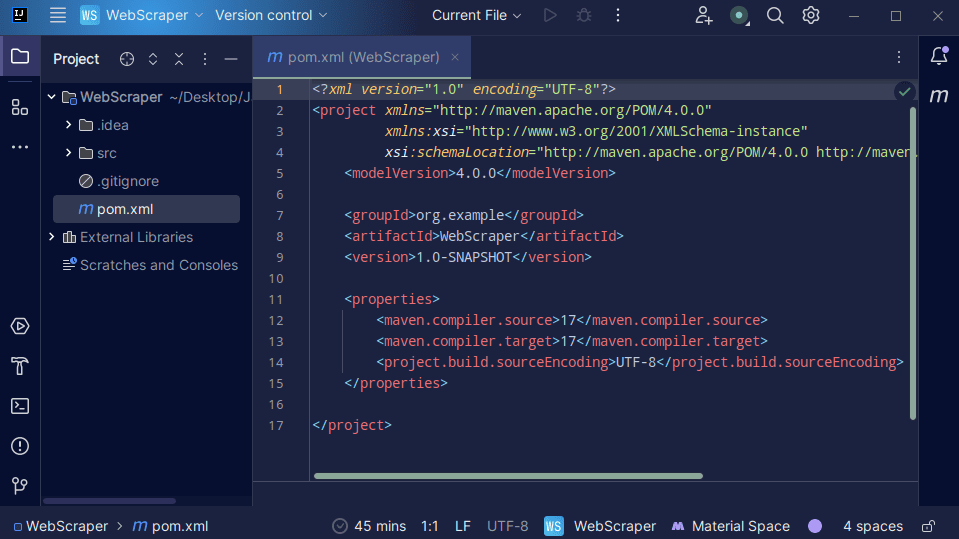
`pom.xml`文件是由Maven创建的,其中包含有关项目的信息以及Maven用于构建项目的配置详细信息。 我们也使用这个文件来声明我们将使用的外部库。
在构建网络爬虫时,我们将使用`jsoup`库。 因此,我们需要将其作为依赖项添加到`pom.xml`文件中,以便Maven可以在我们的项目中使用它。
4. 通过复制以下代码并将其添加到`pom.xml`文件中,在`pom.xml`文件中添加`jsoup`依赖项。
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
结果应如下所示:
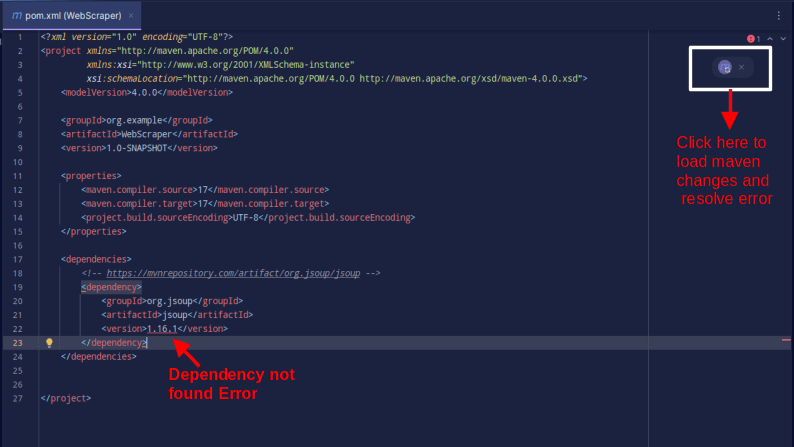
如果您遇到错误提示找不到依赖项,请单击Maven的指示图标来加载更改、加载依赖项并消除错误。
至此,您的开发环境就配置完毕了。
使用Java进行网页抓取
为了进行网页抓取,我们将从抓取这个网站获取数据。这个网站提供了一个沙箱环境,让开发者可以在其中练习网页抓取,而无需担心法律问题。
使用Java抓取网站:
1. 在IntelliJ的左侧菜单栏中,打开`src`目录,然后打开`src`目录内的`main`目录。 `main`目录包含一个名为`java`的目录; 右键单击它并选择“新建”,然后选择“Java类”。
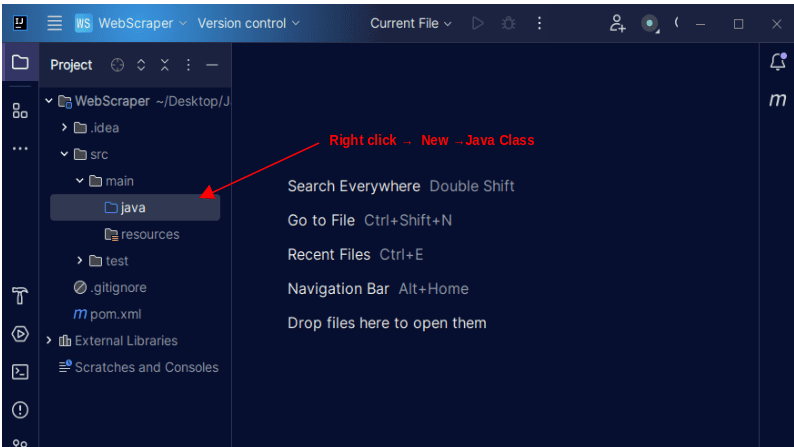
为该类指定您喜欢的任何名称,例如`WebScraper`,然后按Enter键创建一个新的Java类。
打开新创建的文件,其中包含刚刚创建的Java类。
2. 网页抓取涉及从网站获取数据。 因此,我们需要指定要从中抓取数据的URL。 指定URL后,我们需要连接到该URL并发出GET请求以获取页面的HTML内容。
