命名實體識別 (NER) 提供了一種強大的方法,能夠深入理解文本內容,並針對各種應用,識別出文本中特定的實體或標籤。
從分類人名到標示日期、組織、地點等,NER 為更深入地理解語言開闢了道路。
許多組織每天都在處理大量的數據,這些數據的形式多樣,包括內容、個人資訊、客戶反饋以及產品詳情等等。
當您需要即時獲取資訊時,往往需要執行搜尋操作,但這可能耗費大量的時間、精力及資源,特別是在處理龐大數據集的情況下。
為了提供組織有效的搜尋方案和快速查找所需數據的方法,NER 成為一個絕佳的選擇。
在本文中,我將詳細探討 NER 的概念、其背後的數學原理、不同的應用場景,以及其他重要的相關知識。
讓我們開始吧!
什麼是命名實體識別?
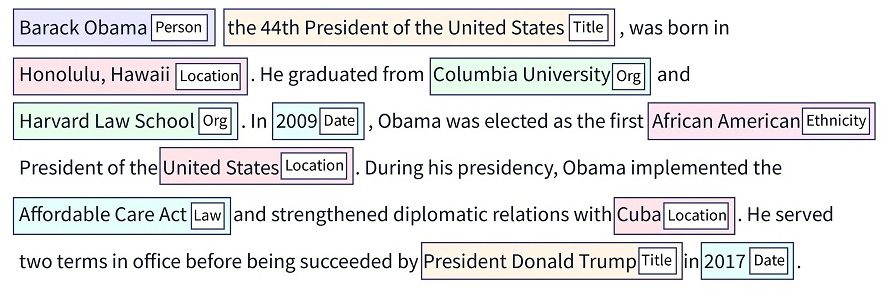
命名實體識別 (NER) 是一種自然語言處理 (NLP) 技術,專門用於識別並分類非結構化文本數據中的實體。
這些實體涵蓋了廣泛的資訊,例如組織、地點、個人姓名、數值、日期等。透過 NER,機器能夠從文本中提取這些實體,使其成為跨多個產業的翻譯、問答等應用的有力工具。
 來源: Scaler
來源: Scaler
因此,NER 的目標是從非結構化的文本中定位不同的實體,並將其分類為預先定義的組別,例如組織、醫療代碼、數量、人名、百分比、貨幣值、時間表達等等。
讓我們通過一個例子來理解一下:
[威廉] 在 [2023年] 購買了 [Z1 公司] 的房產。 其中,方括號標示的部分就是 NER 所識別的實體。 它們被分類如下:
- 威廉 – 人名
- Z1 公司 – 組織
- 2023年 – 時間
NER 廣泛應用於人工智慧的許多領域,包括深度學習、機器學習 (ML) 和神經網路。 它是情感分析工具、搜索引擎和聊天機器人等 NLP 系統的關鍵組成部分。 此外,它還可用於金融、客戶支持、高等教育、醫療保健、人力資源和社群媒體分析等領域。
簡而言之,NER 能夠從非結構化文本中識別、分類並提取重要的資訊,無需任何人工分析。 它能從大量數據集中快速提取關鍵資訊。
此外,NER 還可以為您的組織提供關於產品、市場趨勢、客戶以及競爭對手的重要見解。 例如,醫療機構可以利用 NER 從病患記錄中提取關鍵醫療數據。 許多公司則使用 NER 來監測其名稱是否在出版物中被提及。
關鍵概念:NER

理解 NER 的基本概念至關重要。 接下來,我們將討論一些與 NER 相關的關鍵術語,以便您更好地熟悉它們。
- 命名實體:指代特定地點、組織、個人或其他實體的任何單詞或詞組。
- 語料庫:用於分析語言和訓練 NER 模型的文本集合。
- 詞性標註:根據單詞在句子中的語法角色(例如,形容詞、動詞、名詞)來標記文本的過程。
- 分塊:根據語法結構和詞性將單詞組合成有意義的短語的過程。
- 訓練和測試數據:使用標記數據來訓練模型,並使用另一組數據來評估模型性能的過程。
NER 在 NLP 中的使用

