核心要点
- 常识是指在不经过过度分析的情况下,理解和应对日常情境的能力。它源于生活经历、观察以及社会文化规范的熏陶。
- 计算机难以掌握常识,因为它们缺乏真实的经验和适应新环境的能力。它们也难以理解人类凭直觉领会的潜规则和假设。
- 研究人员正在探索多种方法,例如构建庞大的知识库、众包常识以及通过模拟环境训练人工智能,以期让计算机获得常识。尽管已取得进展,仍需继续努力。
常识,我们都认为自己拥有。但它究竟是什么?计算机或人工智能系统真的能掌握吗?
何为常识?人类如何习得?
常识是大多数人应具备的感知、理解和判断事物的基本能力。它是我们通过生活体验和观察积累的事实、信息以及经验法则的集合。常识使我们能够高效应对日常情况,无需深入分析。
人类在童年早期就开始形成常识。婴幼儿时期,我们开始学习因果关系,例如哭泣会引来喂食或更换尿布。通过不断重复的经验,我们掌握了关于世界的实用知识。比如,触摸热炉子会被烫伤,所以我们学会避开高温表面。
孩童时期,我们通过尝试、犯错以及观察和与家人互动来不断扩展常识。例如,我们认识到衣服需要定期清洗,不能含着东西说话,以及打翻牛奶会弄得一团糟。当我们违反社会规范和期望时,父母、兄弟姐妹、老师和其他成年人会及时纠正我们。久而久之,这些教训内化为根深蒂固的基本常识。
除了个人经历,常识还受到更广泛的社会和文化规范影响。在一种文化中视为常识的事(例如,进屋脱鞋),在另一种文化中可能并非如此。
随着我们成长,接触更多的人和环境,我们的常识也会相应调整。例如,在小城镇长大的孩子会掌握当地生活的基本常识。而搬到大城市的成年人则需要调整常识以适应新环境。
常识伴随着我们一生中新的体验而不断进化。
为何常识对计算机而言如此具有挑战性?
常识难以编程有多种原因。
一方面,人类通过多年体验世界的累积逐渐掌握常识。我们尝试各种事情,判断哪些有效,哪些无效,并从中吸取教训。而计算机缺乏现实世界的经验,它们只知道人类明确告知的内容。
例如,我问 ChatGPT (GPT 3.5) 这样一个问题:
珍妮经营一家洗衣店。她为顾客洗衣服,然后把它们晾在户外的晾衣绳上。有一天,珍妮洗了五件衬衫,早上晾在晾衣绳上。衬衫用了五个小时才晾干。那么,晾干 30 件衬衫需要多长时间?
以下是它的回答:

另一个问题是,常识具有情境依赖性。如果计算机只被编程了固定的规则,就难以像人类一样直观地适应新环境。
例如,假设你教计算机在外面下雨时该怎么办。这似乎很简单,对吧?但如果不是下雨,而是喷洒器开了呢?或者,如果是在杂货店里,天花板开始漏水怎么办?我们立刻知道如何应对这些变化,但计算机可能会盲目遵循“外面下雨时,进屋”的规则,这就毫无意义了。
还有一些潜规则和假设,人们在无意识中就吸收了。例如,你跟某人站多近才不会感到尴尬?人类凭直觉知道答案,但可能很难解释具体的规则。对计算机来说,仅从数据中获取这些隐含的社会规范尤其具有挑战性。
因此,目前看来,常识仍然是人工智能相对于人类智能的最大弱点之一。这对人来说是自然而然的,但对机器来说却并非如此。
计算机如何学习常识?
在经历了 20 世纪 70 年代和 80 年代的早期乐观之后,研究人员意识到教计算机掌握常识的难度。然而,一些新的方法有望训练人工智能系统获得关于日常生活、物理和社会的基本常识。
一种方法是手动构建庞大的知识库,详细描述关于世界如何运作的事实和规则。Doug Lenat 于 1984 年启动的 Cyc 项目就是此类雄心勃勃的努力。
数十年来,数百名逻辑学家已经将数百万条逻辑公理编码到 Cyc 中。虽然耗时,但最终形成了一个拥有大量现实世界知识的系统。例如,Cyc 可以推断出番茄在技术上是水果,但不应出现在水果沙拉中,因为它了解其烹饪风味特征。
利用 ConceptNet 众包常识
更现代的知识库,比如ConceptNet,采用众包方式来生成常识性断言。其理念是,不必由专家或人工智能来确定世界上所有的基本事实和关系,而是开放给所有人,让大家贡献常识片段。
这种众包方式使这些知识库得以利用互联网上不同人群的集体智慧。通过从人群中收集数以千计的常识片段,ConceptNet 建立了一个规模可观的日常知识库。随着新的贡献者不断添加内容,知识也在不断增长。
通过经验教授常识
另一种有前景的方法是构建详细的模拟世界,人工智能代理可以在其中进行实验,并通过经验来学习物理知识和直觉。
研究人员正在创建充满日常物品的 3D 虚拟环境,这些环境模仿现实世界,例如艾伦研究所构建的数字家庭“AI2 THOR”。在这些空间中,人工智能机器人可以通过各种交互,形成对人类视为理所当然的那些概念的直观理解。
例如,可以给人工智能机器人一个虚拟身体,让它尝试拾起积木、堆叠积木、推倒积木等。通过观察积木的下落和碰撞,机器人可以学习关于固体、重力和物理动力学的基本概念。不需要规则,只需要经验。
机器人还可以尝试一些动作,例如,扔下玻璃物体,并观察它在落地时破碎。或者,它可以通过倒入液体,并观察液体的流动和聚集方式,来了解水的特性。这些实践课程将人工智能的知识根植于感官体验,而不仅仅是数据模式。
事实证明,像预训练强大的大型语言模型这样的数据驱动技术,在掌握常识模式方面也非常有效。像 GPT-3.5 和 GPT-4 这样的人工智能模型在“阅读”大量互联网数据后,可以生成令人印象深刻的类似人类的文本。
尽管它们有时会提出不合理的建议(也称为人工智能幻觉),但统计学习方法使它们能够模仿某些常识。然而,这是否真正构成常识,或者只是巧妙地利用数据偏差,仍然存在争议。
如何测试计算机的常识?