执行此操作的代码如下所示:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
输出:
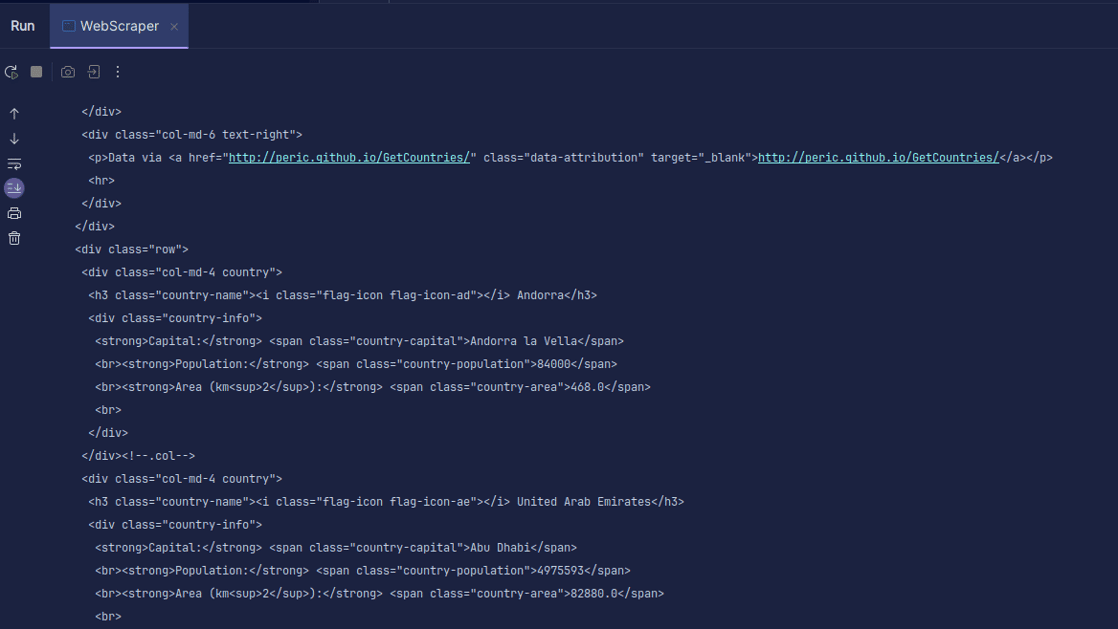
如您所见,返回的是页面的HTML代码,这就是我们打印的内容。 在进行抓取时,您指定的URL可能会出现错误,或者您尝试抓取的资源可能根本不存在。 这就是为什么将代码包裹在`try-catch`语句中非常重要的原因。
代码行:
Document doc = Jsoup.connect(url).get();
用于连接到您想要抓取的URL。 `get()`方法用于发出GET请求并获取页面上的HTML。 然后,将返回的结果存储在名为`doc`的`JSOUP Document`对象中。 将结果存储在`JSOUP Document`中,允许您使用JSOUP API来操作返回的HTML。
3. 访问抓取这个网站并检查页面。在HTML代码中,您应该看到类似如下的结构:
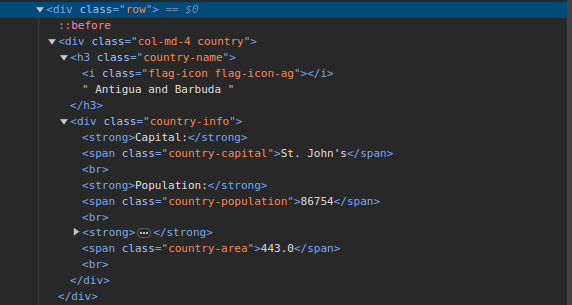
请注意,页面上的所有国家/地区的信息都存储在类似的结构下。有一个类名为`country`的div,其中包含一个h3元素,其`country-name`类包含页面上每个国家/地区的名称。
在主`div`内,还有一个div,其类名为`country-info`,其中包含诸如首都、人口和国家面积等信息。我们可以使用这些类名来选择HTML元素并从中提取信息。
4. 使用以下代码行从页面上的HTML中提取特定的内容:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