NER 在 NLP 中有許多應用,例如情感分析、推薦系統、問答系統、資訊提取等。
- 情感分析:NER 用於檢測句子或段落中針對特定命名實體(如產品或服務)所表達的情感。 這些數據可用於改善客戶體驗並識別改進領域。
- 推薦系統:NER 用於根據用戶在網路互動或搜尋查詢中提及的命名實體來識別他們的偏好和興趣。 此資訊用於通過提供個人化推薦來提升用戶體驗。
- 問答系統:NER 用於從文本中檢測特定實體,並進一步用於回答查詢或特定問題。 這在虛擬助理和聊天機器人中很常見。
- 資訊提取:NER 用於從大量的非結構化文本中提取重要資訊,包括社群媒體貼文、線上評論、新聞文章等。 這些數據可用於產生有價值的見解並做出數據驅動的決策。
數學概念:NER
NER 過程涉及多種數學概念,例如機器學習、深度學習、機率論等。 以下是一些相關的數學技巧:
- 隱馬可夫模型:隱馬可夫模型 (HMM) 是一種用於排序分類任務(如 NER)的統計方法。 它將文本中的單詞序列表示為不同的狀態,每個狀態代表一個特定的命名實體。 通過分析機率,您可以從文本中識別出命名實體。
- 深度學習:神經網路等深度學習技術廣泛應用於 NER 任務。 這使得我們能夠高效且準確地識別和分類命名實體。
- 條件隨機場:條件隨機場 (CRF) 屬於圖形模型,用於序列標記任務。 它們為包含單詞序列的每個標籤提供條件機率建模,有助於識別文本中的命名實體。
NER 如何運作?
 來源: 美國化學學會出版物
來源: 美國化學學會出版物
命名實體識別 (NER) 的主要作用是從文本中提取資訊。 其運作過程可分為幾個關鍵步驟:
#1. 預處理文本
第一步,NER 涉及準備用於分析的文本資訊。 這通常包括分詞等任務。 在這個階段,文本會先被分割成獨立的詞語,然後 NER 才會開始識別實體。
例如,「比爾·蓋茨創立了微軟」可以被分成不同的詞語,如「比爾」、「蓋茨」、「創立」和「微軟」。
#2. 識別實體
可以使用統計方法或語言規則來檢測潛在的命名實體。 這個步驟涉及模式識別,例如特定格式(日期)或名稱大寫(「比爾蓋茨」)。 在預處理完成後,NER 演算法會掃描文本,以識別與實體對應的單詞序列。
#3. 分類實體
在 NER 識別出實體後,會將這些實體分類到不同的類型、類別或組別。 常見的類別包括組織、日期、地點、人員等。 這是通過基於標記數據訓練的機器學習模型來實現的。
例如,「比爾蓋茨」將被識別為「人」,而「微軟」將被識別為「組織」。
#4. 情境分析
NER 不僅僅停留在實體的識別和分類,它還會考慮上下文以提高準確性。 這個步驟會分析實體出現的上下文,從而提供更精確的分類。
例如,「比爾·蓋茨創立了微軟」。在這裡,上下文使系統能夠將「比爾」識別為人名,而不是付款單據。
#5. 後期處理
經過初步識別和分類後,需要進行後期處理以完善最終結果。 這包括解決歧義、利用知識庫、合併多個詞語組成的實體等,以提高實體資料的準確性。
NER 的出色之處在於它能夠解釋和理解非結構化文本,其中包含您業務所需的寶貴數據。 它可以從新聞文章、網頁、研究論文、社群媒體貼文等各種來源接收數據。
通過識別和分類命名實體,NER 為文本內容增添了額外的意義和結構。
NER 的方法

以下是一些最常用的方法:
#1. 基於監督式機器學習的方法
這種方法使用機器學習模型,這些模型是基於人類預先使用命名實體類別標記的文本進行訓練的。
此方法利用包括最大熵和條件隨機場在內的演算法,來建立複雜的統計語言模型。 它可以有效地處理語言含義和其他複雜問題,但需要大量的訓練數據才能有效運作。
#2. 基於規則的系統
這種方法利用不同的規則來提取資訊。 這些規則可能包括標題或大寫字母,例如「張先生」。 在這種方法中,需要大量的人為干預來提供輸入、監控和調整規則。 此方法可能會遺漏訓練註解中未包含的文本變化,因此無法像機器學習模型一樣處理複雜的語境。
#3. 基於字典的系統
在此方法中,使用包含大量同義詞和詞彙集合的字典來識別和交叉檢查命名實體。 然而,此方法在對具有各種拼寫變化的命名實體進行分類時,可能會遇到困難。
此外,還有許多其他新興的 NER 方法。 讓我們也來討論一下它們:
#4. 無監督式機器學習系統
這些機器學習系統使用未針對文本數據進行預先訓練的機器學習模型。 與監督式模型相比,無監督式模型通常能夠執行更複雜的任務。
#5. 自舉系統
自舉系統,也稱為自監督系統,根據語法特徵對命名實體進行分類,包括詞性標籤、大寫和其他預先訓練的類別。
然後,人類通過將系統的預測標記為錯誤或正確,並將正確的預測添加到新的訓練集中,來調整自舉系統。
#6. 神經網路系統
它通過使用雙向架構的學習模型(例如,來自 Transformer 的雙向編碼器表示)、神經網路和編碼技術來建構命名實體識別模型。 這種方法可以最大程度地減少人為干預。
#7. 統計系統
這種方法使用經過文本關係和模式訓練的機率模型。 它有助於根據新的文本數據來輕鬆預測命名實體。
#8. 語義角色標記系統
此系統使用語義學習技術來預處理命名實體識別模型,以了解類別和上下文之間的關係。
#9. 混合系統
這種方法是一種有趣的方法,它以組合方式使用多種方法的各個方面。
NER 的好處
NER 模型提供了許多好處。
- NER 可自動執行大量數據的數據提取過程。
- 它在各個行業中廣泛使用,從非結構化文本中提取關鍵資訊。
- 它可以節省您和您的員工執行數據提取任務的時間。
- 它可以提高 NLP 流程和任務的準確性。
- 它通過託管客製化的 NER 模型來確保數據安全,無需與第三方供應商共享敏感資訊。
- 隨著領域的發展,它可以適應新的實體類型和術語。
NER 的挑戰
- 歧義:文本中使用的許多詞語可能具有多重含義。 例如,「亞馬遜」一詞可以指一家公司、一條河流或一片森林。 這使得實體識別變得有點棘手,需要根據具體的語境來區分。
- 上下文依賴性:源自周圍上下文的單詞可能具有不同的含義。 例如,「蘋果」在科技文本中指的是一家公司,而在日常生活中,它指的是水果。 因此,要準確識別實體並不容易。
- 數據稀疏性:對於基於機器學習的 NER 方法,標記數據的可用性至關重要。 然而,獲取此類數據,特別是針對專業領域或不太常見的語言,可能具有挑戰性。
- 語言變異:人類語言根據方言、地區差異和俚語而有所不同,這使得提取不同語言的文本成為一個難題。
- 模型泛化:NER 模型可能擅長對特定領域中的實體進行分類,但在另一個領域中可能會出現混淆。 因此,NER 模型在不同領域的表現可能會有所差異。
如果將先進的演算法、語言專業知識和高質量的數據結合起來,這些挑戰是可以克服的。 由於 NER 不斷發展,研發團隊必須不斷改進各種技術以應對這些挑戰。
NER 的用例
#1. 內容分類