 图片来源:freepik/freepik
图片来源:freepik/freepik
随着人工智能系统承担更复杂的现实任务,评估它们是否具备“常识”至关重要。
物理常识
需要测试的一个领域是物理常识,即关于物体、力和世界基本属性的直觉。
例如,向计算机视觉系统展示一张照片,照片中一本书悬浮在半空中,然后要求它描述这个场景。它会注意到这本漂浮的书有什么不寻常之处吗?或者给人工智能系统展示不寻常的场景,例如“那个人用一条面包切石头”,并检查它是否会将这些场景标记为不可能发生的情况。
艾伦研究所的 AI2 THOR 环境模拟了高塔、溢出的杯子和其他场景,以测试这些物理直觉。
社会常识
人类也有社会常识,即对人们的动机、关系和规范的隐性理解。为了评估人工智能是否掌握社会常识,可以提出一些包含模糊代词或动机的情境,并检查系统是否能做出合理的解释。
例如,我问 ChatGPT,在以下提示中,“it”指的是手提箱还是奖杯:
奖杯放不进手提箱,因为它太小了。
它没有通过测试;而人们显然知道我指的是手提箱。
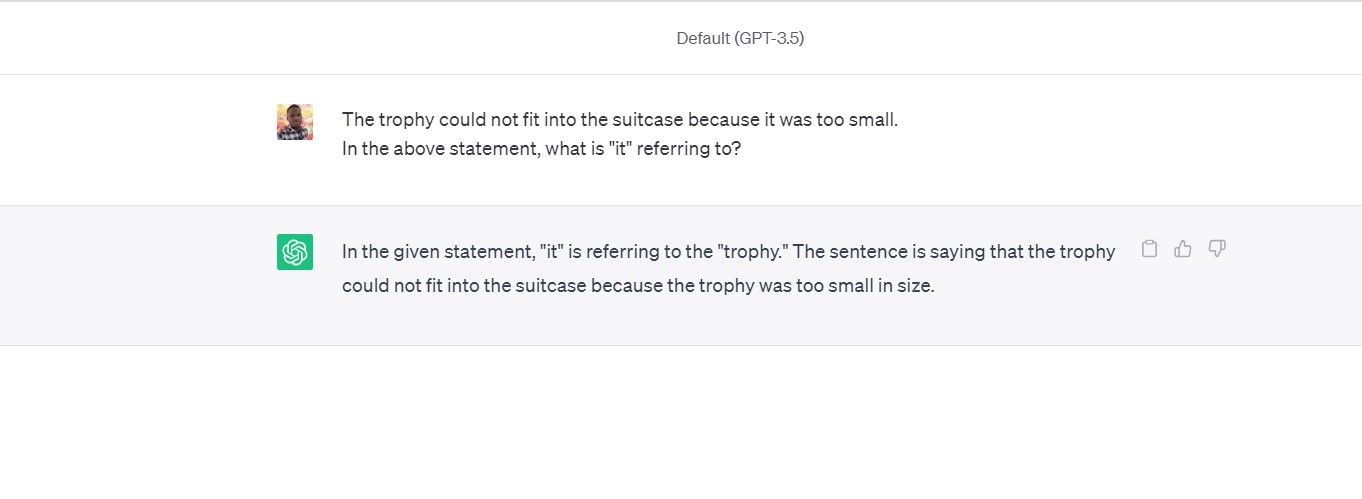
这种测试被称为 Winograd Schema Challenge,专门针对社会常识。
安全与伦理
测试人工智能系统是否已经学会不安全或不道德的模式至关重要。要分析人工智能在做判断时,是否会表现出基于性别、种族或其他属性的有害偏见。
检查它是否能做出合理的道德区分。杀死一头熊去救一个孩子可能被认为是合理的,但为了同一目的引爆核弹则不然。要标记出任何明显不道德行为的建议。
真实世界表现
通过观察人工智能系统在真实环境中的表现来评估其常识。例如,自动驾驶汽车能否正确识别物体和行人并做出反应?机器人能否在不同的家庭环境中移动,而不损坏贵重物品或伤害宠物?
现实世界的测试揭示了在有限的实验室条件下可能不会出现的常识漏洞。
常识人工智能已取得进展,但仍需努力
一些专家认为,如果不发展出像我们一样的大脑结构和身体,人工智能可能永远无法达到人类的常识水平。另一方面,数字思维不受人类的偏见和思维捷径的限制,因此理论上它们可能超越我们!不过,我们可能还不需要担心超级人工智能。
在短期内,最好的选择是将已习得的常识与一些传统的编程方法相结合的人工智能。这样,就有希望避免诸如把乌龟误认为步枪之类的愚蠢错误。
我们尚未完全实现这一目标,但常识不再是人工智能的暗物质,进步正在发生!尽管如此,在一段时间内应用这些技术仍然需要大量的人类常识。