我们使用`select()`方法从页面的HTML中选择与我们传入的特定CSS选择器相匹配的元素。 在我们的例子中,我们传入类名。 通过检查页面,我们看到页面上的所有国家/地区信息都存储在具有`country`类别的`div`下。
每个国家/地区都有自己的`div`,其中包含`country`类别,而此`div`包含国家/地区名称、首都和人口等信息。
因此,我们首先使用`.country`类选择页面上的所有国家/地区。 然后,我们将其存储在一个名为`countries`的`Element`类型变量中,该变量的工作方式类似于列表。 接下来,我们使用`for`循环遍历`countries`并提取国家/地区名称、首都和人口,并将找到的内容打印出来。
我们的完整代码如下所示:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
输出:
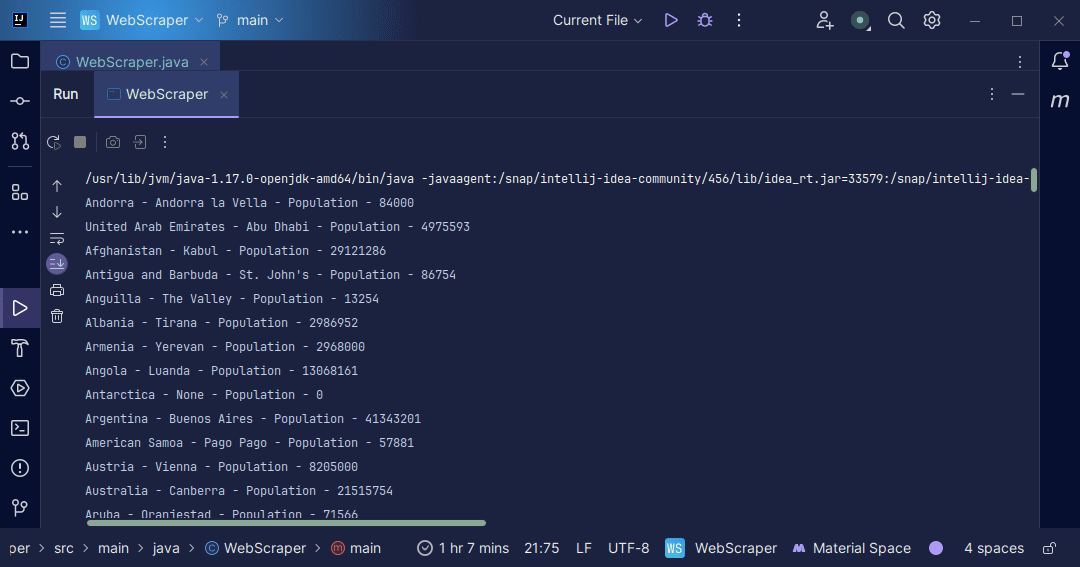
利用从页面返回的信息,我们可以执行多种操作,例如将其打印出来或将其存储在文件中以进行进一步的数据处理。
总结
网页抓取是一种从网站提取非结构化数据、以结构化方式存储数据并处理数据以提取有价值信息的绝佳方法。 但是,在进行网页抓取时要谨慎,因为某些网站不允许抓取。
为了安全起见,请使用提供沙箱环境的网站来练习网页抓取。 否则,请务必检查您要抓取的每个网站的`robots.txt`文件,以了解该网站是否允许抓取。
Java 是一种非常适合编写网页抓取工具的语言,因为它提供了许多库,使得网页抓取更加简单和高效。 对于Java开发者来说,构建网络爬虫可以帮助您进一步提升编程技能。 因此,您可以继续编写自己的网页抓取工具或修改本文中使用的抓取工具来提取不同类型的信息。 祝您编程愉快!
您还可以探索一些流行的基于云的网页抓取解决方案。