出版商和新聞機構會產生大量的線上內容。 因此,有效地管理這些內容對於充分利用文章或新聞至關重要。
命名實體識別能夠自動掃描整個內容,並提取內容中使用的組織、地點和人名等數據。 了解每篇文章的相關標籤,可以幫助您在定義的層次結構中對文章進行分類,從而改善內容交付。
#2. 搜尋演算法
假設您的線上出版商擁有一個包含數百萬篇文章的內部搜尋演算法。 對於每個搜尋查詢,您的內部搜尋演算法最終都需要收集所有這些文章中的所有單詞。 這是一個非常耗時的過程。
現在,如果您將 NER 應用於線上出版商,它可以輕鬆地從所有文章中提取基本實體並單獨儲存它們,從而加速您的搜尋過程。
#3. 內容推薦
自動化推薦過程是 NER 的主要用例之一。 推薦系統引導用戶發現新的想法和內容。
Netflix 就是一個很好的例子。 實踐證明,構建高效的推薦系統可以幫助您增加活動的參與度和吸引力。
對於新聞出版商來說,NER 可以有效地推薦類似的文章。 這可以通過從特定文章收集標籤,並推薦具有類似實體的其他內容來實現。
#4. 客戶支援

對於每個組織來說,客戶支援都是非常重要的一環。 因此,有多種方法可以使客戶反饋處理功能順利進行,而 NER 就是其中之一。 讓我們通過一個例子來理解這一點。
假設一位顧客給出反饋:「聖地牙哥阿迪達斯專賣店的工作人員缺乏運動鞋的詳細資訊」。 在這裡,NER 會提取標籤「聖地牙哥」(地點)和「運動鞋」(產品)。
因此,NER 用於對每個投訴進行分類,並將其發送到組織內的相應部門來處理問題。 您可以建立一個由分類到各個部門的反饋組成的數據庫,並分析每個反饋。
#5. 研究報告
線上出版物或期刊網站擁有大量的學術文章和研究論文。 您可能會找到數百篇主題相似但略有修改的論文。 因此,以結構化的方式組織所有這些數據可能是一項複雜的任務。
為了跳過漫長的過程,您可以根據相關標籤來分開這些論文。
例如,關於機器學習的論文可能有數千篇。 如果您想找到提到使用捲積神經網路 (CNN) 的文章,您需要在文章中添加實體標籤,以便快速找到所需內容。
結論
自然語言處理 (NLP) 技術,尤其是命名實體識別 (NER),有助於識別非結構化文本中的命名實體,並將其分類為預先定義的組別,例如地點、人名、產品等。
NER 的主要目標是從非結構化文本中提取結構化資訊,並以可讀的格式呈現出來。 它涉及各種模型和流程,為專業人士和企業帶來諸多益處。 除了 NLP 之外,它還應用於各種不同的領域。
我希望您能理解以上關於這項技術的解釋,並將其應用於您的業務中,以獲取相關且有價值的資訊。
您還可以探索一些最佳的 NLP 課程,以深入學習自然語言處理。